

Редакция май, 2025
Аннотация
apt-get и её графическая оболочка synaptic позволяют пользователям легко обновлять свои системы и быть в курсе актуальных новостей мира свободных программ.
Содержание
SCDWriter.exe;
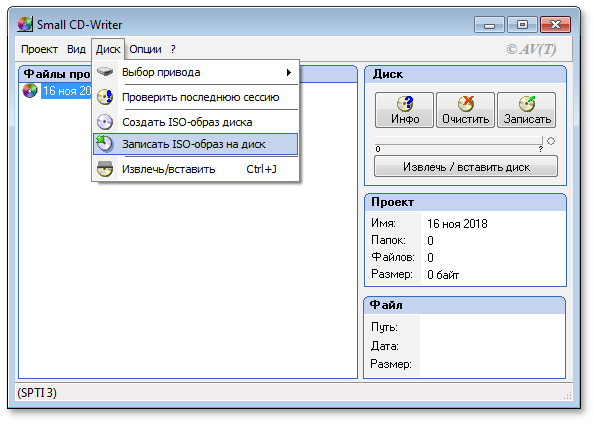
Предупреждение




Предупреждение
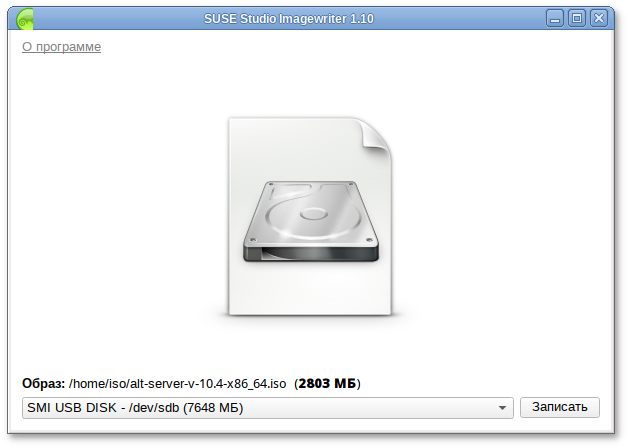
Предупреждение
Предупреждение
dd:
#где <файл-образа.iso> — образ диска ISO, аddoflag=direct if=<файл-образа.iso> of=/dev/sdX bs=1M status=progress;sync
/dev/sdX — устройство, соответствующее flash-диску.
#где <файл-образа.iso> — образ диска ISO, аpv<файл-образа.iso> | dd oflag=direct of=/dev/sdX bs=1M;sync
/dev/sdX — устройство, соответствующее flash-диску.
lsblk или (если такой команды нет) blkid.
$ lsblk | grep disk
sda 8:0 0 931,5G 0 disk
sdb 8:16 0 931,5G 0 disk
sdc 8:32 1 7,4G 0 disk
flash-диск имеет имя устройства sdc.
# dd oflag=direct if=/iso/alt-server-v-10.4-x86_64.iso of=/dev/sdc bs=1M status=progress; sync
# pv /iso/alt-server-v-10.4-x86_64.iso | dd oflag=direct of=/dev/sdc bs=1M;sync
dd: warning: partial read (524288 bytes); suggest iflag=fullblock
3GiB 0:10:28 [4,61MiB/s] [===================================> ] 72% ETA 0:04:07
Предупреждение
sudo dd if=alt-server-v-10.4-x86_64.isoof=/dev/rdiskX bs=10Msync
alt-server-v-10.4-x86_64.iso — образ диска ISO, а /dev/rdiskX — flash-диск.
diskutil list
Предупреждение
$ du -b alt-server-v-10.4-x86_64.iso | cut -f1
3107182592
$ md5sum alt-server-v-10.4-x86_64.iso
99308d15f0b5886f96ea4e791341d2a1 alt-server-v-10.4-x86_64.iso
# head -c 3107182592 /dev/sdd | md5sum
99308d15f0b5886f96ea4e791341d2a1
где размер после -c — вывод в п.1, а /dev/sdd — устройство DVD или USB Flash, на которое производилась запись.
Предупреждение
Примечание
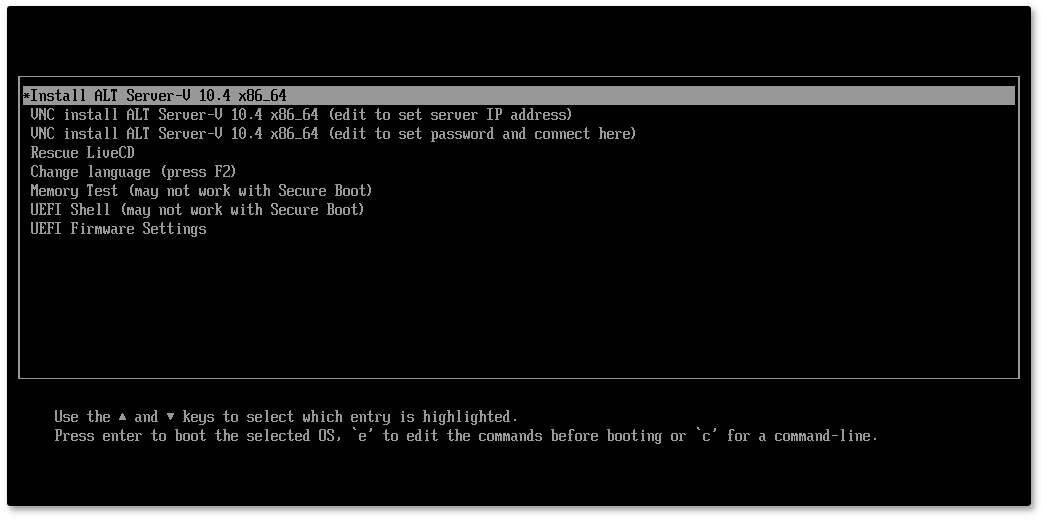
vncviewer --listen):


[root@localhost /]#
Примечание

Примечание
Примечание
Примечание
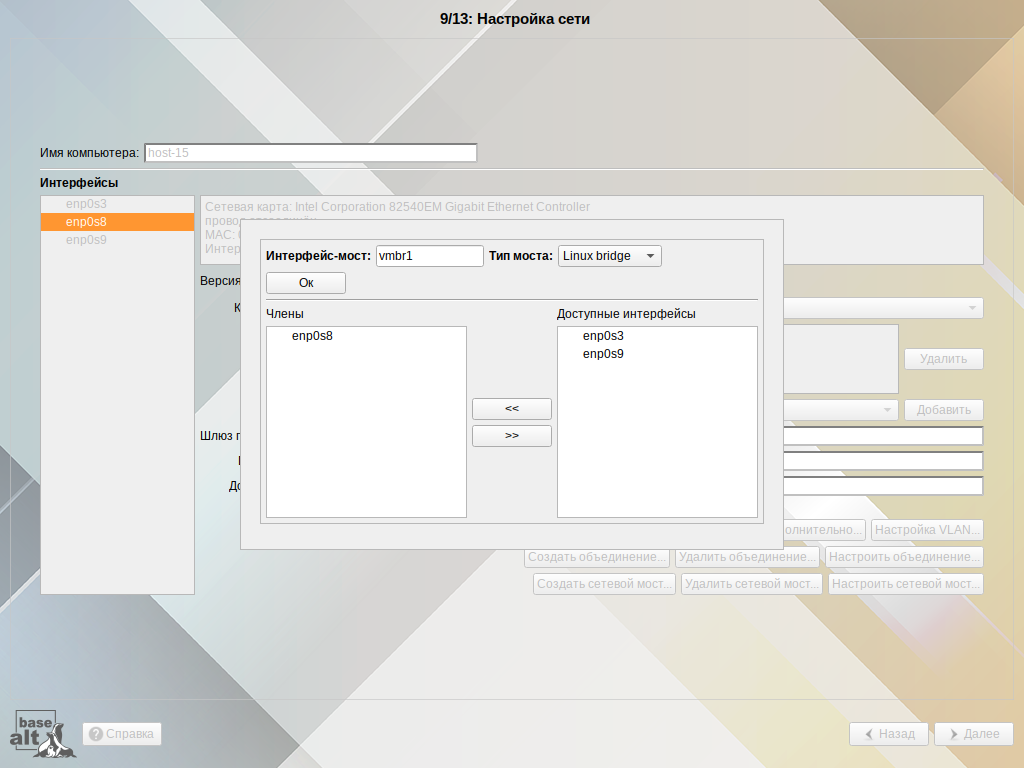
 позволяет показать/скрыть панель со списком шагов установки:
позволяет показать/скрыть панель со списком шагов установки:





Примечание

/var;

/var.



Примечание

/home) или с другими операционными системами. С другой стороны, отформатировать можно любой раздел, который вы хотите «очистить» (удалить все данные).
Предупреждение
/boot/efi, в которую нужно смонтировать vfat раздел с загрузочными записями. Если такого раздела нет, то его надо создать вручную. При разбивке жёсткого диска в автоматическом режиме такой раздел создаёт сам установщик. Особенности разбиения диска в UEFI-режиме:
/boot/efi);
Примечание
Важно
Важно


Примечание

Примечание




Примечание
/boot/efi).
Важно
Важно
Примечание



Примечание


Предупреждение
/ и /home создаются подтома с именами @ и @home. Это означает, что для монтирования подтомов необходимы определенные параметры вместо корня системы BtrFS по умолчанию:
/ с помощью опции subvol=@;
/home с помощью параметра монтирования subvol=@home.


Примечание






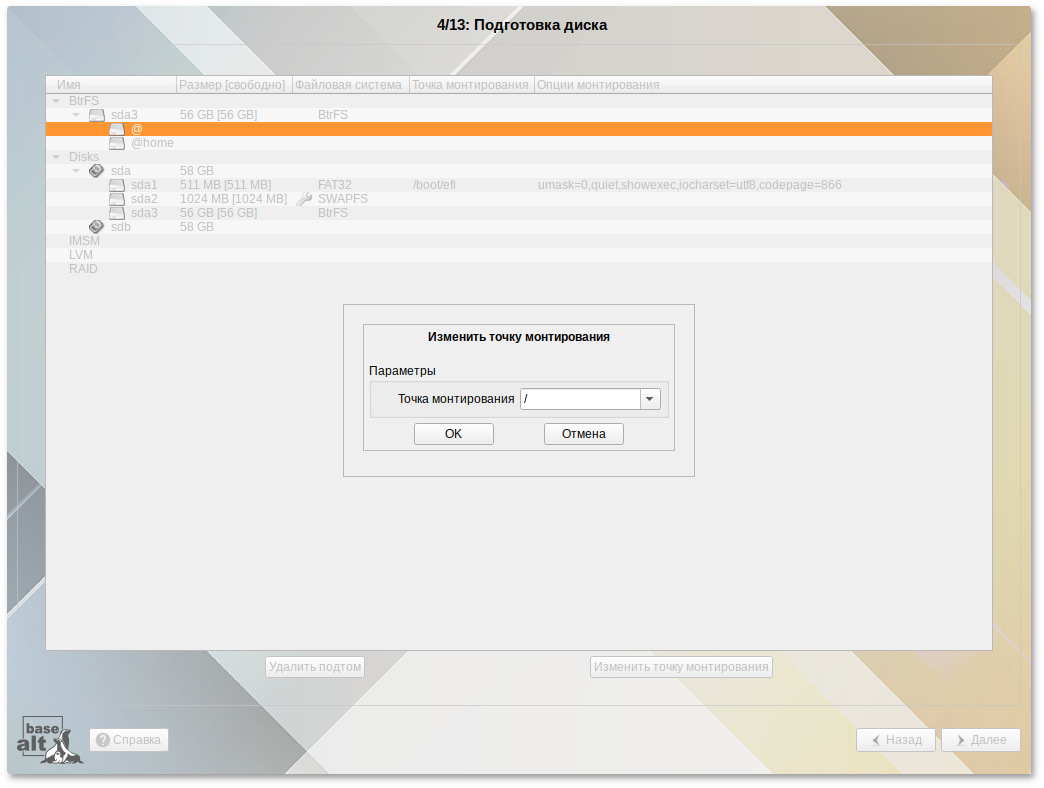






/etc/fstab).

/root/.install-log, после чего из неё будут удалены все загрузочные записи, что приведёт к восстановлению полностью заполненной NVRAM и гарантирует загрузку вновь установленной ОС;
Примечание


Примечание

Важно
Важно
Примечание



Важно

Примечание



Примечание
Примечание


Примечание


Примечание

Важно

Примечание

/home, то во время загрузки системы будет необходимо ввести пароль для этого раздела, иначе вы не сможете получить доступ в систему под своим именем пользователя.
#apt-get update#apt-get dist-upgrade#update-kernel#apt-get clean#reboot
Примечание
$ su -
или зарегистрировавшись в системе (например, на второй консоли Ctrl+Alt+F2) под именем root. Про режим суперпользователя можно почитать в главе Режим суперпользователя.
Примечание
Важно
Важно

nomodeset — не использовать modeset-драйверы для видеокарты;
vga=normal — отключить графический экран загрузки установщика;
xdriver=vesa — явно использовать видеодрайвер vesa. Данным параметром можно явно указать нужный вариант драйвера;
acpi=off noapic — отключение ACPI (управление питанием), если система не поддерживает ACPI полностью.
apm=off acpi=off mce=off barrier=off vga=normal). В безопасном режиме отключаются все параметры ядра, которые могут вызвать проблемы при загрузке. В этом режиме установка будет произведена без поддержки APIC. Возможно, у вас какое-то новое или нестандартное оборудование, но может оказаться, что оно отлично настраивается со старыми драйверами.
[root@localhost /]#. Начиная с этого момента, система готова к вводу команд.
fixmbr без параметров. Программа попытается переустановить загрузчик в автоматическом режиме.

Важно

/home, то для того, чтобы войти в систему под своим именем пользователя, вам потребуется ввести пароль этого раздела и затем нажать Enter.
Важно

Примечание


Примечание
Содержание
Таблица 26.1. Минимальные требования к серверу управления
|
Ресурс
|
Минимальное значение
|
|---|---|
|
Оперативная память
|
2 ГБ
|
|
CPU
|
1 CPU (2 ядра)
|
|
Диск
|
100 ГБ
|
|
Сеть
|
2 интерфейса
|
Примечание
/var/lib/one/.one/one_auth будет создан со случайно сгенерированным паролем. Необходимо поменять этот пароль перед запуском OpenNebula.
# passwd oneadmin
/var/lib/one/.one/one_auth. Он должен содержать следующее: oneadmin:<пароль>. Например:
$ echo "oneadmin:mypassword" > ~/.one/one_auth
Примечание
# mysql_secure_installation
$mysql -u root -pEnter password: MariaDB >GRANT ALL PRIVILEGES ON opennebula.* TO 'oneadmin' IDENTIFIED BY '<thepassword>';Query OK, 0 rows affected (0.003 sec) MariaDB >SET GLOBAL TRANSACTION ISOLATION LEVEL READ COMMITTED;Query OK, 0 rows affected (0.001 sec) MariaDB >quit
/etc/one/oned.conf:
#DB = [ BACKEND = "sqlite" ]
# TIMEOUT = 2500 ]
# Sample configuration for MySQL
DB = [ BACKEND = "mysql",
SERVER = "localhost",
PORT = 0,
USER = "oneadmin",
PASSWD = "<thepassword>",
DB_NAME = "opennebula",
CONNECTIONS = 25,
COMPARE_BINARY = "no" ]
#systemctl enable --now opennebula#systemctl enable --now opennebula-sunstone
$ oneuser show
USER 0 INFORMATION
ID : 0
NAME : oneadmin
GROUP : oneadmin
PASSWORD : 3bc15c8aae3e4124dd409035f32ea2fd6835efc9
AUTH_DRIVER : core
ENABLED : Yes
USER TEMPLATE
TOKEN_PASSWORD="ec21d27e2fe4f9ed08a396cbd47b08b8e0a4ca3c"
VMS USAGE & QUOTAS
VMS USAGE & QUOTAS - RUNNING
DATASTORE USAGE & QUOTAS
NETWORK USAGE & QUOTAS
IMAGE USAGE & QUOTAS
http://<внешний адрес>:9869. Если все в порядке, будет предложена страница входа.
/var/lib/one/.one/one_auth):


Примечание

/var/lib/one/.ssh/authorized_keys на всех машинах.
$ ssh-keyscan <сервер_управления> <узел1> <узел2> <узел3> ... >> /var/lib/one/.ssh/known_hosts
Примечание
ssh-keyscan необходимо выполнить, как для имён, так и для IP-адресов узлов/сервера управления:
$ ssh-keyscan <IP-узел1> <hostname-узел1> ... >> /var/lib/one/.ssh/known_hosts
Например:
$ ssh-keyscan 192.168.0.185 server 192.168.0.190 host-01 >> /var/lib/one/.ssh/known_hosts
/var/lib/one/.ssh на все узлы. Самый простой способ — установить временный пароль для oneadmin на всех узлах и скопировать каталог с сервера управления:
$scp -rp /var/lib/one/.ssh <узел1>:/var/lib/one/$scp -rp /var/lib/one/.ssh <узел2>:/var/lib/one/$scp -rp /var/lib/one/.ssh <узел3>:/var/lib/one/...
# от сервера управления к самому серверу управления ssh <сервер_управления> exit # от сервера управления к узлу1, обратно на сервер управления и к другим узлам ssh <узел1> ssh <сервер_управления> exit ssh <узел2> exit ssh <узел3> exit exitИ так далее для всех узлов.
/var/lib/one/.ssh/config на сервере управления и добавления параметра ForwardAgent к узлам гипервизора для пересылки ключа:
$ cat /var/lib/one/.ssh/config
Host host-01
User oneadmin
ForwardAgent yes
Host host-02
User oneadmin
ForwardAgent yes
Примечание

Примечание
# apt-get install opennebula-node-kvm
И добавить службу libvirtd в автозапуск и запустить её:
# systemctl enable --now libvirtd
# passwd oneadmin
и настроить доступ по SSH (см. раздел Ключи для доступа по SSH).
Важно

Примечание
# apt-get install opennebula-node-lxc
# systemctl enable --now lxc
# passwd oneadmin
и настроить доступ по SSH (см. раздел Ключи для доступа по SSH).
Примечание




onehost — это инструмент управления узлами в OpenNebula. Описание всех доступных опций утилиты onehost можно получить, выполнив команду:
$ man onehost
$ onehost create host-01 --im kvm --vm kvm
ID: 0
$ onehost create host-02 --im lxс --vm lxс
ID: 1
$ onehost list
ID NAME CLUSTER TVM ALLOCATED_CPU ALLOCATED_MEM STAT
1 host-02 default 0 0 / 100 (0%) 0K / 945M (0%) on
0 host-01 default 0 0 / 10000 (0%) 0K / 7.6G (0%) on
Примечание
/var/log/one/oned.log.
$ onehost delete 1
или имени:
$ onehost delete host-02
$onehost disable host-01// деактивировать узел $onehost enable host-01// активировать узел $onehost offline host-01// полностью выключить узел
Примечание
onehost disable и onehost offline не меняют состояние уже работающих на узле ВМ. Если необходимо автоматически перенести работающие ВМ, следует использовать команду onehost flush.
onehost flush перенесет все активные ВМ с указанного узла на другой сервер с достаточной емкостью. При этом указанный узел будет отключен. Эта команда полезна для очистки узла от активных ВМ. Процесс миграции можно выполнить с помощью переноса (resched) или действия восстановления, удаления и воссоздания. Это поведение можно настроить в /etc/one/cli/onehost.yaml, установив в поле default_actions\flush значение delete-recreate или resched. Например:
:default_actions: - :flush: resched
$ onehost show host-01
onevnet — инструмент управления виртуальными сетями в OpenNebula. Описание всех доступных опций утилиты onevnet можно получить, выполнив команду:
$ man onevnet
$ onevnet list
ID USER GROUP NAME CLUSTERS BRIDGE LEASES
2 oneadmin oneadmin VirtNetwork 0 onebr2 0
0 oneadmin oneadmin LAN 0 vmbr0 1
Вывести информацию о сети:
$ onevnet show 0

Таблица 30.1. Параметры виртуальной сети в режиме Bridged
|
Параметр
|
Значение
|
Обязательный
|
|---|---|---|
|
NAME
|
Имя виртуальной сети
|
Да
|
|
VN_MAD
|
Режим:
|
Да
|
|
BRIDGE
|
Имя сетевого моста в узлах виртуализации
|
Нет
|
|
PHYDEV
|
Имя физического сетевого устройства (на узле виртуализации), которое будет подключено к мосту
|
Нет
|
|
AR
|
Диапазон адресов, доступных в виртуальной сети
|
Нет
|
net-bridged.conf со следующим содержимым:
NAME = "VirtNetwork"
VN_MAD = "bridge"
BRIDGE = "vmbr0"
PHYDEV = "enp3s0"
AR=[
TYPE = "IP4",
IP = "192.168.0.140",
SIZE = "5"
]
$ onevnet create net-bridged.conf
ID: 1



Примечание
/etc/one/oned.conf:
VLAN_IDS = [
START = "2",
RESERVED = "0, 1, 4095"
]
Драйвер сначала попытается выделить VLAN_IDS[START] + VNET_ID где
Таблица 30.2. Параметры виртуальной сети в режиме 802.1Q
|
Параметр
|
Значение
|
Обязательный
|
|---|---|---|
|
NAME
|
Имя виртуальной сети
|
Да
|
|
VN_MAD
|
802.1Q
|
Да
|
|
BRIDGE
|
Имя сетевого моста (по умолчанию onebr<net_id> или onebr.<vlan_id>)
|
Нет
|
|
PHYDEV
|
Имя физического сетевого устройства (на узле виртуализации), которое будет подключено к мосту
|
Да
|
|
VLAN_ID
|
ID сети VLAN (если не указан и AUTOMATIC_VLAN_ID = "YES", то идентификатор будет сгенерирован)
|
Да (если AUTOMATIC_VLAN_ID = "NO")
|
|
AUTOMATIC_VLAN_ID
|
Генерировать VLAN_ID автоматически
|
Да (если не указан VLAN_ID)
|
|
MTU
|
MTU для тегированного интерфейса и моста
|
Нет
|
|
AR
|
Диапазон адресов, доступных в виртуальной сети
|
Нет
|
net-vlan.conf со следующим содержимым:
NAME = "VLAN"
VN_MAD = "802.1Q"
BRIDGE = "vmbr1"
PHYDEV = "enp3s0"
AUTOMATIC_VLAN_ID = "Yes"
AR=[
TYPE = "IP4",
IP = "192.168.0.150",
SIZE = "5"
]
$ onevnet create net-vlan.conf
ID: 6

Примечание
/etc/one/oned.conf:
VXLAN_IDS = [
START = "2"
]
Таблица 30.3. Параметры виртуальной сети в режиме VXLAN
|
Параметр
|
Значение
|
Обязательный
|
|---|---|---|
|
NAME
|
Имя виртуальной сети
|
Да
|
|
VN_MAD
|
vxlan
|
Да
|
|
BRIDGE
|
Имя сетевого моста (по умолчанию onebr<net_id> или onebr.<vlan_id>)
|
Нет
|
|
PHYDEV
|
Имя физического сетевого устройства, которое будет подключено к мосту
|
Нет
|
|
VLAN_ID
|
ID сети VLAN (если не указан и AUTOMATIC_VLAN_ID = "YES", то идентификатор будет сгенерирован)
|
Да (если AUTOMATIC_VLAN_ID = "NO")
|
|
AUTOMATIC_VLAN_ID
|
Генерировать VLAN_ID автоматически
|
Да (если не указан VLAN_ID)
|
|
MTU
|
MTU для тегированного интерфейса и моста
|
Нет
|
|
AR
|
Диапазон адресов, доступных в виртуальной сети
|
Нет
|
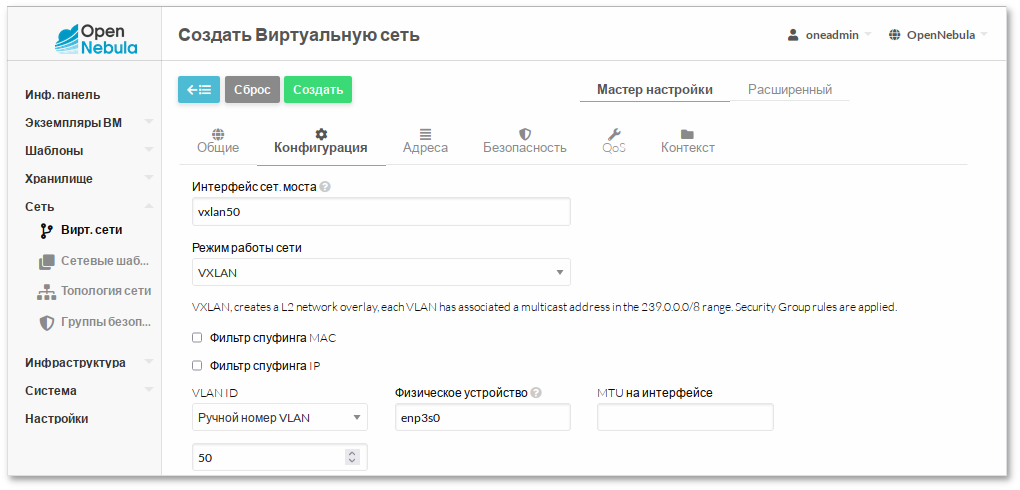
net-vxlan.conf со следующим содержимым:
NAME = "vxlan"
VN_MAD = "vxlan"
BRIDGE = "vxlan50"
PHYDEV = "enp3s0"
VLAN_ID = 50
AR=[
TYPE = "IP4",
IP = "192.168.0.150",
SIZE = "5"
]
$ onevnet create net-vxlan.conf
ID: 7
Примечание
# apt-get install openvswitch
Запущена и добавлена в автозагрузку служба openvswitch:
# systemctl enable --now openvswitch.service
/etc/one/oned.conf:
VLAN_IDS = [
START = "2",
RESERVED = "0, 1, 4095"
]
Таблица 30.4. Параметры виртуальной сети в режиме Open vSwitch
|
Параметр
|
Значение
|
Обязательный
|
|---|---|---|
|
NAME
|
Имя виртуальной сети
|
Да
|
|
VN_MAD
|
ovswitch
|
Да
|
|
BRIDGE
|
Имя сетевого моста Open vSwitch
|
Нет
|
|
PHYDEV
|
Имя физического сетевого устройства, которое будет подключено к мосту
|
Нет (если не используются VLAN)
|
|
VLAN_ID
|
ID сети VLAN (если не указан и AUTOMATIC_VLAN_ID = "YES", то идентификатор будет сгенерирован)
|
Нет
|
|
AUTOMATIC_VLAN_ID
|
Генерировать VLAN_ID автоматически (игнорируется, если определен VLAN_ID)
|
Нет
|
|
MTU
|
MTU для моста Open vSwitch
|
Нет
|
|
AR
|
Диапазон адресов, доступных в виртуальной сети
|
Нет
|
net-ovs.conf со следующим содержимым:
NAME = "OVS"
VN_MAD = "ovswitch"
BRIDGE = "vmbr1"
AR=[
TYPE = "IP4",
IP = "192.168.0.150",
SIZE = "5"
]
$ onevnet create net-ovs.conf
ID: 8

Таблица 30.5. Параметры виртуальной сети в режиме Open vSwitch VXLAN
|
Параметр
|
Значение
|
Обязательный
|
|---|---|---|
|
NAME
|
Имя виртуальной сети
|
Да
|
|
VN_MAD
|
ovswitch_vxlan
|
Да
|
|
BRIDGE
|
Имя сетевого моста Open vSwitch
|
Нет
|
|
PHYDEV
|
Имя физического сетевого устройства, которое будет подключено к мосту
|
Да
|
|
OUTER_VLAN_ID
|
ID внешней сети VXLAN (если не указан и AUTOMATIC_OUTER_VLAN_ID = "YES", то идентификатор будет сгенерирован)
|
Да (если AUTOMATIC_OUTER_VLAN_ID = "NO")
|
|
AUTOMATIC_OUTER_VLAN_ID
|
Генерировать ID автоматически (игнорируется, если определен OUTER_VLAN_ID)
|
Да (если не указан OUTER_VLAN_ID)
|
|
VLAN_ID
|
Внутренний идентификатор VLAN 802.1Q. (если не указан и AUTOMATIC_VLAN_ID = "YES", то идентификатор будет сгенерирован)
|
Нет
|
|
AUTOMATIC_VLAN_ID
|
Генерировать VLAN_ID автоматически (игнорируется, если определен VLAN_ID)
|
Нет
|
|
MTU
|
MTU для интерфейса и моста VXLAN
|
Нет
|
|
AR
|
Диапазон адресов, доступных в виртуальной сети
|
Нет
|
net-ovsx.conf со следующим содержимым:
NAME = "private"
VN_MAD = "ovswitch_vxlan"
PHYDEV = "eth0"
BRIDGE = "ovsvxbr0.10000"
OUTER_VLAN_ID = 10000
VLAN_ID = 50
AR=[
TYPE = "IP4",
IP = "192.168.0.150",
SIZE = "5"
]
$ onevnet create net-ovsx.conf
ID: 11


/var/lib/one/datastores/<идентификатор_хранилища>). Кроме того, для каждой работающей ВМ существует каталог /var/lib/one/datastores/<идентификатор_хранилища>/<идентификатор_ВМ> в соответствующем системном хранилище. Эти каталоги содержат диски ВМ и дополнительные файлы, например, контрольные точки или снимки.
/var/lib/one/datastores |-- 0/ | |-- 0/ | | |-- disk.0 | | `-- disk.1 | |-- 2/ | | `-- disk.0 | `-- 7/ | |-- checkpoint | `-- disk.0 `-- 1 |-- 19217fdaaa715b04f1c740557826514b |-- 99f93bd825f8387144356143dc69787d `-- da8023daf074d0de3c1204e562b8d8d2


/var/lib/one/datastores//<идентификатор_хранилища>) в хранилище образов, но при создании ВМ они будут сброшены в логические тома (LV). ВМ будут запускаться с логических томов узла.
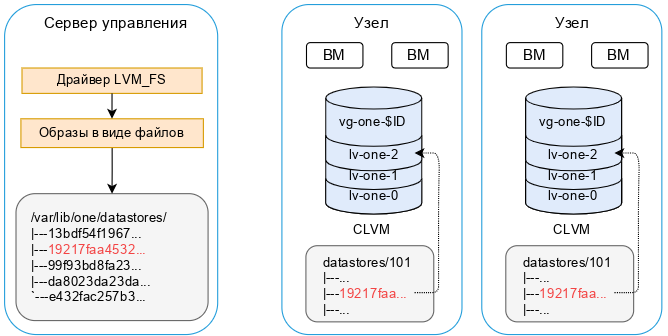
/var/lib/one/datastores/<идентификатор_хранилища>). При этом для передачи данных между хранилищем образов и системным хранилищем используется метод ssh.
Примечание
/var/lib/one/datastores/ можно изменить, указав нужный путь в параметре DATASTORE_LOCATION в конфигурационном файле /etc/one/oned.conf.
onedatastore — инструмент управления хранилищами в OpenNebula. Описание всех доступных опций утилиты onedatastore можно получить, выполнив команду:
$ man onedatastore
$ onedatastore list
ID NAME SIZE AVA CLUSTERS IMAGES TYPE DS TM STAT
2 files 95.4G 91% 0 1 fil fs ssh on
1 default 95.4G 91% 0 8 img fs ssh on
0 system - - 0 0 sys - ssh on
$ onedatastore show default
DATASTORE 1 INFORMATION
ID : 1
NAME : default
USER : oneadmin
GROUP : oneadmin
CLUSTERS : 0
TYPE : IMAGE
DS_MAD : fs
TM_MAD : ssh
BASE PATH : /var/lib/one//datastores/1
DISK_TYPE : FILE
STATE : READY
DATASTORE CAPACITY
TOTAL: : 95.4G
FREE: : 55.9G
USED: : 34.6G
LIMIT: : -
PERMISSIONS
OWNER : um-
GROUP : u--
OTHER : ---
DATASTORE TEMPLATE
ALLOW_ORPHANS="YES"
CLONE_TARGET="SYSTEM"
DISK_TYPE="FILE"
DS_MAD="fs"
LN_TARGET="SYSTEM"
RESTRICTED_DIRS="/"
SAFE_DIRS="/var/tmp"
TM_MAD="ssh"
TYPE="IMAGE_DS"
IMAGES
0
1
2
17
$ onedatastore show system
DATASTORE 0 INFORMATION
ID : 0
NAME : system
USER : oneadmin
GROUP : oneadmin
CLUSTERS : 0
TYPE : SYSTEM
DS_MAD : -
TM_MAD : ssh
BASE PATH : /var/lib/one//datastores/0
DISK_TYPE : FILE
STATE : READY
DATASTORE CAPACITY
TOTAL: : -
FREE: : -
USED: : -
LIMIT: : -
PERMISSIONS
OWNER : um-
GROUP : u--
OTHER : ---
DATASTORE TEMPLATE
ALLOW_ORPHANS="YES"
DISK_TYPE="FILE"
DS_MIGRATE="YES"
RESTRICTED_DIRS="/"
SAFE_DIRS="/var/tmp"
SHARED="NO"
TM_MAD="ssh"
TYPE="SYSTEM_DS"
IMAGES
Примечание
onehost show <hostid>.
Таблица 31.1. Общие атрибуты хранилищ
|
Атрибут
|
Описание
|
|---|---|
|
Description
|
Описание
|
|
RESTRICTED_DIRS
|
Каталоги, которые нельзя использовать для размещения образов. Список каталогов, разделенный пробелами.
|
|
SAFE_DIRS
|
Разрешить использование каталога, указанного в разделе RESTRICTED_DIRS, для размещения образов. Список каталогов, разделенный пробелами.
|
|
NO_DECOMPRESS
|
Не пытаться распаковать файл, который нужно зарегистрировать.
|
|
LIMIT_TRANSFER_BW
|
Максимальная скорость передачи при загрузке образов с URL-адреса http/https (в байтах/секунду). Могут использоваться суффиксы K, M или G.
|
|
DATASTORE_CAPACITY_CHECK
|
Проверять доступную емкость хранилища данных перед созданием нового образа.
|
|
LIMIT_MB
|
Максимально допустимая емкость хранилища данных в МБ.
|
|
BRIDGE_LIST
|
Список мостов узла, разделенных пробелами, которые имеют доступ к хранилищу для добавления новых образов в хранилище.
|
|
STAGING_DIR
|
Путь на узле моста хранения для копирования образа перед его перемещением в конечный пункт назначения. По умолчанию
/var/tmp.
|
|
DRIVER
|
Применение специального драйвера сопоставления изображений. Данный атрибут переопределяет DRIVER образа, установленный в атрибутах образа и шаблоне ВМ.
|
|
COMPATIBLE_SYS_DS
|
Только для хранилищ образов. Установить системные хранилища данных, которые можно использовать с данным хранилищем образов (например, «0,100»).
|
|
CONTEXT_DISK_TYPE
|
Указывает тип диска, используемый для контекстных устройств: BLOCK или FILE (по умолчанию).
|
Примечание
$onedatastore disable system$onedatastore show systemDATASTORE 0 INFORMATION ID : 0 NAME : system ... STATE : DISABLED ...

/var/lib/one/datastores/ должно быть достаточно места для:
/var/lib/one/datastores/ должно быть достаточно места для хранения дисков ВМ, работающих на этом узле.

systemds.conf со следующим содержимым:
NAME = local_system TM_MAD = ssh TYPE = SYSTEM_DSИ выполнить команду:
$ onedatastore create systemds.conf
ID: 101
Примечание
imageds.conf со следующим содержимым:
NAME = local_image TM_MAD = ssh TYPE = IMAGE_DS DS_MAD = fsИ выполнить команду:
$ onedatastore create imageds.conf
ID: 102
Примечание
/var/lib/one/datastores/ можно смонтировать каталог с любого сервера NAS/SAN в сети.
systemds.conf со следующим содержимым:
NAME = nfs_system TM_MAD = shared TYPE = SYSTEM_DSИ выполнить команду:
$ onedatastore create systemds.conf
ID: 101
Примечание
imageds.conf со следующим содержимым:
NAME = nfs_images TM_MAD = shared TYPE = IMAGE_DS DS_MAD = fsИ выполнить команду:
$ onedatastore create imageds.conf
ID: 102
/var/lib/one/datastores/) будут созданы два каталога: 101 и 102. На узлах виртуализации эти каталоги автоматически не создаются, поэтому на узлах виртализации требуется создать каталоги с соответствующими идентификаторами:
$mkdir /var/lib/one/datastores/101$mkdir /var/lib/one/datastores/102
/var/lib/one/datastores/<идентификатор_хранилища> на узле управления и узлах виртуализации необходимо смонтировать удалённый каталог NFS. Например:
# mount -t nfs 192.168.0.157:/export/storage /var/lib/one/datastores/102
Для автоматического монтирования к NFS-серверу при загрузке необходимо добавить следующую строку в файл /etc/fstab:
192.168.0.157:/export/storage /var/lib/one/datastores/102 nfs intr,soft,nolock,_netdev,x-systemd.automount 0 0
Примечание
# systemctl enable --now nfs-client.target
Получить список совместных ресурсов с сервера NFS можно, выполнив команду:
# showmount -e 192.168.0.157
Важно
/etc/fstab и перезагрузки ОС, необходимо назначить на каталог этого хранилища владельца oneadmin. Например:
# chown oneadmin: /var/lib/one/datastores/102
TM_MAD_SYSTEM="ssh"
/var/lib/one/datastores/<идентификатор_хранилища>. В случае режима NFS каталог необходимо смонтировать с сервера NAS. В режиме SSH можно смонтировать любой носитель данных в каталог хранилища.
systemds.conf со следующим содержимым:
NAME = lvm-system TM_MAD = fs_lvm_ssh TYPE = SYSTEM_DS BRIDGE_LIST = "host-01 host-02"И выполнить команду:
$ onedatastore create systemds.conf
ID: 101
imageds.conf со следующим содержимым:
NAME = lvm-images TM_MAD = fs_lvm_ssh TYPE = IMAGE_DS DISK_TYPE = "BLOCK" DS_MAD = fsИ выполнить команду:
$ onedatastore create imageds.conf
ID: 102
Примечание
/var/lib/one/datastores/) будут созданы два каталога: 101 и 102. На узлах виртуализации эти каталоги автоматически не создаются, поэтому требуется создать каталоги с соответствующими идентификаторами:
$mkdir /var/lib/one/datastores/101$mkdir /var/lib/one/datastores/102
Примечание
systool из пакета sysfsutils.
# apt-get install sysfsutils
# systool -c fc_host -A port_name
Class = "fc_host"
Class Device = "host1"
port_name = "0x10000090fa59a61a"
Device = "host1"
Class Device = "host16"
port_name = "0x10000090fa59a61b"
Device = "host16"
# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 59G 0 disk
sdb 8:16 0 931,3G 0 disk
└─mpatha 253:0 0 931,3G 0 mpath
sdc 8:32 0 931,3G 0 disk
└─mpatha 253:0 0 931,3G 0 mpath
sdd 8:48 0 931,3G 0 disk
└─mpatha 253:0 0 931,3G 0 mpath
sde 8:64 0 931,3G 0 disk
└─mpatha 253:0 0 931,3G 0 mpath
В данном примере один LUN на 1000GB виден по четырем путям.
node.startup значение automatic. Значение по умолчанию для параметра node.session.timeo.replacement_timeout составляет 120 секунд. Рекомендуется использовать значение — 15 секунд.
/etc/iscsi/iscsid.conf (по умолчанию). Если iSCSI target уже подключен, то необходимо изменить настройки по умолчанию для конкретной цели в файле /etc/iscsi/nodes/<TARGET>/<PORTAL>/default.
#apt-get install open-iscsi#systemctl enable --now iscsid
/etc/iscsi/iscsid.conf:
node.startup = automatic node.session.timeo.replacement_timeout = 15
#iscsiadm -m discovery -t sendtargets -p <iscsi-target-1-ip>#iscsiadm -m discovery -t sendtargets -p <iscsi-target-2-ip>#iscsiadm -m node --login
/etc/iscsi/iscsid.conf:
node.startup = automatic
/var/lib/iscsi/send_targets/<TargetServer>,<Port>/st_config:
discovery.sendtargets.use_discoveryd = Yes
# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 59G 0 disk
sdb 8:16 0 931,3G 0 disk
└─mpatha 253:0 0 931,3G 0 mpath
sdc 8:32 0 931,3G 0 disk
└─mpatha 253:0 0 931,3G 0 mpath
sdd 8:48 0 931,3G 0 disk
└─mpatha 253:0 0 931,3G 0 mpath
sde 8:64 0 931,3G 0 disk
└─mpatha 253:0 0 931,3G 0 mpath
В данном примере один LUN на 1000GB виден по четырем путям.
Примечание
iscsiadm:
# iscsiadm -m node --logout
# iscsiadm -m node --targetname "iscsi-target-1.test.alt:server.target1" --logout
# iscsiadm -m node -R
# iscsiadm -m session
# apt-get install multipath-tools
И запущена служба multipathd:
# systemctl enable --now multipathd && sleep 5; systemctl status multipathd
Примечание
multipath используется для обнаружения и объединения нескольких путей к устройствам.
multipath:
-l — отобразить текущую multipath-топологию, полученную из sysfs и устройства сопоставления устройств;
-ll — отобразить текущую multipath-топологию, собранную из sysfs, устройства сопоставления устройств и всех других доступных компонентов системы;
-f device — удалить указанное multipath-устройство;
-F — удалить все неиспользуемые multipath-устройства;
-w device — удалить WWID указанного устройства из файла wwids;
-W — сбросить файл wwids, чтобы включить только текущие многопутевые устройства;
-r — принудительная перезагрузка multipath-устройства.
# multipath -ll
mpatha (3600c0ff00014f56ee9f3cf6301000000) dm-0 HP,P2000 G3 FC
size=931G features='1 queue_if_no_path' hwhandler='1 alua' wp=rw
|-+- policy='service-time 0' prio=50 status=active
| |- 1:0:0:1 sdb 8:16 active ready running
| `- 16:0:1:1 sde 8:64 active ready running
`-+- policy='service-time 0' prio=10 status=enabled
|- 1:0:1:1 sdc 8:32 active ready running
`- 16:0:0:1 sdd 8:48 active ready running
# multipath -v3
/etc/multipath.conf:
defaults {
find_multipaths yes
user_friendly_names yes
}
user_friendly_names установлено значение no, то для имени multipath-устройства задается значение World Wide Identifier (WWID). Имя устройства будет /dev/mapper/WWID и /dev/dm-X:
#Если для параметраls /dev/mapper/3600c0ff00014f56ee9f3cf6301000000 #lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS sda 8:0 0 59G 0 disk sdb 8:16 0 931,3G 0 disk └─3600c0ff00014f56ee9f3cf6301000000 253:0 0 931,3G 0 mpath sdc 8:32 0 931,3G 0 disk └─3600c0ff00014f56ee9f3cf6301000000 253:0 0 931,3G 0 mpath sdd 8:48 0 931,3G 0 disk └─3600c0ff00014f56ee9f3cf6301000000 253:0 0 931,3G 0 mpath sde 8:64 0 931,3G 0 disk └─3600c0ff00014f56ee9f3cf6301000000 253:0 0 931,3G 0 mpath
user_friendly_names установлено значение yes, то для имени multipath-устройства задаётся алиас (псевдоним), в форме mpathХ. Имя устройства будет /dev/mapper/mpathХ и /dev/dm-X:
#Однако не гарантируется, что имя устройства будет одинаковым на всех узлах, использующих это multipath-устройство.ls /dev/mapper/mpatha #lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS sda 8:0 0 59G 0 disk sdb 8:16 0 931,3G 0 disk └─mpatha 253:0 0 931,3G 0 mpath sdc 8:32 0 931,3G 0 disk └─mpatha 253:0 0 931,3G 0 mpath sdd 8:48 0 931,3G 0 disk └─mpatha 253:0 0 931,3G 0 mpath sde 8:64 0 931,3G 0 disk └─mpatha 253:0 0 931,3G 0 mpath
/dev/mapper/mpatha). Для этого в файл /etc/multipath.conf добавить секции:
blacklist {
wwid .*
}
blacklist_exceptions {
wwid "3600c0ff00014f56ee9f3cf6301000000"
}
Данная настройка предписывает внести в черный список любые найденные устройства хранения данных, за исключением нужного.
multipaths {
multipath {
wwid "3600c0ff00014f56ee9f3cf6301000000"
alias mpatha
}
}
В этом случае устройство всегда будет доступно только по имени /dev/mapper/mpatha. Вместо mpatha можно вписать любое желаемое имя устройства.
Примечание
# /lib/udev/scsi_id -g -u -d /dev/sdb
3600c0ff00014f56ee9f3cf6301000000
Для устройств в одном multipath WWID будут совпадать.
/etc/multipath.conf может также потребоваться внести рекомендованные производителем СХД параметры.
/etc/multipath.conf необходимо перезапустить службу multipathd для активации настроек:
# systemctl restart multipathd.service
Примечание
/etc/multipath.conf на наличие ошибок можно, выполнив команду:
# multipath -t
# apt-get install ocfs2-tools
Примечание
/etc/ocfs2/cluster.conf. Этот файл должен быть одинаков на всех узлах кластера, при изменении в одном месте его нужно скопировать на остальные узлы. При добавлении нового узла в кластер, описание этого узла должно добавлено быть на всех остальных узлах до монтирования раздела ocfs2 с нового узла.
/etc/ocfs2/cluster.conf.
# o2cb_ctl -C -n mycluster -t cluster -a name=mycluster
# o2cb_ctl -C -n <имя_узла> -t node -a number=0 -a ip_address=<IP_узла> -a ip_port=7777 -a cluster=mycluster
/etc/ocfs2/cluster.conf:
cluster: node_count = 3 heartbeat_mode = local name = mycluster node: ip_port = 7777 ip_address = <IP_узла-01> number = 0 name = <имя_узла-01> cluster = mycluster node: ip_port = 7777 ip_address = <IP_узла-02> number = 1 name = <имя_узла-02> cluster = mycluster node: ip_port = 7777 ip_address = <IP_узла-03> number = 2 name = <имя_узла-03> cluster = mycluster
Примечание
/etc/hostname.
/etc/init.d/o2cb:
# /etc/init.d/o2cb configure
Для ручного запуска кластера нужно выполнить:
#/etc/init.d/o2cb loadchecking debugfs... Loading filesystem "ocfs2_dlmfs": OK Creating directory '/dlm': OK Mounting ocfs2_dlmfs filesystem at /dlm: OK #/etc/init.d/o2cb online myclusterchecking debugfs... Setting cluster stack "o2cb": OK Registering O2CB cluster "mycluster": OK Setting O2CB cluster timeouts : OK
/dev/mapper/mpatha-part1 на диске /dev/mapper/mpatha:
# fdisk /dev/mapper/mpatha
# mkfs.ocfs2 -b 4096 -C 4k -L DBF1 -N 3 /dev/mapper/mpatha-part1
mkfs.ocfs2 1.8.7
Cluster stack: classic o2cb
Label: DBF1
…
mkfs.ocfs2 successful
Таблица 31.2. Параметры команды mkfs.ocfs2
|
Параметр
|
Описание
|
|---|---|
-L метка_тома
|
Метка тома, позволяющая его однозначно идентифицировать при подключении на разных узлах. Для изменения метки тома можно использовать утилиту
tunefs.ocfs2
|
-C размер_кластера
|
Размер кластера — это наименьшая единица пространства, выделенная файлу для хранения данных. Возможные значения: 4, 8, 16, 32, 64, 128, 256, 512 и 1024 КБ. Размер кластера невозможно изменить после форматирования тома
|
-N количество_узлов_кластера
|
Максимальное количество узлов, которые могут одновременно монтировать том. Для изменения количества узлов можно использовать утилиту
tunefs.ocfs2
|
-b размер_блока
|
Наименьшая единица пространства, адресуемая ФС. Возможные значения: 512 байт (не рекомендуется), 1 КБ, 2 КБ или 4 КБ (рекомендуется для большинства томов). Размер блока невозможно изменить после форматирования тома
|
Примечание
# dd if=/dev/zero of=/dev/mapper/mpathX bs=512 count=1 conv=notrunc
# blkid
/dev/mapper/mpatha-part1: LABEL="DBF1" UUID="df49216a-a835-47c6-b7c1-6962e9b7dcb6" BLOCK_SIZE="4096" TYPE="ocfs2" PARTUUID="15f9cd13-01"
/etc/fstab:
UUID=<uuid> /var/lib/one/datastores/<идентификатор_хранилища> ocfs2 _netdev,defaults 0 0Например:
UUID=df49216a-a835-47c6-b7c1-6962e9b7dcb6 /var/lib/one/datastores/102 ocfs2 _netdev,defaults 0 0
# mount -a
Результатом выполнения команды должен быть пустой вывод без ошибок.
# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 59G 0 disk
`-sda1 8:1 0 255M 0 part /boot/efi
sdb 8:16 0 931.3G 0 disk
`-mpatha 253:0 0 931.3G 0 mpath
`-mpatha-part1 253:1 0 931.3G 0 part /var/lib/one/datastores/102
sdc 8:32 0 931.3G 0 disk
|-sdc1 8:33 0 931.3G 0 part
`-mpatha 253:0 0 931.3G 0 mpath
`-mpatha-part1 253:1 0 931.3G 0 part /var/lib/one/datastores/102
sdd 8:48 0 931.3G 0 disk
`-mpatha 253:0 0 931.3G 0 mpath
`-mpatha-part1 253:1 0 931.3G 0 part /var/lib/one/datastores/102
sde 8:64 0 931.3G 0 disk
`-mpatha 253:0 0 931.3G 0 mpath
`-mpatha-part1 253:1 0 931.3G 0 part /var/lib/one/datastores/102
Примечание
_netdev позволяет монтировать данный раздел только после успешного старта сетевой подсистемы.
Важно
/etc/fstab и перезагрузки ОС, необходимо назначить на каталог этого хранилища владельца oneadmin. Например:
# chown oneadmin: /var/lib/one/datastores/102
Примечание
#mounted.ocfs2 -fDevice Stack Cluster F Nodes /dev/mapper/mpatha-part1 o2cb server, host-02, host-01 #mounted.ocfs2 -dDevice Stack Cluster F UUID Label /dev/mapper/mpatha-part1 o2cb DF49216AA83547C6B7C16962E9B7DCB6 DBF
use_lvmetad = 0 в /etc/lvm/lvm.conf (в разделе global) и отключить службу lvm2-lvmetad.service, если она запущена.
# gpasswd -a oneadmin disk
Примечание
/dev/mapper/.
# wipefs -fa /dev/mapper/[LUN_WWID]
# pvcreate /dev/mapper/mpathb
Physical volume "/dev/mapper/mpathb" successfully created.
# vgcreate vg-one-101 /dev/mapper/mpathb
Volume group "vg-one-101" successfully created
# pvs
PV VG Fmt Attr PSize PFree
/dev/mapper/mpathb vg-one-101 lvm2 a-- 931.32g 931.32g

#где 52 — идентификатор ВМ.lvscanACTIVE '/dev/vg-one-101/lv-one-52-0' [50,00 GiB] inherit #lsblksde 8:64 0 931.3G 0 disk └─mpathb 253:1 0 931.3G 0 mpath └─vg--one--101-lv--one--52--0 253:3 0 51G 0 lvm
fileds.conf со следующим содержимым:
NAME = local_file DS_MAD = fs TM_MAD = ssh TYPE = FILE_DSИ выполнить команду:
$ onedatastore create fileds.conf
ID: 105
Примечание
$ onedatastore update <идентификатор_хранилища> <имя_файла>
oneimage.



Примечание

Примечание
$ oneimage create -d 1 --name "ALT Workstation ISO" \
--path /var/tmp/alt-workstation-10.0-x86_64.iso --type CDROM
ID: 31
Создать пустой образ диска (тип образа — DATABLOCK, размер 45 ГБ, драйвер qcow2):
$ oneimage create -d 1 --name "ALT Workstation" \
--type DATABLOCK --size 45G --persistent --driver qcow2
ID: 33
Примечание
template со следующим содержимым:
NAME = "ALT Workstation" CONTEXT = [ NETWORK = "YES", SSH_PUBLIC_KEY = "$USER[SSH_PUBLIC_KEY]" ] CPU = "1" DISK = [ IMAGE = "ALT Workstation ISO", IMAGE_UNAME = "oneadmin" ] DISK = [ DEV_PREFIX = "vd", IMAGE = "ALT Workstation", IMAGE_UNAME = "oneadmin" ] GRAPHICS = [ LISTEN = "0.0.0.0", TYPE = "SPICE" ] HYPERVISOR = "kvm" INPUTS_ORDER = "" LOGO = "images/logos/alt.png" MEMORY = "1024" MEMORY_UNIT_COST = "MB" NIC = [ NETWORK = "VirtNetwork", NETWORK_UNAME = "oneadmin", SECURITY_GROUPS = "0" ] NIC_DEFAULT = [ MODEL = "virtio" ] OS = [ BOOT = "disk1,disk0" ] SCHED_REQUIREMENTS = "ID=\"0\""
$ onetemplate create template
ID: 22










Примечание
$ onetemplate instantiate 9
VM ID: 5
Примечание

spice://192.168.0.180:5905где 192.168.0.180 — IP-адрес узла с ВМ, а 5 — идентификатор ВМ (номер порта 5900 + 5).
# apt-get update && apt-get install opennebula-context
# apt-get install systemd-timesyncd
/etc/systemd/network/lan.network со следующим содержимым:
[Match] Name = * [Network] DHCP = ipv4
# systemctl disable network NetworkManager && systemctl enable systemd-networkd systemd-timesyncd

Примечание
$ onevm terminate 5

Примечание
$oneimage chtype 1 OS$oneimage nonpersistent 1

$ onemarket list
ID NAME SIZE AVAIL APPS MAD ZONE STAT
3 DockerHub 0M - 175 dockerh 0 on
2 TurnKey Linux Containers 0M - 0 turnkey 0 on
1 Linux Containers 0M - 0 linuxco 0 on
0 OpenNebula Public 0M - 54 one 0 on



Примечание
# apt-get install docker-engine
# gpasswd -a oneadmin docker
и выполнить повторный вход в систему
# systemctl enable --now docker
# systemctl restart opennebula




oneimage create), используя в качестве PATH (или опции --path) URL-адрес следующего формата:
docker://<image>?size=<image_size>&filesystem=<fs_type>&format=raw&tag=<tag>&distro=<distro>где:
Примечание
/etc/os-release. Если эта информация недоступна внутри контейнера, необходимо использовать аргумент distro.
$ oneimage create --name alt-p10 --path 'docker://alt?size=3072&filesystem=ext4&format=raw&tag=p10' --datastore 1
ID: 22
Примечание

oneuser — инструмент командной строки для управления пользователями в OpenNebula.
$ oneuser list
ID NAME ENAB GROUP AUTH VMS MEMORY CPU
1 serveradmin yes oneadmin server_c 0 / - 0M / 0.0 / -
0 oneadmin yes oneadmin core - - -
$ oneuser create <user_name> <password>
$ oneuser chgrp <user_name> oneadmin
Что бы удалить пользователя из группы, необходимо переместить его обратно в группу users.
$ oneuser disable <user_name>
Включить отключённого пользователя:
$ oneuser enable <user_name>
Удалить пользователя:
$ oneuser delete <user_name>

Примечание
onegroup — инструмент командной строки для управления группами в OpenNebula.
$ onegroup list
ID NAME USERS VMS MEMORY CPU
1 users 1 0 / - 0M / - 0.0 / -
0 oneadmin 3 - - -
$ onegroup create group_name
ID: 100
Новая группа получила идентификатор 100, чтобы отличать специальные группы от созданных пользователем.
$ onegroup create --name testgroup \
--admin_user testgroup-admin --admin_password somestr \
--resources TEMPLATE+VM
При выполнении данной команды также будет создан администратор группы.
$ onegroup addadmin <groupid_list> <userid>


$ onevm show 8
VIRTUAL MACHINE 8 INFORMATION
ID : 8
NAME : test
USER : oneadmin
GROUP : oneadmin
STATE : POWEROFF
LCM_STATE : LCM_INIT
LOCK : None
RESCHED : No
HOST : host-01
CLUSTER ID : 0
CLUSTER : default
START TIME : 04/08 16:12:53
END TIME : -
DEPLOY ID : 69ab21c2-22ad-4afb-bfc1-7b4e4ff2364f
VIRTUAL MACHINE MONITORING
ID : 8
TIMESTAMP : 1712756284
PERMISSIONS
OWNER : um-
GROUP : ---
OTHER : ---
…
В данном примере показаны права на ВМ с ID=8.
chmod. Права записываются в числовом формате. Пример изменения прав:
$onevm chmod 8 607$onevm show 8… PERMISSIONS OWNER : um- GROUP : --- OTHER : uma
Примечание
oned.conf (атрибут DEFAULT_UMASK);
oneuser umask.
$ oneacl list
ID USER RES_VHNIUTGDCOZSvRMAPt RID OPE_UMAC ZONE
0 @1 V--I-T---O-S----P- * ---c *
1 * ----------Z------- * u--- *
2 * --------------MA-- * u--- *
3 @1 -H---------------- * -m-- #0
4 @1 --N--------------- * u--- #0
5 @1 -------D---------- * u--- #0
6 #3 ---I-------------- #30 u--- #0
Данные правила соответсвуют следующим:
@1 VM+IMAGE+TEMPLATE+DOCUMENT+SECGROUP/* CREATE * * ZONE/* USE * * MARKETPLACE+MARKETPLACEAPP/* USE * @1 HOST/* MANAGE #0 @1 NET/* USE #0 @1 DATASTORE/* USE #0 #3 IMAGE/#30 USE *Первые шесть правил были созданы при начальной загрузке OpenNebula, а последнее — с помощью
oneacl:
$ oneacl create "#3 IMAGE/#30 USE"
ID: 6
oneacl list:
$ oneacl delete <ID>


Примечание
Важно
/etc/one/oned.conf добавить строку DEFAULT_AUTH = "ldap":
…
AUTH_MAD = [
EXECUTABLE = "one_auth_mad",
AUTHN = "ssh,x509,ldap,server_cipher,server_x509"
]
DEFAULT_AUTH = "ldap"
…
Важно
/etc/one/sunstone-server.conf для параметра :auth должно быть указано значение opennebula:
:auth: opennebula
/etc/one/auth/ldap_auth.conf необходимо указать:
:user — пользователь AD с правами на чтение (пользователь указывается в формате opennebula@test.alt);
:password — пароль пользователя;
:host — IP-адрес или имя сервера AD (имя должно разрешаться через DNS или /etc/hosts);
:base — базовый DN для поиска пользователя;
:user_field — для этого параметра следует установить значение sAMAccountName;
:rfc2307bis — для этого параметра следует установить значение true.
/etc/one/auth/ldap_auth.conf:
server 1:
:user: 'opennebula@test.alt'
:password: 'Pa$$word'
:auth_method: :simple
:host: dc1.test.alt
:port: 389
:base: 'dc=test,dc=alt'
:user_field: 'sAMAccountName'
:mapping_generate: false
:mapping_timeout: 300
:mapping_filename: server1.yaml
:mapping_key: GROUP_DN
:mapping_default: 100
:rfc2307bis: true
:order:
- server 1
Примечание
:order указывается порядок, в котором будут опрошены настроенные серверы. Элементы в :order обрабатываются по порядку, пока пользователь не будет успешно аутентифицирован или не будет достигнут конец списка. Сервер, не указанный в :order, не будет опрошен.
Примечание
/etc/one/auth/ldap_auth.conf для настройки аутентификации в домене FreeIPA (домен example.test):
server 1:
:user: 'uid=admin,cn=users,cn=accounts,dc=example,dc=test'
:password: '12345678'
:auth_method: :simple
:host: ipa.example.test
:port: 389
:base: 'dc=example,dc=test'
:user_field: 'uid'
:mapping_generate: false
:mapping_timeout: 300
:mapping_filename: server1.yaml
:mapping_key: GROUP_DN
:mapping_default: 100
:rfc2307bis: true
:order:
- server 1

:mapping_file (файл должен находиться в каталоге /var/lib/one/).
:mapping_generate должно быть установлено значение true). Если в шаблон группы добавить строку:
GROUP_DN="CN=office,CN=Users,DC=test,DC=alt"

/etc/one/auth/ldap_auth.conf для параметра :mapping_key установить значение GROUP_DN, то поиск DN сопоставляемой группы будет осуществляться в этом параметре шаблона. В этом случае файл /var/lib/one/server1.yaml будет сгенерирован со следующим содержимым:
--- CN=office,CN=Users,DC=test,DC=alt: '100'и пользователи из группы AD office, будут сопоставлены с группой ALT (ID=100).
:mapping_generate равным false, и выполнить сопоставление вручную. Файл сопоставления имеет формат YAML и содержит хеш, где ключ — это DN группы AD, а значение — идентификатор группы OpenNebula. Например, если содержимое файла /var/lib/one/server1.yaml:
CN=office,CN=Users,DC=test,DC=alt: '100' CN=Domain Admins,CN=Users,DC=test,DC=alt: '101'то пользователи из группы AD office, будут сопоставлены с группой ALT (ID=100), а из группы AD Domain Admin — с группой Admin (ID=101):

/etc/one/oned.conf);
$onezone listC ID NAME ENDPOINT FED_INDEX * 0 OpenNebula http://localhost:2633/RPC2 -1 $onezone server-add 0 --name opennebula --rpc http://192.168.0.186:2633/RPC2$onezone show 0ZONE 0 INFORMATION ID : 0 NAME : OpenNebula ZONE SERVERS ID NAME ENDPOINT 0 opennebula http://192.168.0.186:2633/RPC2 HA & FEDERATION SYNC STATUS ID NAME STATE TERM INDEX COMMIT VOTE FED_INDEX 0 opennebula solo 0 -1 0 -1 -1 ZONE TEMPLATE ENDPOINT="http://localhost:2633/RPC2"
/etc/one/oned.conf:
FEDERATION = [
MODE = "STANDALONE",
ZONE_ID = 0,
SERVER_ID = 0, # изменить с -1 на 0 (0 — это ID сервера)
MASTER_ONED = ""
]
/etc/one/oned.conf):
RAFT_LEADER_HOOK = [
COMMAND = "raft/vip.sh",
ARGUMENTS = "leader enp0s3 192.168.0.200/24"
]
# Executed when a server transits from leader->follower
RAFT_FOLLOWER_HOOK = [
COMMAND = "raft/vip.sh",
ARGUMENTS = "follower enp0s3 192.168.0.200/24"
]
$ onezone show 0
ZONE 0 INFORMATION
ID : 0
NAME : OpenNebula
ZONE SERVERS
ID NAME ENDPOINT
0 opennebula http://192.168.0.186:2633/RPC2
HA & FEDERATION SYNC STATUS
ID NAME STATE TERM INDEX COMMIT VOTE FED_INDEX
0 opennebula leader 1 5 5 0 -1
ZONE TEMPLATE
ENDPOINT="http://localhost:2633/RPC
Сервер opennebula стал Leader-сервером, также ему был присвоен плавающий адрес (Floating IP):
$ ip -o a sh enp0s3
2: enp0s3 inet 192.168.0.186/24 brd 192.168.0.255 scope global enp0s3\ valid_lft forever preferred_lft forever
2: enp0s3 inet 192.168.0.200/24 scope global secondary enp0s3\ valid_lft forever preferred_lft forever
2: enp0s3 inet6 fe80::a00:27ff:fec7:38e6/64 scope link \ valid_lft forever preferred_lft forever
Предупреждение
Предупреждение
/var/lib/one/.one/:
$onedb backup -u oneadmin -d opennebula -p oneadminMySQL dump stored in /var/lib/one/mysql_localhost_opennebula_2021-6-23_13:43:21.sql Use 'onedb restore' or restore the DB using the mysql command: mysql -u user -h server -P port db_name < backup_file $scp /var/lib/one/mysql_localhost_opennebula_2021-6-23_13\:43\:21.sql <ip>:/tmp$ssh <ip> rm -rf /var/lib/one/.one$scp -r /var/lib/one/.one/ <ip>:/var/lib/one/
$ onedb restore -f -u oneadmin -p oneadmin -d opennebula /tmp/mysql_localhost_opennebula_2021-6-23_13\:43\:21.sql
MySQL DB opennebula at localhost restored.
$ onezone server-add 0 --name server02 --rpc http://192.168.0.187:2633/RPC2
Проверить зону на Leader-сервере:
$ onezone show 0
ZONE 0 INFORMATION
ID : 0
NAME : OpenNebula
ZONE SERVERS
ID NAME ENDPOINT
0 opennebula http://192.168.0.186:2633/RPC2
1 server02 http://192.168.0.187:2633/RPC2
HA & FEDERATION SYNC STATUS
ID NAME STATE TERM INDEX COMMIT VOTE FED_INDEX
0 opennebula leader 4 22 22 0 -1
1 server02 error - - - - -
ZONE TEMPLATE
ENDPOINT="http://localhost:2633/RPC2"
Новый сервер находится в состоянии ошибки, так как OpenNebula на новом сервере не запущена. Следует запомнить идентификатор сервера, в этом случае он равен 1.
/etc/one/oned.conf (указать в качестве SERVER_ID значение из предыдущего шага). Включить Raft-обработчики, как это было выполнено на Leader.
$ onezone show 0
ZONE 0 INFORMATION
ID : 0
NAME : OpenNebula
ZONE SERVERS
ID NAME ENDPOINT
0 opennebula http://192.168.0.186:2633/RPC2
1 server02 http://192.168.0.187:2633/RPC2
HA & FEDERATION SYNC STATUS
ID NAME STATE TERM INDEX COMMIT VOTE FED_INDEX
0 opennebula leader 4 28 28 0 -1
1 server02 follower 4 28 28 0 -1
ZONE TEMPLATE
ENDPOINT="http://localhost:2633/RPC2""
Примечание
$ onezone show 0
ZONE 0 INFORMATION
ID : 0
NAME : OpenNebula
ZONE SERVERS
ID NAME ENDPOINT
0 opennebula http://192.168.0.186:2633/RPC2
1 server02 http://192.168.0.187:2633/RPC2
2 server03 http://192.168.0.188:2633/RPC2
HA & FEDERATION SYNC STATUS
ID NAME STATE TERM INDEX COMMIT VOTE FED_INDEX
0 opennebula leader 4 35 35 0 -1
1 server02 follower 4 35 35 0 -1
2 server03 follower 4 35 35 0 -1
ZONE TEMPLATE
ENDPOINT="http://localhost:2633/RPC2"
/var/log/one/oned.log), как в текущем Leader (если он есть), так и в узле, который находится в состоянии Error. Все сообщения Raft будут регистрироваться в этом файле.
$ onezone server-add <zoneid>
параметры:
-n, --name — имя сервера зоны;
-r, --rpc — конечная точка RPC сервера зоны;
-v, --verbose — подробный режим;
--user name — имя пользователя, используемое для подключения к OpenNebula;
--password password — пароль для аутентификации в OpenNebula;
--endpoint endpoint — URL конечной точки интерфейса OpenNebula xmlrpc.
$ onezone server-del <zoneid> <serverid>
параметры:
-v, --verbose — подробный режим;
--user name — имя пользователя, используемое для подключения к OpenNebula;
--password password — пароль для аутентификации в OpenNebula;
--endpoint endpoint — URL конечной точки интерфейса OpenNebula xmlrpc.
$ onezone server-reset <zone_id> <server_id_of_failed_follower>
Содержание
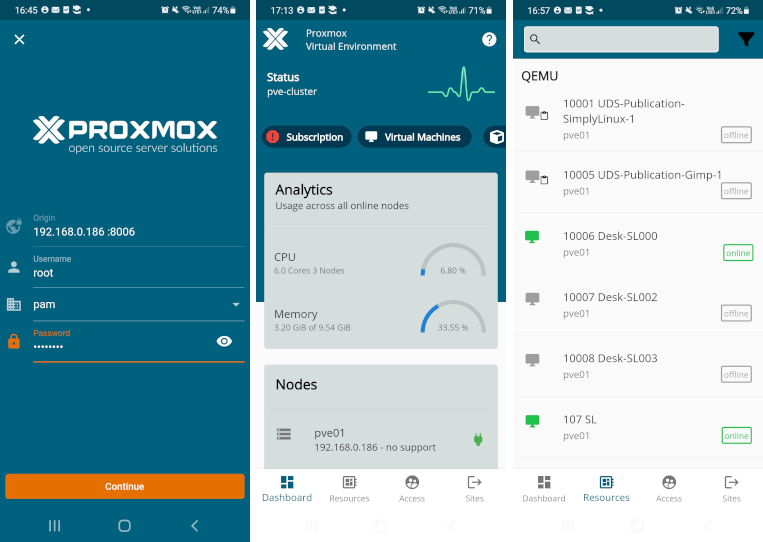
https://<имя-компьютера>:8006. Потребуется пройти аутентификацию (логин по умолчанию: root, пароль указывается в процессе установки ОС):

Примечание

Примечание
Важно
Важно
sleep 500 && reboot.
Примечание
#mkdir /etc/net/ifaces/vmbr0#cp /etc/net/ifaces/enp0s3/* /etc/net/ifaces/vmbr0/#rm -f /etc/net/ifaces/enp0s3/{i,r}*#cat<<EOF > /etc/net/ifaces/vmbr0/options BOOTPROTO=static CONFIG_WIRELESS=no CONFIG_IPV4=yes HOST='enp0s3' ONBOOT=yes TYPE=bri EOF
/etc/net/ifaces/enp0s3/ipv4address.
HOST файла /etc/net/ifaces/vmbr0/options нужно указать те интерфейсы, которые будут входить в мост. Если в него будут входить интерфейсы, которые до этого имели IP-адрес (например, enp0s3), то этот адрес должен быть удален (например, можно закомментировать содержимое файла /etc/net/ifaces/enp0s3/ipv4address).
# systemctl restart network
# hostnamectl set-hostname <имя узла>
Например:
# hostnamectl set-hostname pve01.test.alt
Примечание
#apt-get install alterator-fbi#systemctl start ahttpd#systemctl start alteratord



# apt-get install pve-manager
Все необходимые компоненты при этом будут установлены автоматически.
/etc/hosts:
# echo "192.168.0.186 pve01.test.alt pve01" >> /etc/hosts
# systemctl enable --now pve-cluster
#systemctl startlxc lxc-net lxc-monitord pve-lxc-syscalld \ pvedaemon pve-firewall pvestatd pve-ha-lrm pve-ha-crm spiceproxy pveproxy qmeventd #systemctl enablecorosync lxc lxc-net lxc-monitord pve-lxc-syscalld \ pve-cluster pvedaemon pve-firewall pvestatd pve-ha-lrm pve-ha-crm spiceproxy \ pveproxy pve-guests qmeventd
https://<имя-компьютера>:8006.
Примечание
Важно
#control sshd-permit-root-login without_password#systemctl restart sshd
#А после того, как сервер будет добавлен, снова отключить.control sshd-permit-root-login enabled#systemctl restart sshd
Таблица 38.1. Используемые порты
|
Порт
|
Функция
|
|---|---|
|
TCP 8006
|
Веб-интерфейс PVE
|
|
TCP 5900-5999
|
Доступ к консоли VNC
|
|
TCP 3128
|
Доступ к консоли SPICE
|
|
TCP 22
|
SSH доступ
|
|
UDP 5404, 5405
|
Широковещательный CMAN для применения настроек кластера
|
/etc/hosts:
#echo "192.168.0.186 pve01.test.alt pve01" >> /etc/hosts#echo "192.168.0.90 pve02.test.alt pve02" >> /etc/hosts#echo "192.168.0.70 pve03.test.alt pve03" >> /etc/hosts
Примечание

Примечание
/etc/hosts разрешающимся в 127.0.0.1.





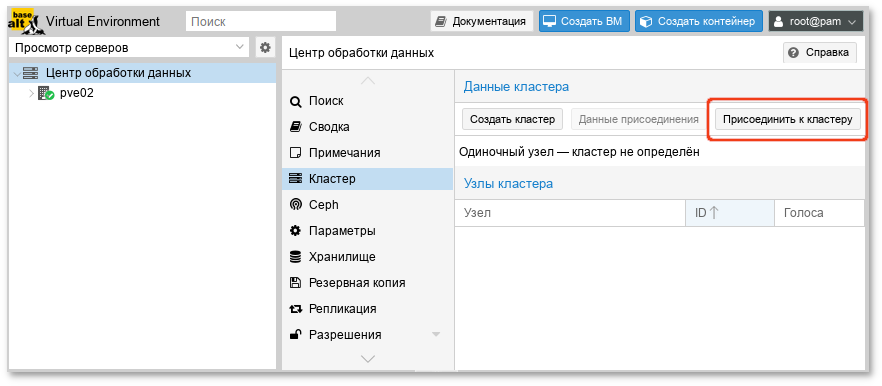



# pvecm create <cluster_name>
#systemctl start pve-cluster#pvecm create pve-cluster
# pvecm status
Cluster information
-------------------
Name: pve-cluster
Config Version: 1
Transport: knet
Secure auth: on
Quorum information
------------------
Date: Mon Apr 1 10:32:25 2024
Quorum provider: corosync_votequorum
Nodes: 1
Node ID: 0x00000001
Ring ID: 1.5
Quorate: Yes
Votequorum information
----------------------
Expected votes: 1
Highest expected: 1
Total votes: 1
Quorum: 1
Flags: Quorate
Membership information
----------------------
Nodeid Votes Name
0x00000001 1 192.168.0.186 (local)
/etc/pve/corosync.conf. По мере добавления узлов в кластер файл настройки будет автоматически пополняться информацией об узлах.
# pvecm add <existing_node_in_cluster>
где existing_node_in_cluster — адрес уже добавленного узла (рекомендуется указывать самый первый).
# pvecm add pve01
где pve01 — имя или IP-адрес «головного» узла.
# pvecm add pve01
Please enter superuser (root) password for 'pve01': ***
Establishing API connection with host 'pve01'
Login succeeded.
Request addition of this node
Join request OK, finishing setup locally
stopping pve-cluster service
backup old database to '/var/lib/pve-cluster/backup/config-1625747072.sql.gz'
waiting for quorum...OK
(re)generate node files
generate new node certificate
merge authorized SSH keys and known hosts
generated new node certificate, restart pveproxy and pvedaemon services
successfully added node 'pve03' to cluster.
/etc/pve/corosync.conf должен содержать информацию об узлах кластера.
#systemctl startpve-cluster pveproxy pvedaemon pvestatd pve-firewall \ pvefw-logger pve-ha-crm pve-ha-lrm spiceproxy \ lxc lxcfs lxc-net lxc-monitord qmeventd pvescheduler pve-lxc-syscalld #systemctl enablepve-cluster pveproxy pvedaemon pvestatd pve-firewall \ corosync pvefw-logger pve-guests pve-ha-crm pve-ha-lrm spiceproxy \ lxc lxcfs lxc-net lxc-monitord qmeventd pvescheduler pve-lxc-syscalld
pvecm nodes, чтобы определить идентификатор узла, который следует удалить:
# pvecm nodes
Membership information
----------------------
Nodeid Votes Name
1 1 pve01 (local)
2 1 pve02
3 1 pve03
# pvecm delnode pve02
Membership information команда отобразит список узлов кластера без удаленного узла):
# pvecm status
…
Membership information
----------------------
Nodeid Votes Name
0x00000001 1 192.168.0.186 (local)
0x00000003 1 192.168.0.70
Важно
/etc/pve/nodes/<имя_узла> не удаляется автоматически. Он может содержать конфигурации ВМ, хранилищ и другие данные, которые при необходимости можно сохранить или перенести.
Примечание
#Командаpvecm expected 1#pvecm delnode <недоступный_узел>
pvecm expected 1 применяется в ситуациях, когда:
pvecm expected 1 является аварийной мерой управления кластером, а не штатной операцией, и должно применяться только при осознанном принятии риска потери отказоустойчивости.
# pvecm status
…
Votequorum information
----------------------
Expected votes: 5
Highest expected: 5
Total votes: 5
Quorum: 3
Flags: Quorate
…
В выводе команды видно, что в кластере пять узлов (Expected votes), из них для кворума необходимо не менее трёх (Quorum), сейчас все пять узлов активны (Total votes), кворум соблюден (Flags: Quorate).
Примечание
Важно
#А после того, как QDevice будет добавлен, отключить:control sshd-permit-root-login enabled#systemctl restart sshd
#control sshd-permit-root-login without_password#systemctl restart sshd
# apt-get install corosync-qnetd
corosync-qnetd:
# systemctl enable --now corosync-qnetd
# apt-get install corosync-qdevice
# pvecm qdevice setup 192.168.0.88
где 192.168.0.88 — IP-адрес арбитра (внешнего сервера).
# pvecm status
…
Votequorum information
----------------------
Expected votes: 5
Highest expected: 5
Total votes: 5
Quorum: 3
Flags: Quorate Qdevice
Membership information
----------------------
Nodeid Votes Qdevice Name
0x00000001 1 A,V,NMW 192.168.0.186 (local)
0x00000002 1 A,V,NMW 192.168.0.90
0x00000003 1 A,V,NMW 192.168.0.70
0x00000004 1 A,V,NMW 192.168.0.91
0x00000000 1 Qdevice
# pvecm qdevice remove
/etc/pve/priv/ и /etc/pve/nodes/${NAME}/priv/ доступны только root.
/etc/pve/.
Таблица 39.1. Доступные типы хранилищ
|
Хранилище
|
PVE тип
|
Уровень
|
Общее (shared)
|
Снимки (snapshots)
|
|---|---|---|---|---|
|
ZFS (локальный)
|
zfspool
|
файл
|
нет
|
да
|
|
dir
|
файл
|
нет
|
нет (возможны в формате qcow2)
|
|
|
btrfs
|
файл
|
нет
|
да
|
|
|
nfs
|
файл
|
да
|
нет (возможны в формате qcow2)
|
|
|
cifs
|
файл
|
да
|
нет (возможны в формате qcow2)
|
|
|
glusterfs
|
файл
|
да
|
нет (возможны в формате qcow2)
|
|
|
cephfs
|
файл
|
да
|
да
|
|
|
lvm
|
блок
|
нет*
|
нет
|
|
|
lvmthin
|
блок
|
нет
|
да
|
|
|
iscsi
|
блок
|
да
|
нет
|
|
|
iscsidirect
|
блок
|
да
|
нет
|
|
|
rbd
|
блок
|
да
|
да
|
|
|
ZFS over iSCSI
|
zfs
|
блок
|
да
|
да
|
|
pbs
|
файл/блок
|
да
|
-
|
Примечание
/etc/pve/storage.cfg. Поскольку этот файл находится в /etc/pve/, он автоматически распространяется на все узлы кластера. Таким образом, все узлы имеют одинаковую конфигурацию хранилища.
<type>: <STORAGE_ID>
<property> <value>
<property> <value>
...
/etc/pve/storage.cfg:
# cat /etc/pve/storage.cfg
dir: local
path /var/lib/vz
content images,rootdir,iso,snippets,vztmpl
maxfiles 0
nfs: nfs-storage
export /export/storage
path /mnt/nfs-vol
server 192.168.0.105
content images,iso,backup,vztmpl
options vers=3,nolock,tcp
/var/lib/vz, и описание NFS-хранилища nfs-storage.
Таблица 39.2. Параметры хранилищ
|
Свойство
|
Описание
|
|---|---|
|
nodes
|
Список узлов кластера, где хранилище можно использовать/доступно. Можно использовать это свойство, чтобы ограничить доступ к хранилищу.
|
|
content
|
Хранилище может поддерживать несколько типов содержимого. Это свойство указывает, для чего используется это хранилище.
Доступные опции:
|
|
shared
|
Указать, что это единое хранилище с одинаковым содержимым на всех узлах (или на всех перечисленных в опции
nodes). Данное свойство не делает содержимое локального хранилища автоматически доступным для других узлов, он просто помечает как таковое уже общее хранилище!
|
|
disable
|
Отключить хранилище
|
|
maxfiles
|
Устарело, следует использовать свойство prune-backups. Максимальное количество файлов резервных копий на ВМ
|
|
prune-backups
|
Варианты хранения резервных копий
|
|
format
|
Формат образа по умолчанию (raw|qcow2|vmdk)
|
|
preallocation
|
Режим предварительного выделения (off|metadata|falloc|full) для образов raw и qcow2 в файловых хранилищах. По умолчанию используется значение metadata (равносильно значению off для образов raw). При использовании сетевых хранилищ в сочетании с большими образами qcow2, использование значения off может помочь избежать таймаутов.
|
Примечание
local:iso/slinux-10.2-x86_64.iso local:101/vm-101-disk-0.qcow2 local:backup/vzdump-qemu-100-2023_08_22-21_12_33.vma.zst nfs-storage:vztmpl/alt-p10-rootfs-systemd-x86_64.tar.xz
# pvesm path <VOLUME_ID>
Например:
#pvesm path local:iso/slinux-10.2-x86_64.iso/var/lib/vz/template/iso/slinux-10.2-x86_64.iso #pvesm path nfs-storage:vztmpl/alt-p10-rootfs-systemd-x86_64.tar.xz/mnt/pve/nfs-storage/template/cache/alt-p10-rootfs-systemd-x86_64.tar.xz
pvesm (PVE Storage Manager), позволяет выполнять общие задачи управления хранилищами.
#pvesm add <TYPE> <STORAGE_ID> <OPTIONS>#pvesm add dir <STORAGE_ID> --path <PATH>#pvesm add nfs <STORAGE_ID> --path <PATH> --server <SERVER> --export <EXPORT>#pvesm add lvm <STORAGE_ID> --vgname <VGNAME>#pvesm add iscsi <STORAGE_ID> --portal <HOST[:PORT]> --target <TARGET>
# pvesm set <STORAGE_ID> --disable 1
# pvesm set <STORAGE_ID> --disable 0
#pvesm set <STORAGE_ID> <OPTIONS>#pvesm set <STORAGE_ID> --shared 1#pvesm set local --format qcow2#pvesm set <STORAGE_ID> --content iso
# pvesm remove <STORAGE_ID>
# pvesm alloc <STORAGE_ID> <VMID> <name> <size> [--format <raw|qcow2>]
# pvesm alloc local <VMID> '' 4G
# pvesm free <VOLUME_ID>
# pvesm status
# pvesm list <STORAGE_ID> [--vmid <VMID>]
# pvesm list <STORAGE_ID> --iso


Примечание

Таблица 39.3. Структура каталогов
|
Тип данных
|
Подкаталог
|
|---|---|
|
Образы дисков ВМ
|
images/<VMID>/
|
|
ISO-образы
|
template/iso/
|
|
Шаблоны контейнеров
|
template/cache/
|
|
Резервные копии VZDump
|
dump/
|
|
Фрагменты (сниппеты)
|
snippets/
|
Примечание
/etc/fstab, а затем определить хранилище каталогов для этой точки монтирования. Таким образом, можно использовать любую файловую систему (ФС), поддерживаемую Linux.
Примечание
/mnt/iso:

path — указание каталога (это должен быть абсолютный путь к файловой системе);
content-dirs (опционально) — позволяет изменить макет по умолчанию. Состоит из списка идентификаторов, разделенных запятыми, в формате:
vtype=pathгде vtype — один из разрешенных типов контента для хранилища, а path — путь относительно точки монтирования хранилища.
/etc/pve/storage.cfg):
dir: backup
path /mnt/backup
content backup
prune-backups keep-last=7
shared 0
content-dirs backup=custom/backup
/mnt/backup/custom/backup.
Примечание
shared (Общий доступ) можно установить только для кластерных ФС (например, ocfs2).
VM-<VMID>-<NAME>.<FORMAT>где:
# ls /var/lib/vz/images/101
vm-101-disk-0.qcow2 vm-101-disk-1.qcow2
base-<VMID>-<NAME>.<FORMAT>
/etc/fstab).
shared, который всегда установлен. Кроме того, для настройки NFS используются следующие свойства:
server — IP-адрес сервера или DNS-имя. Предпочтительнее использовать IP-адрес вместо DNS-имени (чтобы избежать задержек при поиске DNS);
export — совместный ресурс с сервера NFS (список можно просмотреть, выполнив команду pvesm scan nfs <server>);
path — локальная точка монтирования (по умолчанию /mnt/pve/<STORAGE_ID>/);
content-dirs (опционально) — позволяет изменить макет по умолчанию. Состоит из списка идентификаторов, разделенных запятыми, в формате:
vtype=pathгде vtype — один из разрешенных типов контента для хранилища, а path — путь относительно точки монтирования хранилища;
options — параметры монтирования NFS (см. man nfs).
/etc/pve/storage.cfg):
nfs: nfs-storage
export /export/storage
path /mnt/pve/nfs-storage
server 192.168.0.105
content images,backup,vztmpl,iso
options vers=3,nolock,tcp
Примечание
soft, в этом случае будет выполняться только три запроса.
Примечание
# systemctl enable --now nfs-client.target

/export/storage.
pvesm:
# pvesm add nfs nfs-storage --path /mnt/nfs-vol --server 192.168.0.105 --options vers=3,nolock,tcp --export /export/storage --content images,iso,vztmpl,backup
# pvesm nfsscan <server>
Примечание
Примечание
is_mountpoint.
/etc/pve/storage.cfg):
btrfs: btrfs-storage
path /mnt/data/btrfs-storage
content rootdir,images
is_mountpoint /mnt/data
nodes pve02
prune-backups keep-all=1
В данном примере файловая система BTRFS смонтирована в /mnt/data, а в качестве пула хранения данных добавляется её подкаталог btrfs-storage/.
/mnt/data:

pvesm:
# pvesm add btrfs btrfs-storage --path /mnt/data/btrfs-storage --is_mountpoint /mnt/data/ --content images,rootdir
# mkfs.btrfs -m single -d single -L My-Storage /dev/sdd
Параметры -m и -d используются для установки профиля для метаданных и данных соответственно. С помощью необязательного параметра -L можно установить метку.
# mkfs.btrfs -m raid1 -d raid1 -L My-Storage /dev/sdb1 /dev/sdc1
#mkdir /mnt/data#mount /dev/sdd /mnt/data
/etc/fstab. Рекомендуется использовать значение UUID (выведенное командой mkfs.btrfs), например:
UUID=5a556184-43b2-4212-bc21-eee3798c8322 /mnt/data btrfs defaults 0 0Выполнить проверку монтирования:
# mount -a
Результатом выполнения команды должен быть пустой вывод без ошибок.
Примечание
# blkid
/dev/sdd: LABEL="My-Storage" UUID="5a556184-43b2-4212-bc21-eee3798c8322" BLOCK_SIZE="4096" TYPE="btrfs"
# btrfs subvolume create /mnt/data/btrfs-storage
# btrfs subvolume snapshot -r /mnt/data/btrfs-storage /mnt/data/new
Будет создан доступный только для чтения «клон» подтома /mnt/data/btrfs-storage. Чтобы из снимка, доступного только для чтения, создать его версию, доступную для записи, следует просто создать его снимок без опции -r.
# btrfs subvolume list /mnt/data
ID 256 gen 17 top level 5 path btrfs-storage
ID 257 gen 14 top level 5 path new
# btrfs subvolume delete /mnt/data/btrfs-storage
# btrfs filesystem usage /mnt/data
или:
$ btrfs filesystem df /mnt/data
Примечание
shared, который всегда установлен. Кроме того, для настройки CIFS используются следующие свойства:
server — IP-адрес сервера или DNS-имя. Предпочтительнее использовать IP-адрес вместо DNS-имени (чтобы избежать задержек при поиске DNS);
share — совместный ресурс с сервера CIFS (список можно просмотреть, выполнив команду pvesm scan cifs <server>);
username — имя пользователя для хранилища CIFS (опционально, по умолчанию «guest»);
password — пароль пользователя (опционально). Пароль будет сохранен в файле, доступном только для чтения root-пользователю (/etc/pve/priv/storage/<STORAGE-ID>.pw);
domain — устанавливает домен пользователя (рабочую группу) для этого хранилища (опционально);
smbversion — версия протокола SMB (опционально, по умолчанию 3). Версия 1 не поддерживается;
path — локальная точка монтирования (по умолчанию /mnt/pve/<STORAGE_ID>/);
content-dirs (опционально) — позволяет изменить макет по умолчанию. Состоит из списка идентификаторов, разделенных запятыми, в формате:
vtype=pathгде vtype — один из разрешенных типов контента для хранилища, а path — путь относительно точки монтирования хранилища;
options — дополнительные параметры монтирования CIFS (см. man mount.cifs). Некоторые параметры устанавливаются автоматически, и их не следует задавать в этом параметре. PVE всегда устанавливает опцию soft;
subdir — подкаталог общего ресурса, который необходимо смонтировать (опционально, по умолчанию используется корневой каталог общего ресурса).
/etc/pve/storage.cfg):
cifs: newCIFS
path /mnt/pve/newCIFS
server 192.168.0.105
share smb_data
smbversion 2.1
# pvesm cifsscan <server> [--username <username>] [--password]
# pvesm add cifs <storagename> --server <server> --share <share> [--username <username>] [--password]

Примечание
# pvesm add cifs newCIFS --server 192.168.0.105 --share smb_data --smbversion 2.1
Примечание
server — IP-адрес или DNS-имя сервера GlusterFS;
server2 — IP-адрес или DNS-имя резервного сервера GlusterFS;
volume — том GlusterFS;
transport — транспорт GlusterFS: tcp, unix или rdma.
/etc/pve/storage.cfg):
glusterfs: gluster-01
server 192.168.0.105
server2 192.168.0.110
volume glustervol
content images,iso

Примечание
# modprobe zfs
#zfsв файле
/etc/modules-load.d/zfs.conf.
pool — пул/файловая система ZFS;
blocksize — размер блока;
sparse — использовать тонкое выделение ресурсов;
mountpoint — точка монтирования пула/файловой системы ZFS. Изменение этого параметра не влияет на свойство точки монтирования набора данных, видимого zfs. По умолчанию /<pool>.
/etc/pve/storage.cfg):
zfspool: vmdata
pool vmdata
content images,rootdir
mountpoint /vmdata
nodes pve03
Примечание
cannot destroy 'data/vm-101-disk-0': dataset is busyЧтобы избежать этой ситуации следует исключить ZFS-диски из области сканирования LVM, добавив в конфигурацию LVM (файл
/etc/lvm/lvm.conf) в секцию devices{} строки:
# Do not scan ZFS zvols (to avoid problems on ZFS zvols snapshots) filter = [ "r|^/dev/zd*|" ] global_filter = [ "r|^/dev/zd*|" ]





zfs и zpool.
# zpool create -f -o ashift=12 <pool> <device1> <device2>
# zpool create -f -o ashift=12 <pool> mirror <device1> <device2>
# zpool create -f -o ashift=12 <pool> mirror <device1>
<device2> mirror <device3> <device4>
# zpool create -f -o ashift=12 <pool> raidz1 <device1> <device2> <device3>
# zpool create -f -o ashift=12 <pool> raidz2 <device1>
<device2> <device3> <device4>
# zpool replace -f <pool> <old device> <new device>
# zfs set compression=on <pool>
# pvesm zfsscan
# zpool create -f vmdata mirror sdb sdc
# zpool list
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
vmdata 17,5G 492K 17,5G - - 0% 0% 1.00x ONLINE -
Просмотреть статус пула:
# zpool status
pool: vmdata
state: ONLINE
config:
NAME STATE READ WRITE CKSUM
vmdata ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
sdb ONLINE 0 0 0
sdc ONLINE 0 0 0
errors: No known data errors
vgname — имя группы томов LVM (должно указывать на существующую группу томов);
base — базовый том. Этот том автоматически активируется перед доступом к хранилищу. Это особенно полезно, когда группа томов LVM находится на удаленном сервере iSCSI;
saferemove — обнуление данных при удалении LV (гарантирует, что при удалении тома все данные будут удалены);
saferemove_throughput — очистка пропускной способности (значение параметра cstream -t).
/etc/pve/storage.cfg):
lvm: vg
vgname vg
content rootdir,images
nodes pve03
shared 0
Примечание




/dev/sdd:
# pvcreate /dev/sdd
Physical volume "/dev/sdd" successfully created.
# vgcreate vg /dev/sdd
Volume group "vg" successfully created
# pvs
PV VG Fmt Attr PSize PFree
/dev/sdd vg lvm2 a-- <18,00g <3,00g
# vgs
VG #PV #LV #SN Attr VSize VFree
vg 1 2 0 wz--n- <18,00g <3,00g
# pvesm lvmscan
vg
# pvesm add lvm myspace --vgname vg --nodes pve03
vgname — имя группы томов LVM (должно указывать на существующую группу томов);
thinpool — название тонкого пула LVM.
/etc/pve/storage.cfg):
lvmthin: vmstore
thinpool vmstore
vgname vmstore
content rootdir,images
nodes pve03
Примечание



# lvcreate -L 80G -T -n vmstore vg
# pvesm lvmthinscan vg
vmstore
# pvesm add lvmthin vmstore --thinpool vmstore --vgname vg --nodes pve03
portal — IP-адрес или DNS-имя сервера iSCSI;
target — цель iSCSI.
/etc/pve/storage.cfg):
iscsi: test1-iSCSI
portal 192.168.0.105
target iqn.2021-7.local.omv:test
content images
Примечание
content noneВ этом случае нельзя будет создавать ВМ с использованием iSCSI LUN напрямую.
Примечание
# systemctl enable --now iscsid

# pvesm scan iscsi <IP-адрес сервера[:порт]>>
# pvesm add iscsi <ID> --portal <Сервер iSCSI> --target <Цель iSCSI> --content none
Примечание
/etc/pve/storage.cfg):
iscsidirect: test1-iSCSi
portal 192.168.0.191
target dc1.test.alt:server.target
monhost — список IP-адресов демона монитора (только если Ceph не работает на кластере PVE);
pool — название пула Ceph (rbd);
username — идентификатор пользователя Ceph (только если Ceph не работает на кластере PVE);
krbd (опционально) — обеспечивает доступ к блочным устройствам rados через модуль ядра krbd.
Примечание
krbd.
/etc/pve/storage.cfg):
rbd: new
content images
krbd 0
monhost 192.168.0.105
pool rbd
username admin

/root узла:
# scp <external cephserver>:/etc/ceph/ceph.client.admin.keyring /root/rbd.keyring
# pvesm add rbd <name> --monhost "10.1.1.20 10.1.1.21 10.1.1.22" --content images --keyring /root/rbd.keyring
/etc/pve/priv/ceph/<STORAGE_ID>.keyring.

Примечание
monhost — список IP-адресов демона монитора (только если Ceph не работает на кластере PVE);
path — локальная точка монтирования (по умолчанию используется /mnt/pve/<STORAGE_ID>/);
username — идентификатор пользователя (только если Ceph не работает на кластере PVE);
subdir — подкаталог CephFS для монтирования (по умолчанию /);
fuse — доступ к CephFS через FUSE (по умолчанию 0).
/etc/pve/storage.cfg):
cephfs: cephfs-external
content backup
monhost 192.168.0.105
path /mnt/pve/cephfs-external
username admin

Примечание
# ceph fs ls
/root узла:
# scp <external cephserver>:/etc/ceph/cephfs.secret /root/cephfs.secret
# pvesm add cephfs <name> --monhost "10.1.1.20 10.1.1.21 10.1.1.22" --content backup --keyring /root/cephfs.secret
/etc/pve/priv/ceph/<STORAGE_ID>.secret.
# ceph auth get-key client.userid > cephfs.secret
server — IP-адрес или DNS-имя сервера резервного копирования;
username — имя пользователя на сервере резервного копирования (например, root@pam, backup_u@pbs);
password — пароль пользователя. Значение будет сохранено в файле /etc/pve/priv/storage/<STORAGE-ID>.pw, доступном только суперпользователю;
datastore — идентификатор хранилища на сервере резервного копирования;
fingerprint — отпечаток TLS-сертификата API Proxmox Backup Server. Требуется, если сервер резервного копирования использует самоподписанный сертификат. Отпечаток можно получить в веб-интерфейсе сервера резервного копирования или с помощью команды proxmox-backup-manager cert info;
encryption-key — ключ для шифрования резервной копии. В настоящее время поддерживаются только те файлы, которые не защищены паролем (без функции получения ключа (kdf)). Ключ будет сохранен в файле /etc/pve/priv/storage/<STORAGE-ID>.enc, доступном только суперпользователю. Опционально;
master-pubkey — открытый ключ RSA, используемый для шифрования копии ключа шифрования (encryption-key) в рамках задачи резервного копирования. Зашифрованная копия будет добавлена к резервной копии и сохранена на сервере резервного копирования для целей восстановления. Опционально, требуется encryption-key.
/etc/pve/storage.cfg):
pbs: pbs_backup
datastore store2
server 192.168.0.123
content backup
fingerprint 42:5d:29:20:…:d1:be:bc:c0:c0:a9:9b:b1:a8:1b
prune-backups keep-all=1
username root@pam

# pvesm add pbs pbs_backup --server 192.168.0.123 --datastore store2 --username root@pam --fingerprint 42:5d:29:20:…:d1:be:bc:c0:c0:a9:9b:b1:a8:1b --password
encryption-key, либо через веб-интерфейс:


/etc/pve/priv/storage/<STORAGE-ID>.enc, который доступен только пользователю root.
Примечание
proxmox-backup-client key. Например, сгенерировать ключ:
# proxmox-backup-client key create --kdf none <path>
Сгенерировать мастер-ключ:
# proxmox-backup-client key create-master-key
Важно
Важно
Примечание
Примечание
Примечание
systool из пакета sysfsutils.
# apt-get install sysfsutils
# systool -c fc_host -A port_name
Class = "fc_host"
Class Device = "host1"
port_name = "0x10000090fa59a61a"
Device = "host1"
Class Device = "host16"
port_name = "0x10000090fa59a61b"
Device = "host16"
# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 59G 0 disk
sdb 8:16 0 931,3G 0 disk
└─mpatha 253:0 0 931,3G 0 mpath
sdc 8:32 0 931,3G 0 disk
└─mpatha 253:0 0 931,3G 0 mpath
sdd 8:48 0 931,3G 0 disk
└─mpatha 253:0 0 931,3G 0 mpath
sde 8:64 0 931,3G 0 disk
└─mpatha 253:0 0 931,3G 0 mpath
В данном примере один LUN на 1000GB виден по четырем путям.
node.startup значение automatic. Значение по умолчанию для параметра node.session.timeo.replacement_timeout составляет 120 секунд. Рекомендуется использовать значение — 15 секунд.
/etc/iscsi/iscsid.conf (по умолчанию). Если iSCSI target уже подключен, то необходимо изменить настройки по умолчанию для конкретной цели в файле /etc/iscsi/nodes/<TARGET>/<PORTAL>/default.
#apt-get install open-iscsi#systemctl enable --now iscsid
/etc/iscsi/iscsid.conf:
node.startup = automatic node.session.timeo.replacement_timeout = 15
#iscsiadm -m discovery -t sendtargets -p <iscsi-target-1-ip>#iscsiadm -m discovery -t sendtargets -p <iscsi-target-2-ip>#iscsiadm -m node --login
/etc/iscsi/iscsid.conf:
node.startup = automatic
/var/lib/iscsi/send_targets/<TargetServer>,<Port>/st_config:
discovery.sendtargets.use_discoveryd = Yes
# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sda 8:0 0 59G 0 disk
sdb 8:16 0 931,3G 0 disk
└─mpatha 253:0 0 931,3G 0 mpath
sdc 8:32 0 931,3G 0 disk
└─mpatha 253:0 0 931,3G 0 mpath
sdd 8:48 0 931,3G 0 disk
└─mpatha 253:0 0 931,3G 0 mpath
sde 8:64 0 931,3G 0 disk
└─mpatha 253:0 0 931,3G 0 mpath
В данном примере один LUN на 1000GB виден по четырем путям.
Примечание
iscsiadm:
# iscsiadm -m node --logout
# iscsiadm -m node --targetname "iscsi-target-1.test.alt:server.target1" --logout
# iscsiadm -m node -R
# iscsiadm -m session
# apt-get install multipath-tools
И запущена служба multipathd:
# systemctl enable --now multipathd && sleep 5; systemctl status multipathd
Примечание
multipath используется для обнаружения и объединения нескольких путей к устройствам.
multipath:
-l — отобразить текущую multipath-топологию, полученную из sysfs и устройства сопоставления устройств;
-ll — отобразить текущую multipath-топологию, собранную из sysfs, устройства сопоставления устройств и всех других доступных компонентов системы;
-f device — удалить указанное multipath-устройство;
-F — удалить все неиспользуемые multipath-устройства;
-w device — удалить WWID указанного устройства из файла wwids;
-W — сбросить файл wwids, чтобы включить только текущие многопутевые устройства;
-r — принудительная перезагрузка multipath-устройства.
# multipath -ll
mpatha (3600c0ff00014f56ee9f3cf6301000000) dm-0 HP,P2000 G3 FC
size=931G features='1 queue_if_no_path' hwhandler='1 alua' wp=rw
|-+- policy='service-time 0' prio=50 status=active
| |- 1:0:0:1 sdb 8:16 active ready running
| `- 16:0:1:1 sde 8:64 active ready running
`-+- policy='service-time 0' prio=10 status=enabled
|- 1:0:1:1 sdc 8:32 active ready running
`- 16:0:0:1 sdd 8:48 active ready running
# multipath -v3
/etc/multipath.conf:
defaults {
find_multipaths yes
user_friendly_names yes
}
user_friendly_names установлено значение no, то для имени multipath-устройства задается значение World Wide Identifier (WWID). Имя устройства будет /dev/mapper/WWID и /dev/dm-X:
#Если для параметраls /dev/mapper/3600c0ff00014f56ee9f3cf6301000000 #lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS sda 8:0 0 59G 0 disk sdb 8:16 0 931,3G 0 disk └─3600c0ff00014f56ee9f3cf6301000000 253:0 0 931,3G 0 mpath sdc 8:32 0 931,3G 0 disk └─3600c0ff00014f56ee9f3cf6301000000 253:0 0 931,3G 0 mpath sdd 8:48 0 931,3G 0 disk └─3600c0ff00014f56ee9f3cf6301000000 253:0 0 931,3G 0 mpath sde 8:64 0 931,3G 0 disk └─3600c0ff00014f56ee9f3cf6301000000 253:0 0 931,3G 0 mpath
user_friendly_names установлено значение yes, то для имени multipath-устройства задаётся алиас (псевдоним), в форме mpathХ. Имя устройства будет /dev/mapper/mpathХ и /dev/dm-X:
#Однако не гарантируется, что имя устройства будет одинаковым на всех узлах, использующих это multipath-устройство.ls /dev/mapper/mpatha #lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS sda 8:0 0 59G 0 disk sdb 8:16 0 931,3G 0 disk └─mpatha 253:0 0 931,3G 0 mpath sdc 8:32 0 931,3G 0 disk └─mpatha 253:0 0 931,3G 0 mpath sdd 8:48 0 931,3G 0 disk └─mpatha 253:0 0 931,3G 0 mpath sde 8:64 0 931,3G 0 disk └─mpatha 253:0 0 931,3G 0 mpath
/dev/mapper/mpatha). Для этого в файл /etc/multipath.conf добавить секции:
blacklist {
wwid .*
}
blacklist_exceptions {
wwid "3600c0ff00014f56ee9f3cf6301000000"
}
Данная настройка предписывает внести в черный список любые найденные устройства хранения данных, за исключением нужного.
multipaths {
multipath {
wwid "3600c0ff00014f56ee9f3cf6301000000"
alias mpatha
}
}
В этом случае устройство всегда будет доступно только по имени /dev/mapper/mpatha. Вместо mpatha можно вписать любое желаемое имя устройства.
Примечание
# /lib/udev/scsi_id -g -u -d /dev/sdb
3600c0ff00014f56ee9f3cf6301000000
Для устройств в одном multipath WWID будут совпадать.
/etc/multipath.conf может также потребоваться внести рекомендованные производителем СХД параметры.
/etc/multipath.conf необходимо перезапустить службу multipathd для активации настроек:
# systemctl restart multipathd.service
Примечание
/etc/multipath.conf на наличие ошибок можно, выполнив команду:
# multipath -t

# apt-get install ocfs2-tools
Примечание
/etc/ocfs2/cluster.conf. Этот файл должен быть одинаков на всех узлах кластера, при изменении в одном месте его нужно скопировать на остальные узлы. При добавлении нового узла в кластер, описание этого узла должно добавлено быть на всех остальных узлах до монтирования раздела ocfs2 с нового узла.
/etc/ocfs2/cluster.conf.
# o2cb_ctl -C -n mycluster -t cluster -a name=mycluster
# o2cb_ctl -C -n <имя_узла> -t node -a number=0 -a ip_address=<IP_узла> -a ip_port=7777 -a cluster=mycluster
/etc/ocfs2/cluster.conf:
cluster: node_count = 3 heartbeat_mode = local name = mycluster node: ip_port = 7777 ip_address = <IP_узла-01> number = 0 name = <имя_узла-01> cluster = mycluster node: ip_port = 7777 ip_address = <IP_узла-02> number = 1 name = <имя_узла-02> cluster = mycluster node: ip_port = 7777 ip_address = <IP_узла-03> number = 2 name = <имя_узла-03> cluster = mycluster
Примечание
/etc/hostname.
/etc/init.d/o2cb:
# /etc/init.d/o2cb configure
Для ручного запуска кластера нужно выполнить:
#/etc/init.d/o2cb loadchecking debugfs... Loading filesystem "ocfs2_dlmfs": OK Creating directory '/dlm': OK Mounting ocfs2_dlmfs filesystem at /dlm: OK #/etc/init.d/o2cb online myclusterchecking debugfs... Setting cluster stack "o2cb": OK Registering O2CB cluster "mycluster": OK Setting O2CB cluster timeouts : OK
/dev/mapper/mpatha-part1 на диске /dev/mapper/mpatha:
# fdisk /dev/mapper/mpatha
# mkfs.ocfs2 -b 4096 -C 4k -L DBF1 -N 3 /dev/mapper/mpatha-part1
mkfs.ocfs2 1.8.7
Cluster stack: classic o2cb
Label: DBF1
…
mkfs.ocfs2 successful
Таблица 39.4. Параметры команды mkfs.ocfs2
|
Параметр
|
Описание
|
|---|---|
-L метка_тома
|
Метка тома, позволяющая его однозначно идентифицировать при подключении на разных узлах. Для изменения метки тома можно использовать утилиту
tunefs.ocfs2
|
-C размер_кластера
|
Размер кластера — это наименьшая единица пространства, выделенная файлу для хранения данных. Возможные значения: 4, 8, 16, 32, 64, 128, 256, 512 и 1024 КБ. Размер кластера невозможно изменить после форматирования тома
|
-N количество_узлов_кластера
|
Максимальное количество узлов, которые могут одновременно монтировать том. Для изменения количества узлов можно использовать утилиту
tunefs.ocfs2
|
-b размер_блока
|
Наименьшая единица пространства, адресуемая ФС. Возможные значения: 512 байт (не рекомендуется), 1 КБ, 2 КБ или 4 КБ (рекомендуется для большинства томов). Размер блока невозможно изменить после форматирования тома
|
Примечание
# dd if=/dev/zero of=/dev/mapper/mpathX bs=512 count=1 conv=notrunc
/mnt/ocfs2):
#mkdir /mnt/ocfs2#mount /dev/mapper/mpatha-part1 /mnt/ocfs2
/etc/fstab строку (каталог /mnt/ocfs2 должен существовать):
/dev/mapper/mpatha-part1 /mnt/ocfs2 ocfs2 _netdev,defaults 0 0Выполнить проверку монтирования:
# mount -a
Результатом выполнения команды должен быть пустой вывод без ошибок.
Примечание
_netdev позволяет монтировать данный раздел только после успешного старта сетевой подсистемы.
Примечание
/etc/fstab по его уникальному идентификатору, а не по имени /dev/mapper/mpatha:
UUID=<uuid> /<каталог> ocfs2 _netdev,defaults 0 0Например, определить UUID uuid разделов:
# blkid
/dev/mapper/mpatha-part1: LABEL="DBF1" UUID="df49216a-a835-47c6-b7c1-6962e9b7dcb6" BLOCK_SIZE="4096" TYPE="ocfs2" PARTUUID="15f9cd13-01"
Добавить монтирование этого UUID в /etc/fstab:
UUID=df49216a-a835-47c6-b7c1-6962e9b7dcb6 /mnt/ocfs2 ocfs2 _netdev,defaults 0 0
# pvesm add dir mpath --path /mnt/ocfs2 --shared 1
или в веб-интерфейсе PVE ( → , нажать кнопку → ):

Примечание
Примечание
/etc/lvm/lvm.conf, например:
filter = [ "a|/dev/mapper/|", "a|/dev/sda.*|", "r|.*|" ]В данном примере принимаются только multipath-устройства и
/dev/sda.*, все остальные устройства отклоняются:
/dev/mapper;
/dev/sda;
# fdisk -l /dev/mapper/mpatha
Disk /dev/mapper/mpatha: 931.32 GiB, 999999995904 bytes, 1953124992 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 1048576 bytes
Disklabel type: dos
Disk identifier: 0x2221951e
Device Boot Start End Sectors Size Id Type
/dev/mapper/mpatha-part1 2048 1953124991 1953122944 931.3G 83 Linux
# pvcreate /dev/mapper/mpatha-part1
Physical volume "/dev/mapper/mpatha-part1" successfully created.
# vgcreate VG1 /dev/mapper/mpatha-part1
Volume group "VG1" successfully created
# pvs
PV VG Fmt Attr PSize PFree
/dev/mapper/mpatha-part1 VG1 lvm2 a-- 931.32g 931.32g
# pvesm lvmscan
VG1

# pvesm add lvm mpath-lvm --vgname VG1 --content images,rootdir

# pvs
PV VG Fmt Attr PSize PFree
/dev/mapper/mpatha-part1 VG1 lvm2 a-- 931.32g 931.32g
# vgs
VG #PV #LV #SN Attr VSize VFree
VG1 1 0 0 wz--n- 931.32g 931.32g
# lvcreate -L 100G -T -n vmstore VG1
Logical volume "vmstore" created.
# pvesm lvmthinscan VG1
vmstore

# pvesm add lvmthin mpath-lvmthin --thinpool vmstore --vgname VG1 --nodes pve01

# multipath -l
mpatha (3600c0ff00014f56ee9f3cf6301000000) dm-0 HP,P2000 G3 FC
size=465G features='1 queue_if_no_path' hwhandler='1 alua' wp=rw
|-+- policy='service-time 0' prio=0 status=active
| |- 1:0:1:1 sdc 8:32 active undef running
| `- 16:0:1:1 sde 8:64 active undef running
`-+- policy='service-time 0' prio=0 status=enabled
|- 1:0:0:1 sdb 8:16 active undef running
`- 16:0:0:1 sdd 8:48 active undef running
# echo 1 > /sys/block/<path_device>/device/rescan
#echo 1 > /sys/block/sdb/device/rescan#echo 1 > /sys/block/sdc/device/rescan#echo 1 > /sys/block/sdd/device/rescan#echo 1 > /sys/block/sde/device/rescan
# dmesg -wHT

# multipathd -k"resize map 3600c0ff00014f56ee9f3cf6301000000"
где 3600c0ff00014f56ee9f3cf6301000000 — WWID multipath-устройства;
# pvresize /dev/mapper/mpatha
# resize2fs /dev/mapper/mpatha
Примечание
pveceph — инструмент для установки и управления службами Ceph на узлах PVE.
ls, find и т.д.), не создавая огромной нагрузки на кластер хранения Ceph.
Таблица 39.5. Системные требования к оборудованию для Ceph
|
Процесс
|
Критерий
|
Требования
|
|---|---|---|
|
Монитор Ceph
|
Процессор
|
2 ядра минимум, 4 рекомендуется
|
|
ОЗУ
|
5ГБ+ (большим/производственным кластерам нужно больше)
|
|
|
Жёсткий диск
|
100 ГБ на демон, рекомендуется SSD
|
|
|
Сеть
|
1 Гбит/с (рекомендуется 10+ Гбит/с)
|
|
|
Менеджер Ceph
|
Процессор
|
1 ядро
|
|
ОЗУ
|
1 ГБ
|
|
|
OSD Ceph
|
Процессор
|
|
|
ОЗУ
|
|
|
|
Жёсткий диск
|
1 SSD накопитель на демон
|
|
|
Сеть
|
1 Гбит/с (рекомендуется агрегированная сеть 10+ Гбит/с)
|
|
|
Сервер метаданных Ceph
|
Процессор
|
2 ядра
|
|
ОЗУ
|
2 ГБ+ (для производственных кластеров больше)
|
|
|
Жёсткий диск
|
1 ГБ на демон, рекомендуется SSD
|
|
|
Сеть
|
1 Гбит/с (рекомендуется 10+ Гбит/с)
|
|
Примечание


Примечание

# pveceph init --network 192.168.0.0/24
/etc/pve/ceph.conf с выделенной сетью для Ceph. Файл /etc/pve/ceph.conf автоматически распространяется на все узлы PVE с помощью pmxcfs. Будет также создана символическая ссылка /etc/ceph/ceph.conf, которая указывает на файл /etc/pve/ceph.conf. Таким образом, можно запускать команды Ceph без необходимости указывать файл конфигурации.
Примечание

# pveceph mon create
# pveceph mon destroy <mon_id>
Примечание


# pveceph mgr create
# pveceph mgr destroy <mgr_id>
# ceph-volume lvm zap /dev/[X] --destroy
Предупреждение

# pveceph osd create /dev/[X]
-db_dev и -wal_dev:
# pveceph osd create /dev/[X] -db_dev /dev/[Y] -wal_dev /dev/[Z]
Если диск для журналирования не указан, WAL размещается вместе с DB.
-db_size и -wal_size соответственно. Если эти параметры не указаны, будут использоваться следующие значения (по порядку):
Примечание
#Первая команда указывает Ceph не включать OSD в распределение данных. Вторая команда останавливает службу OSD. До этого момента данные не теряются.ceph osd out <ID>#systemctl stop ceph-osd@<ID>.service
-cleanup, чтобы дополнительно уничтожить таблицу разделов):
# pveceph osd destroy <ID>
Предупреждение

pveceph pool create):
-size) — количество реплик на объект. Ceph всегда пытается иметь указанное количество копий объекта (по умолчанию 3);
-pg_autoscale_mode) — автоматический режим масштабирования PG пула. Если установлено значение warn, выводится предупреждающее сообщение, если в пуле неоптимальное количество PG (по умолчанию warn);
-add_storages) — настроить хранилище с использованием нового пула. Доступно только при создании пула (по умолчанию true);
-min_size) — минимальное количество реплик для объекта. Ceph отклонит ввод-вывод в пуле, если в PG меньше указанного количества реплик (по умолчанию 2);
-crush_rule) — правило, используемое для сопоставления размещения объектов в кластере. Эти правила определяют, как данные размещаются в кластере;
-pg_num) — количество групп размещения, которые должен иметь пул в начале (по умолчанию 128);
-target_size_ratio) — соотношение ожидаемых данных в пуле. Автомасштабирование PG использует соотношение относительно других наборов соотношений. Данный параметр имеет приоритет над целевым размером, если установлены оба;
-target_size) — предполагаемый объем данных, ожидаемых в пуле. Автомасштабирование PG использует этот размер для оценки оптимального количества PG;
-pg_num_min) — минимальное количество групп размещения. Этот параметр используется для точной настройки нижней границы количества PG для этого пула. Автомасштабирование PG не будет объединять PG ниже этого порогового значения.
Примечание
min_size равным 1. Реплицированный пул с min_size равным 1 разрешает ввод-вывод для объекта, при наличии только одной реплики, что может привести к потере данных, неполным PG или ненайденным объектам.
# pveceph pool create <pool-name> -add_storages
size), тогда как в пуле EC данные разбиваются на k фрагментов данных с дополнительными m фрагментами кодирования (проверки). Эти фрагменты кодирования можно использовать для воссоздания данных, если фрагменты данных отсутствуют.
m определяет, сколько OSD может быть потеряно без потери данных. Общее количество хранимых объектов равно k + m.
pveceph. При планировании пула EC необходимо учитывать тот факт, что они работают иначе, чем реплицированные пулы.
min_size для пула EC зависит от параметра m. Если m = 1, значение min_size для пула EC будет равно k. Если m > 1, значение min_size будет равно k + 1. В документации Ceph рекомендуется использовать консервативное значение min_size, равное k + 2.
min_size OSD, любой ввод-вывод в пул будет заблокирован до тех пор, пока снова не будет достаточно доступных OSD.
Примечание
min_size, так как он определяет, сколько OSD должно быть доступно. В противном случае ввод-вывод будет заблокирован.
k = 2 и m = 1 будет иметь size = 3, min_size = 2 и останется работоспособным, если один OSD выйдет из строя. Если пул настроен с k = 2, m = 2, будет иметь size = 4 и min_size = 3 и останется работоспособным, если один OSD будет потерян.
# pveceph pool create <pool-name> --erasure-coding k=<integer> ,m=<integer> \
[,device-class=<class>] [,failure-domain=<domain>] [,profile=<profile>]
--add_storages 0. При настройке конфигурации хранилища вручную необходимо будет задать параметр data-pool, только тогда пул EC будет использоваться для хранения объектов данных.
Примечание
--size, --min_size и --crush_rule будут использоваться для реплицированного пула метаданных, но не для пула данных EC. Если нужно изменить min_size в пуле данных, это можно будет сделать позже. Параметры size и crush_rule нельзя изменить в пулах EC.
profile. Например:
# pveceph pool create <pool-name> --erasure-coding profile=<profile-name>
Существующий пул EC можно добавить в качестве хранилища в PVE:
# pvesm add rbd <storage-name> --pool <replicated-pool> --data-pool <ec-pool>
Примечание
keyring и monhost.

# pveceph pool destroy <name>
-cleanup, чтобы дополнительно уничтожить таблицу разделов):
# pveceph osd destroy <ID>
Чтобы также удалить связанное хранилище следует указать опцию -remove_storages.
Примечание
Примечание
# ceph mgr module enable pg_autoscaler
Список запущенных модулей можно посмотреть, выполнив команду:
# ceph mgr module ls
warn — предупреждение о работоспособности выдается, если предлагаемое значение pg_num слишком сильно отличается от текущего значения;
on — pg_num настраивается автоматически без необходимости ручного вмешательства;
off — автоматические корректировки pg_num не производятся, и предупреждение не выдается, если количество PG не является оптимальным.
target_size, target_size_ratio и pg_num_min.

# ceph osd crush tree --show-shadow
ID CLASS WEIGHT TYPE NAME
-6 nvme 0.09760 root default~nvme
-5 nvme 0 host pve01~nvme
-9 nvme 0.04880 host pve02~nvme
1 nvme 0.04880 osd.1
-12 nvme 0.04880 host pve03~nvme
2 nvme 0.04880 osd.2
-2 ssd 0.04880 root default~ssd
-4 ssd 0.04880 host pve01~ssd
0 ssd 0.04880 osd.0
-8 ssd 0 host pve02~ssd
-11 ssd 0 host pve03~ssd
-1 0.14639 root default
-3 0.04880 host pve01
0 ssd 0.04880 osd.0
-7 0.04880 host pve02
1 nvme 0.04880 osd.1
-10 0.04880 host pve03
2 nvme 0.04880 osd.2
# ceph osd crush rule create-replicated <rule-name> <root> <failure-domain> <class>
Где:
rule-name — имя политики;
root — корень отказа (значение default — корень Ceph);
failure-domain — домен отказа, на котором должны распределяться объекты (обычно host);
class — какой тип хранилища резервных копий OSD использовать (например, nvme, ssd).
# ceph osd crush rule create-replicated my_rule default host nvme
# ceph osd crush rule dump
# ceph osd pool set <pool-name> crush_rule <rule-name>
Примечание
Примечание
hotstandby при создании сервера, или, после его создания, установив в соответствующем разделе MDS в /etc/pve/ceph.conf параметр:
mds standby replay = trueЕсли этот параметр включен, указанный MDS будет находиться в состоянии warm, опрашивая активный, чтобы в случае возникновения каких-либо проблем быстрее взять на себя управление.
Примечание

# pveceph mds create

pveceph, например:
# pveceph fs create --pg_num 128 --add-storage
--add-storage (опция Добавить как хранилище) добавит CephFS в конфигурацию хранилища PVE.
Предупреждение
# umount /mnt/pve/<STORAGE-NAME>
где <STORAGE-NAME> — имя хранилища CephFS в PVE.
# pveceph stop --service mds.NAME
чтобы остановить их, или команду:
# pveceph mds destroy NAME
чтобы уничтожить их.
# pveceph fs destroy NAME --remove-storages --remove-pools
Это автоматически уничтожит базовые пулы Ceph, а также удалит хранилища из конфигурации PVE.
Примечание
size + 1. Причина этого в том, что балансировщик объектов Ceph CRUSH по умолчанию использует полный узел в качестве «домена отказа».
# ceph osd out osd.<id>
# ceph osd safe-to-destroy osd.<id>
#systemctl stop ceph-osd@<id>.service#pveceph osd destroy <id>
fstrim (discard) на ВМ и контейнерах. Это освобождает блоки данных, которые файловая система больше не использует. В результате снижается нагрузка на ресурсы. Большинство современных ОС регулярно отправляют такие команды discard своим дискам. Нужно только убедиться, что ВМ включают опцию disk discard.
#Эти команды также предоставляют обзор действий, которые необходимо предпринять если кластер находится в неработоспособном состоянии.ceph -s# однократный вывод #ceph -w# непрерывный вывод изменений статуса
/var/log/ceph/.
pvesr.
Примечание
pvesr.


# pvesr create-local-job 214-0 pve03 --schedule "*/10" --rate 10
# pvesr disable 214-0
# pvesr list
JobID Target Schedule Rate Enabled
213-0 local/pve02 */1:00 - yes
214-0 local/pve03 */10 10 no
# pvesr status
JobID Enabled Target LastSync NextSync Duration FailCount State
213-0 Yes local/pve02 2025-02-26_10:10:48 2025-02-26_11:00:00 2.455654 0 OK
# pvesr enable 214-0
# pvesr update 214-0 --schedule '*/1:00'
Примечание
# pvecm status
# pvecm expected 1
Примечание
#mv /etc/pve/nodes/pve02/qemu-server/100.conf /etc/pve/nodes/pve03/qemu-server/100.conf#mv /etc/pve/nodes/pve02/lxc/200.conf /etc/pve/nodes/pve03/lxc/200.conf
#qm start 100#pct start 200
/etc/net/ifaces.

Примечание

ovs_ports;
en для сетевых устройств Ethernet. Следующие символы зависят от драйвера устройства и того факта, какая схема подходит первой:



Примечание

#mkdir /etc/net/ifaces/vmbr1#cat<<EOF > /etc/net/ifaces/vmbr1/options BOOTPROTO=static CONFIG_IPV4=yes HOST= ONBOOT=yes TYPE=bri EOF
Примечание
HOST.
#mkdir /etc/net/ifaces/vmbr1#cp /etc/net/ifaces/enp0s8/* /etc/net/ifaces/vmbr1/#rm -f /etc/net/ifaces/enp0s8/{i,r}*#cat<<EOF > /etc/net/ifaces/vmbr1/options BOOTPROTO=static CONFIG_WIRELESS=no CONFIG_IPV4=yes HOST='enp0s8' ONBOOT=yes TYPE=bri EOF
/etc/net/ifaces/enp0s8/ipv4address.
#Пример настройки моста vmbr1 на интерфейсе enp0s8:mkdir /etc/net/ifaces/vmbr1#cat<<EOF > /etc/net/ifaces/vmbr1/options BOOTPROTO=static CONFIG_IPV4=yes ONBOOT=yes TYPE=ovsbr EOF
#mkdir /etc/net/ifaces/vmbr1#cp /etc/net/ifaces/enp0s8/* /etc/net/ifaces/vmbr1/#rm -f /etc/net/ifaces/enp0s8/{i,r}*#cat<<EOF > /etc/net/ifaces/vmbr1/options BOOTPROTO=static CONFIG_IPV4=yes ONBOOT=yes HOST='enp0s8' TYPE=ovsbr EOF
# systemctl restart network
или перезагрузить узел:
# reboot
Таблица 41.1. Режимы агрегации Linux Bond
|
Режим
|
Название
|
Описание
|
Отказоустойчивость
|
Балансировка нагрузки
|
|---|---|---|---|---|
|
balance-rr или mode=0
|
Round-robin
|
Режим циклического выбора активного интерфейса для трафика. Пакеты последовательно передаются и принимаются через каждый интерфейс один за другим. Данный режим не требует применения специальных коммутаторов.
|
Да
|
Да
|
|
active-backup или mode=1
|
Active Backup
|
В этом режиме активен только один интерфейс, остальные находятся в режиме горячей замены. Если активный интерфейс выходит из строя, его заменяет резервный. MAC-адрес интерфейса виден извне только на одном сетевом адаптере, что предотвращает путаницу в сетевом коммутаторе. Это самый простой режим, работает с любым оборудованием, не требует применения специальных коммутаторов.
|
Да
|
Нет
|
|
balance-xor или mode=2
|
XOR
|
Один и тот же интерфейс работает с определённым получателем. Передача пакетов распределяется между интерфейсами на основе формулы ((MAC-адрес источника) XOR (MAC-адрес получателя)) % число интерфейсов. Режим не требует применения специальных коммутаторов. Этот режим обеспечивает балансировку нагрузки и отказоустойчивость.
|
Да
|
Да
|
|
broadcast или mode=3
|
Широковещательный
|
Трафик идёт через все интерфейсы одновременно.
|
Да
|
Нет
|
|
LACP (802.3ad) или mode=4
|
Агрегирование каналов по стандарту IEEE 802.3ad
|
В группу объединяются одинаковые по скорости и режиму интерфейсы. Все физические интерфейсы используются одновременно в соответствии со спецификацией IEEE 802.3ad. Для реализации этого режима необходима поддержка на уровне драйверов сетевых карт и коммутатор, поддерживающий стандарт IEEE 802.3ad (коммутатор требует отдельной настройки).
|
Да
|
Да
|
|
balance-tlb или mode=5
|
Адаптивная балансировка нагрузки при передаче
|
Исходящий трафик распределяется в соответствии с текущей нагрузкой (с учетом скорости) на интерфейсах (для данного режима необходима его поддержка в драйверах сетевых карт). Входящие пакеты принимаются только активным сетевым интерфейсом.
|
Да
|
Да (исходящий трафик)
|
|
balance-alb или mode=6
|
Адаптивная балансировка нагрузки
|
Включает в себя балансировку исходящего трафика, плюс балансировку на приём (rlb) для IPv4 трафика и не требует применения специальных коммутаторов (балансировка на приём достигается на уровне протокола ARP, перехватом ARP ответов локальной системы и перезаписью физического адреса на адрес одного из сетевых интерфейсов, в зависимости от загрузки).
|
Да
|
Да
|
xmit_hash_policy).
Таблица 41.2. Режимы выбора каналов при организации балансировки нагрузки
|
Режим
|
Описание
|
|---|---|
|
layer2
|
Канал для отправки пакета однозначно определяется комбинацией MAC-адреса источника и MAC-адреса назначения. Весь трафик между определённой парой узлов всегда идёт по определённому каналу. Алгоритм совместим с IEEE 802.3ad. Этот режим используется по умолчанию.
|
|
layer2+3
|
Канал для отправки пакета определяется по совокупности MAC- и IP-адресов источника и назначения. Трафик между определённой парой IP-хостов всегда идёт по определённому каналу (обеспечивается более равномерная балансировка трафика, особенно в случае, когда большая его часть передаётся через промежуточные маршрутизаторы). Для протоколов 3 уровня, отличных от IP, данный алгоритм равносилен layer2. Алгоритм совместим с IEEE 802.3ad.
|
|
layer3+4
|
Канал для отправки пакета определяется по совокупности IP-адресов и номеров портов источника и назначения (трафик определённого узла может распределяться между несколькими каналами, но пакеты одного и того же TCP/UDP-соединения всегда передаются по одному и тому же каналу). Для фрагментированных пакетов TCP и UDP, а также для всех прочих протоколов 4 уровня, учитываются только IP-адреса. Для протоколов 3 уровня, отличных от IP, данный алгоритм равносилен layer2. Алгоритм не полностью совместим с IEEE 802.3ad.
|
options, ipv4address. В файле options следует указать тип интерфейса (TYPE) bond, в переменной HOST перечислить родительские интерфейсы, которые будут входить в агрегированный интерфейс, в переменной BONDMODE указать режим (по умолчанию 0), а опции для модуля ядра bonding — в BONDOPTIONS.
Примечание
Таблица 41.3. Параметры OVS Bond
|
Параметр
|
Описание
|
|---|---|
|
bond_mode=active-backup
|
В этом режиме активен только один интерфейс, остальные находятся в режиме горячей замены. Если активный интерфейс выходит из строя, его заменяет резервный. MAC-адрес интерфейса виден извне только на одном сетевом адаптере, что предотвращает путаницу в сетевом коммутаторе. Это самый простой режим, работает с любым оборудованием, не требует применения специальных коммутаторов.
|
|
bond_mode=balance-slb
|
Режим простой балансировки на основе MAC и VLAN. В этом режиме нагрузка трафика на интерфейсы постоянно измеряется, и если один из интерфейсов сильно загружен, часть трафика перемещается на менее загруженные интерфейсы. Параметр
bond-rebalance-interval определяет, как часто OVS должен выполнять измерение нагрузки трафика (по умолчанию 10 секунд). Этот режим не требует какой-либо специальной настройки на коммутаторах.
|
|
bond_mode=balance-tcp
|
Этот режим выполняет балансировку нагрузки, принимая во внимание данные уровней 2-4 (например, MAC-адрес, IP -адрес и порт TCP). На коммутаторе должен быть настроен LACP. Этот режим похож на режим mode=4 Linux Bond. Всегда, когда это возможно, рекомендуется использовать этот режим
|
|
lacp=[active|passive|off]
|
Управляет поведением протокола управления агрегацией каналов (LACP). На коммутаторе должен быть настроен протокол LACP. Если коммутатор не поддерживает LACP, необходимо использовать
bond_mode=balance-slb или bond_mode=active-backup.
|
|
other-config:lacp-fallback-ab=true
|
Устанавливает поведение LACP для переключения на
bond_mode=active-backup в качестве запасного варианта
|
|
other_config:lacp-time=[fast|slow]
|
Определяет, с каким интервалом управляющие пакеты LACPDU отправляются по каналу LACP: каждую секунду (fast) или каждые 30 секунд (slow). По умолчанию slow
|
|
other_config:bond-detect-mode=[miimon|carrier]
|
Режим определения состояния канала. По умолчанию carrier
|
|
other_config:bond-miimon-interval=100
|
Устанавливает периодичность MII мониторинга в миллисекундах
|
|
other_config:bond_updelay=1000
|
Задает время задержки в миллисекундах, перед тем как поднять линк при обнаружении восстановления канала
|
|
other_config:bond-rebalance-interval=10000
|
Устанавливает периодичность выполнения измерения нагрузки трафика в миллисекундах (по умолчанию 10 секунд).
|

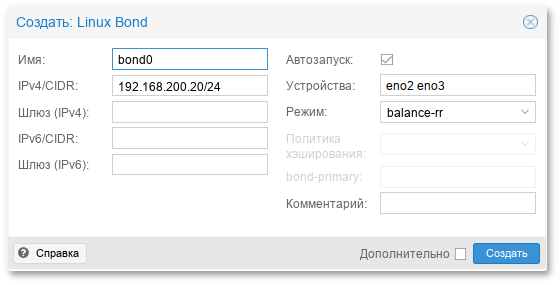
Примечание

#где:mkdir /etc/net/ifaces/bond0#rm -f /etc/net/ifaces/eno1/{i,r}*#rm -f /etc/net/ifaces/eno2/{i,r}*#cat<<EOF > /etc/net/ifaces/bond0/options BOOTPROTO=static CONFIG_WIRELESS=no CONFIG_IPV4=yes HOST='eno1 eno2' ONBOOT=yes TYPE=bond BONDOPTIONS='miimon=100' BONDMODE=0 EOF
BONDMODE=1 — режим агрегации Round-robin;
HOST='eno1 eno2' — интерфейсы, которые будут входить в объединение;
miimon=100 — определяет, как часто производится мониторинг MII (Media Independent Interface).
/etc/net/ifaces/bond0/ipv4address, указать IP-адрес для интерфейса bond0:
# echo "192.168.200.20/24" > /etc/net/ifaces/bond0/ipv4address
# systemctl restart network




Примечание
bond0 и нажать кнопку :





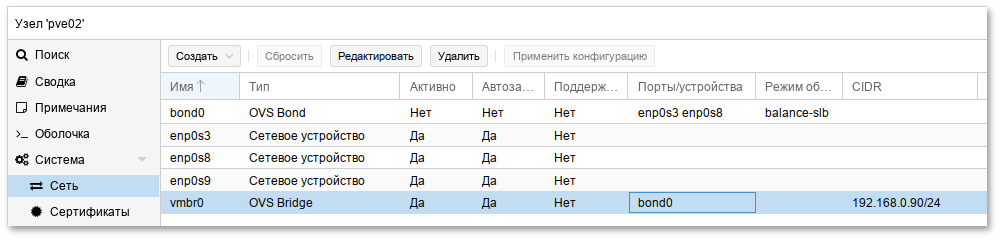
#где:mkdir /etc/net/ifaces/bond0#cat<<EOF > /etc/net/ifaces/bond0/options BOOTPROTO=static CONFIG_WIRELESS=no CONFIG_IPV4=yes HOST='enp0s3 enp0s8' ONBOOT=yes TYPE=bond BONDOPTIONS='xmit_hash_policy=layer2+3 lacp_rate=1 miimon=100' BONDMODE=4 EOF
BONDMODE=4 — режим агрегации LACP (802.3ad);
HOST='enp0s3 enp0s8' — интерфейсы, которые будут входить в объединение;
xmit_hash_policy=layer2+3 — определяет режим выбора каналов;
lacp_rate=1 — определяет, что управляющие пакеты LACPDU отправляются по каналу LACP каждую секунду;
miimon=100 — определяет, как часто производится мониторинг MII (Media Independent Interface).
/etc/net/ifaces/vmbr0/options) в опции HOST указать интерфейс bond0:
BOOTPROTO=static BRIDGE_OPTIONS="stp_state 0" CONFIG_IPV4=yes HOST='bond0' ONBOOT=yes TYPE=bri
# systemctl restart network
# ovs-vsctl show
6b1add02-fb20-48e6-b925-260bf92fa889
Bridge vmbr0
Port enp0s3
Interface enp0s3
Port vmbr0
Interface vmbr0
type: internal
ovs_version: "2.17.6"
/etc/net/ifaces/enp0s3/options) к виду:
TYPE=eth CONFIG_WIRELESS=no BOOTPROTO=static CONFIG_IPV4=yes
#где:mkdir /etc/net/ifaces/bond0#cat<<EOF > /etc/net/ifaces/bond0/options BOOTPROTO=static BRIDGE=vmbr0 CONFIG_IPV4=yes HOST='enp0s3 enp0s8' OVS_OPTIONS='other_config:bond-miimon-interval=100 bond_mode=balance-slb' TYPE=ovsbond EOF
bond_mode=balance-slb — режим агрегации;
HOST='enp0s3 enp0s8' — интерфейсы, которые будут входить в объединение;
BRIDGE=vmbr0 — мост, в который должен добавиться созданный интерфейс;
other_config:bond-miimon-interval=100 — определяет, как часто производится мониторинг MII (Media Independent Interface).
HOST настроек моста vmbr0 (файл /etc/net/ifaces/vmbr0/options) указать bond0:
BOOTPROTO=static CONFIG_IPV4=yes HOST=bond0 ONBOOT=yes TYPE=ovsbr
# systemctl restart network
# ovs-vsctl show
6b1add02-fb20-48e6-b925-260bf92fa889
Bridge vmbr0
Port bond0
Interface enp0s3
Interface enp0s8
Port vmbr0
Interface vmbr0
type: internal
ovs_version: "2.17.6"
Примечание
Trunk выставляется на это новом интерфейсе.


#В опцииmkdir /etc/net/ifaces/enp0s8.100#cat<<EOF > /etc/net/ifaces/enp0s8.100/options BOOTPROTO=static CONFIG_WIRELESS=no CONFIG_IPV4=yes HOST=enp0s8 ONBOOT=yes TYPE=vlan VID=100 EOF
HOST нужно указать тот интерфейс, на котором будет настроен VLAN.
#В опцииmkdir /etc/net/ifaces/vmbr1#cat<<EOF > /etc/net/ifaces/vmbr1/options BOOTPROTO=static CONFIG_WIRELESS=no CONFIG_IPV4=yes HOST='enp0s8.100' ONBOOT=yes TYPE=bri EOF
HOST нужно указать VLAN-интерфейс.
/etc/net/ifaces/vmbr1/ipv4address, если это необходимо, можно указать IP-адрес для интерфейса моста:
# echo "192.168.10.3/24" > /etc/net/ifaces/vmbr1/ipv4address
# systemctl restart network




Примечание

# pveam update
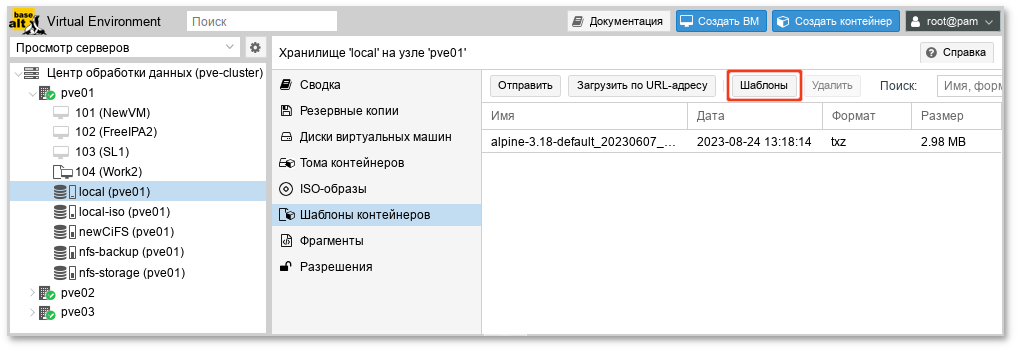
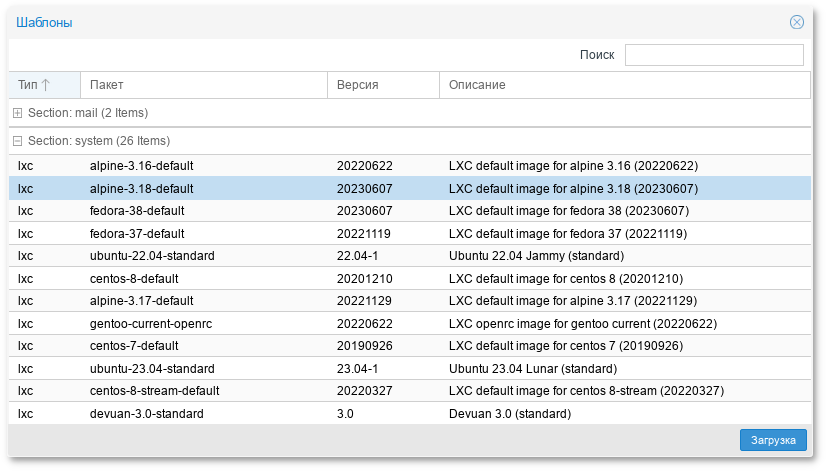
# pveam update
update successful
# pveam available
mail proxmox-mailgateway-7.3-standard_7.3-1_amd64.tar.zst
mail proxmox-mailgateway-8.0-standard_8.0-1_amd64.tar.zst
system almalinux-8-default_20210928_amd64.tar.xz
system almalinux-9-default_20221108_amd64.tar.xz
system alpine-3.16-default_20220622_amd64.tar.xz
…
# pveam download local almalinux-9-default_20221108_amd64.tar.xz
# pveam list local
NAME SIZE
local:vztmpl/almalinux-9-default_20221108_amd64.tar.xz 97.87MB
Таблица 42.1. Каталоги локального хранилища
|
Каталог
|
Тип шаблона
|
|---|---|
/var/lib/vz/template/iso/
|
ISO-образы
|
/var/lib/vz/template/cache/
|
Шаблоны контейнеров LXC
|
Таблица 42.2. Каталоги общих хранилищ
|
Каталог
|
Тип шаблона
|
|---|---|
/mnt/pve/<storage_name>/template/iso/
|
ISO-образы
|
/mnt/pve/<storage_name>/template/cache/
|
Шаблоны контейнеров LXC
|


Примечание




Примечание




Примечание








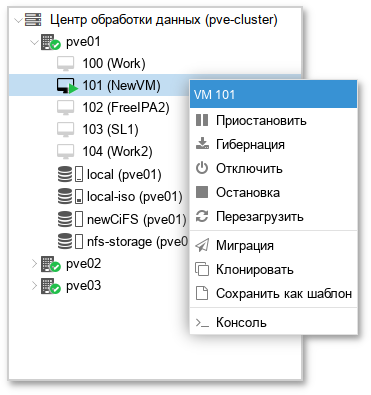
# qm set <vmid> -onboot 1

Примечание
Порядок запуска и отключения всегда будут запускаться после тех, для которых этот параметр установлен . Кроме того, этот параметр может применяться только для ВМ, работающих на одном хосте, а не в масштабе кластера.


qmqm — это инструмент для управления ВМ Qemu/KVM в PVE. Утилиту qm можно использовать для создания/удаления ВМ, для управления работой ВМ (запуск/остановка/приостановка/возобновление), для установки параметров в соответствующем конфигурационном файле, а также для создания виртуальных дисков.
qm <КОМАНДА> [АРГУМЕНТЫ] [ОПЦИИ]Чтобы просмотреть доступные для управления ВМ команды можно выполнить следующую команду:
# qm help
qm.
Таблица 43.1. Команды qm
|
Команда
|
Описание
|
|---|---|
qm agent
|
Псевдоним для
qm guest cmd
|
qm block <vmid>
|
Заблокировать ВМ.
|
qm cleanup <vmid> <clean-shutdown> <guest-requested>
|
Очищает ресурсы, такие как сенсорные устройства, vgpu и т.д. Вызывается после выключения, сбоя ВМ и т. д.
|
qm clone <vmid> <newid> [ОПЦИИ]
|
Создать копию ВМ/шаблона.
|
qm cloudinit dump <vmid> <type>
|
Получить автоматически сгенерированную конфигурацию cloud-init.
|
qm cloudinit pending <vmid>
|
Получить конфигурацию cloud-init с текущими и ожидающими значениями.
|
qm cloudinit update <vmid>
|
Восстановить и изменить диск конфигурации cloud-init.
|
qm config <vmid> <ОПЦИИ>
|
Вывести конфигурацию ВМ с применёнными ожидающими изменениями конфигурации. Для вывода текущей конфигурации следует указать параметр
current.
|
qm create <vmid> <ОПЦИИ>
|
Создать или восстановить ВМ.
Некоторые опции:
|
qm delsnapshot <vmid> <snapname> <ОПЦИИ>
|
Удалить снимок ВМ.
|
qm destroy <vmid> [ОПЦИИ]
|
Уничтожить ВМ и все её тома (будут удалены все разрешения, специфичные для ВМ).
|
qm disk import <vmid> <source> <storage> [ОПЦИИ]
|
Импортировать образ внешнего диска в неиспользуемый диск ВМ. Формат образа должен поддерживаться qemu-img.
|
qm disk move <vmid> <disk> <storage> [ОПЦИИ]
|
Переместить том в другое хранилище или в другую ВМ.
|
qm disk rescan [ОПЦИИ]
|
Пересканировать все хранилища и обновить размеры дисков и неиспользуемые образы дисков.
|
qm disk resize <vmid> <disk> <size> [ОПЦИИ]
|
Увеличить размер диска.
|
qm disk unlink <vmid> --idlist <строка> [ОПЦИИ]
|
Отсоединить/удалить образы дисков.
|
qm guest cmd <vmid> <команда>
|
Выполнить команды гостевого агента QEMU.
|
qm guest exec <vmid> [<extra-args>] [ОПЦИИ]
|
Выполнить данную команду через гостевой агент.
|
qm guest exec-status <vmid> <pid>
|
Получить статус данного pid, запущенного гостевым агентом.
|
qm guest passwd <vmid> <username> [ОПЦИИ]
|
Установить пароль для данного пользователя.
|
qm help [extra-args] [ОПЦИИ]
|
Показать справку по указанной команде.
|
qm importdisk
|
Псевдоним для
qm disk import.
|
qm importovf <vmid> <manifest> <storage> [ОПЦИИ]
|
Создать новую ВМ, используя параметры, считанные из манифеста OVF.
|
qm list [ОПЦИИ]
|
Вывести список ВМ узла.
|
qm listsnapshot <vmid>
|
Вывести список снимков ВМ.
|
qm migrate <vmid> <target> [ОПЦИИ]
|
Перенос ВМ. Создаёт новую задачу миграции.
|
qm monitor <vmid>
|
Войти в интерфейс монитора QEMU.
|
qm move-disk
|
Псевдоним для
qm disk move.
|
qm move_disk
|
Псевдоним для
qm disk move.
|
qm nbdstop <vmid>
|
Остановить встроенный сервер NBD.
|
qm pending <vmid>
|
Получить конфигурацию ВМ с текущими и ожидающими значениями.
|
qm reboot <vmid> [ОПЦИИ]
|
Перезагрузить ВМ. Применяет ожидающие изменения.
|
qm remote-migrate <vmid> [<target-vmid>] <target-endpoint> --target-bridge <строка> --target-storage <строка> [ОПЦИИ]
|
Перенос ВМ в удалённый кластер. Создаёт новую задачу миграции. ЭКСПЕРИМЕНТАЛЬНАЯ функция!
|
qm rescan
|
Псевдоним для
qm disk rescan.
|
qm reset <vmid> [ОПЦИИ]
|
Сбросить ВМ.
|
qm resize
|
Псевдоним для
qm disk resize.
|
qm resume <vmid> [ОПЦИИ]
|
Возобновить работу ВМ.
|
qm rollback <vmid> <snapname> [ОПЦИИ]
|
Откат состояния ВМ до указанного снимка.
|
qm sendkey <vmid> <ключ> [ОПЦИИ]
|
Послать нажатия клавиш на ВМ.
|
qm set <vmid> [ОПЦИИ]
|
Установить параметры ВМ.
Некоторые опции:
|
qm showcmd <vmid> [ОПЦИИ]
|
Показать командную строку, которая используется для запуска ВМ (информация для отладки).
|
qm shutdown <vmid> [ОПЦИИ]
|
Выключение ВМ (эмуляция нажатия кнопки питания). Гостевой ОС будет отправлено событие ACPI.
|
qm snapshot <vmid> <snapname> [ОПЦИИ]
|
Сделать снимок ВМ.
|
qm start <vmid> [ОПЦИИ]
|
Запустить ВМ.
|
qm status <vmid> [ОПЦИИ]
|
Показать статус ВМ.
|
qm stop <vmid> [ОПЦИИ]
|
Останов ВМ (эмуляция выдергивания вилки). Процесс qemu немедленно завершается.
|
qm suspend <vmid> [ОПЦИИ]
|
Приостановить ВМ.
|
qm template <vmid> [ОПЦИИ]
|
Создать шаблон.
|
qm terminal <vmid> [ОПЦИИ]
|
Открыть терминал с помощью последовательного устройства (на ВМ должно быть настроено последовательное устройство, например, Serial0: Socket).
|
qm unlink
|
Псевдоним для
qm disk unlink.
|
qm unlock <vmid>
|
Разблокировать ВМ.
|
qm vncproxy <vmid>
|
Проксировать VNC-трафик ВМ на стандартный ввод/вывод.
|
qm wait <vmid> [ОПЦИИ]
|
Подождать, пока ВМ не будет остановлена.
|
qm:
# qm create 300 -ide0 local-lvm:21 -net0 e1000 -cdrom local:iso/alt-server-10.2-x86_64.iso
# qm start 109
# qm shutdown 109 && qm wait 109
# qm sendkey 109 ctrl-shift
#qm monitor 109qm>help
/var/lib/vz/snippets) и добавить его к ВМ или контейнеру.
Примечание
hookscript:
#где <script_file> — исполняемый файл скрипта.qm set <vmid> --hookscript <storage>:snippets/<script_file>#pct set <vmid> --hookscript <storage>:snippets/<script_file>
# qm set 103 --hookscript snippet:snippets/guest-hookscript.pl
update VM 103: -hookscript snippet:snippets/guest-hookscript.pl
Примечание


guest-hookscript.pl):
#!/usr/bin/perl
# Example hookscript for PVE guests
use strict;
use warnings;
print "GUEST HOOK: " . join(' ', @ARGV). "\n";
# First argument is the vmid
my $vmid = shift;
# Second argument is the phase
my $phase = shift;
if ($phase eq 'pre-start') {
# Первый этап 'pre-start' будет выполнен до запуска ВМ
# Выход с code != 0 отменит старт ВМ
print "$vmid is starting, doing preparations.\n";
# print "preparations failed, aborting."
# exit(1);
} elsif ($phase eq 'post-start') {
# Второй этап 'post-start' будет выполнен после успешного
# запуска ВМ
system("/root/date.sh $vmid");
print "$vmid started successfully.\n";
} elsif ($phase eq 'pre-stop') {
# Третий этап 'pre-stop' будет выполнен до остановки ВМ через API
# Этап не будет выполнен, если ВМ остановлена изнутри,
# например, с помощью 'poweroff'
print "$vmid will be stopped.\n";
} elsif ($phase eq 'post-stop') {
# Последний этап 'post-stop' будет выполнен после остановки ВМ
# Этап должен быть выполнен даже в случае сбоя или неожиданной остановки ВМ
print "$vmid stopped. Doing cleanup.\n";
} else {
die "got unknown phase '$phase'\n";
}
exit(0);

#!/bin/bash if [ $2 == "pre-start" ] then echo "Запуск ВМ $1" >> /root/test.txt date >> /root/test.txt fi


args: -vnc 0.0.0.0:55Или, чтобы включить защиту паролем:
args: -vnc 0.0.0.0:55,password=on
set_password vnc newvnc -d vnc2
В данном примере, при подключении будет запрашиваться пароль: newvnc. Максимальная длина пароля VNC: 8 символов. После перезапуска ВМ указанную выше команду необходимо повторить, чтобы снова установить пароль.
Примечание

Примечание

qemu-img — утилита для манипулирования с образами дисков машин QEMU. qemu-img позволяет выполнять операции по созданию образов различных форматов, конвертировать файлы-образы между этими форматами, получать информацию об образах и объединять снимки ВМ для тех форматов, которые это поддерживают. (подробнее см. раздел «Утилита qemu-img»).
qemu-img:
# qemu-img convert -f vmdk test.vmdk -O qcow2 test.qcow2
# qemu-img create -f raw test.raw 40G
# qemu-img resize -f raw test.raw 80G
# qemu-img info test.raw






# qm resize <vm_id> <virtual_disk> [+]<size>
Примечание
# qm resize 100 scsi1 80G

# qm move-disk <vm_id> <virtual_disk> <storage>

# qm move-disk <vm_id> <virtual_disk> --target-vmid <vm_id> --target-disk <virtual_disk>
# qm move-disk 107 scsi0 --target-vmid 10007 --target-disk scsi1

Примечание
Примечание

# qm set VMID -spice_enhancements foldersharing=1,videostreaming=all
Примечание
http://localhost:9843.
Примечание

Примечание
dav://localhost:9843/).



lsusb).
lsusb -t).
Примечание
info usb или info usbhost:

Предупреждение


# qm set <vm_id> -efidisk0 <storage>:1,format=<format>,efitype=4m,pre-enrolled-keys=1
где:
efitype — указывает, какую версию микропрограммы OVMF следует использовать. Для новых ВМ необходимо указывать 4м (это значение по умолчанию в графическом интерфейсе);
pre-enroll-keys — указывает, должен ли efidisk поставляться с предварительно загруженными ключами безопасной загрузки для конкретного дистрибутива и Microsoft Standard Secure Boot. Включает безопасную загрузку по умолчанию.
# qm set <vm_id> -tpmstate0 <storage>:1,version=<version>
где:
Примечание
intel_iommu=on (для процессоров AMD он должен быть включен автоматически).
/etc/modules):
vfio vfio_iommu_type1 vfio_pci vfio_virqfd
# dmesg | grep -e DMAR -e IOMMU -e AMD-Vi
/etc/modprobe.d/vfio.conf строку:
options vfio-pci ids=1234:5678,4321:8765где 1234:5678 и 4321:8765 — идентификаторы поставщика и устройства.
# lspci -nn
/etc/modprobe.d/blacklist.conf:
blacklist DRIVERNAME

# qm set VMID -hostpci0 00:02.0
# qm set VMID -hostpci0 02:00,device-id=0x10f6,sub-vendor-id=0x0000
# apt-get install qemu-guest-agent
# systemctl enable --now qemu-guest-agent

# qm set <vmid> --agent 1
Для вступления изменений в силу необходим перезапуск ВМ.
trim гостевой системе после следующих операций, которые могут записать нули в хранилище:
/var/run/qemu-server/<my_vmid>.qga. Проверить связь с агентом можно помощью команды:
# qm agent <vmid> ping
Если гостевой агент правильно настроен и запущен в ВМ, вывод команды будет пустой.
/etc/pve/qemu-server/<VMID>.conf). Как и другие файлы, находящиеся в /etc/pve/, они автоматически реплицируются на все другие узлы кластера.
Примечание
boot: order=scsi0;scsi7;net0 cores: 1 memory: 2048 name: newVM net0: virtio=3E:E9:24:FF:85:D9,bridge=vmbr0,firewall=1 numa: 0 ostype: l26 sata2: local-iso:iso/slinux-10.1-x86_64.iso,media=cdrom,size=4586146K scsi0: local:100/vm-100-disk-0.qcow2,size=42G scsihw: virtio-scsi-pci smbios1: uuid=ee9db068-5427-4934-bf7a-5895c377b5af sockets: 1 usb0: host=1-1.2 vmgenid: dfec8e3b-d391-40cb-8983-b4938461b79a
OPTION: value
qm для генерации и изменения этих файлов, либо выполнять такие действия в веб-интерфейсе.
bootdisk: scsi0 … parent: snapshot … vmgenid: dfec8e3b-d391-40cb-8983-b4938461b79a [snapshot] boot: order=scsi0;sata2;net0 cores: 1 memory: 2048 meta: creation-qemu=7.1.0,ctime=1671708251 name: NewVM net0: virtio=3E:E9:24:FF:85:D9,bridge=vmbr0,firewall=1 numa: 0 ostype: l26 runningcpu: kvm64,enforce,+kvm_pv_eoi,+kvm_pv_unhalt,+lahf_lm,+sep runningmachine: pc-i440fx-7.1+pve0 sata2: local-iso:iso/slinux-10.1-x86_64.iso,media=cdrom,size=4586146K scsi0: local:100/vm-100-disk-0.qcow2,size=42G scsihw: virtio-scsi-pci smbios1: uuid=ee9db068-5427-4934-bf7a-5895c377b5af snaptime: 1671724448 sockets: 1 usb0: host=1-1.2 vmgenid: dfec8e3b-d391-40cb-8983-b4938461b79a vmstate: local:100/vm-100-state-first.raw
parent при этом используется для хранения родительских/дочерних отношений между снимками, а snaptime — это отметка времени создания снимка (эпоха Unix).










pct для создания контейнера:
#!/bin/bash hostname="pve02" vmid="104" template_path="/var/lib/vz/template/cache" storage="local" description="alt-p10" template="alt-p10-rootfs-systemd-x86_64.tar.xz" ip="192.168.0.93/24" nameserver="8.8.8.8" ram="1024" rootpw="password" rootfs="4" gateway="192.168.0.1" bridge="vmbr0" if="eth0" #### Execute pct create using variable substitution #### pct create $vmid \ $template_path/$template \ -description $description \ -rootfs $rootfs \ -hostname $hostname \ -memory $ram \ -nameserver $nameserver \ -storage $storage \ -password $rootpw \ -net0 name=$if,ip=$ip,gw=$gateway,bridge=$bridge





tty — открывать соединение с одним из доступных tty-устройств (по умолчанию);
shell — вызывать оболочку внутри контейнера (без входа в систему);
/dev/console — подключаться к /dev/console.

Примечание

pct — утилита управления контейнерами LXC в PVE. Чтобы просмотреть доступные для контейнеров команды PVE, можно выполнить следующую команду:
# pct help
# pct set <ct_id> [options]
# pct set 101 -net0 name=eth0,bridge=vmbr0,ip=192.168.0.17/24,gw=192.168.0.1
# pct set <ct_id> -memory <int_value>
# pct set <ct_id> -rootfs <volume>,size=<int_value for GB>
Например, изменить размер диска контейнера #101 до 10 ГБ:
# pct set 101 -rootfs local:101/vm-101-disk-0.raw,size=10G
# pct config <ct_id>
# pct unlock <ct_id>
# pct list
VMID Status Lock Name
101 running newLXC
102 stopped pve01
103 stopped LXC2
#pct start <ct_id>#pct stop <ct_id>
/etc/pve/lxc, а файлы конфигураций ВМ — в /etc/pve/qemu-server/.
pct. Эти параметры могут быть настроены только путём внесения изменений в файл конфигурации с последующим перезапуском контейнера.
/etc/pve/lxc/101.conf:
arch: amd64 cmode: shell console: 0 cores: 1 features: nesting=1 hostname: newLXC memory: 512 net0: name=eth0,bridge=vmbr0,firewall=1,gw=192.168.0.1,hwaddr=C6:B0:3E:85:03:C9,ip=192.168.0.30/24,type=veth ostype: altlinux rootfs: local:101/vm-101-disk-0.raw,size=8G swap: 512 tty: 3 unprivileged: 1

# pct start 102
# pct stop 102


# pct enter <ct_id>
[root@pve01 ~]# pct enter 105
[root@newLXC ~]#
exit.
Предупреждение
Insecure $ENV{ENV} while running with...
необходимо в файле /root/.bashrc закомментировать строку:
ENV=$HOME/.bashrcи выполнить команду:
# unset ENV
# pct exec <ct_id> -- <command>
#pct exec 105 mkdir /home/demouser#pct exec 105 ls /homedemouser
pct, добавив -- после идентификатора контейнера:
# pct exec 105 -- df -H /
Файловая система Размер Использовано Дост Использовано% Cмонтировано в
/dev/loop0 8,4G 516M 7,4G 7% /
Примечание
rsync.

Примечание



# qm migrate <vmid> <target> [OPTIONS]
--online.
# pct migrate <ctid> <target> [OPTIONS]
--restart. Например:
# pct migrate 101 pve02 --restart
Примечание
$ oneimage show 14
IMAGE 14 INFORMATION
ID : 14
NAME : ALT Linux p9
USER : oneadmin
GROUP : oneadmin
LOCK : None
DATASTORE : default
TYPE : OS
REGISTER TIME : 04/30 11:00:42
PERSISTENT : Yes
SOURCE : /var/lib/one//datastores/1/f811a893808a9d8f5bf1c029b3c7e905
FSTYPE : save_as
SIZE : 12G
STATE : used
RUNNING_VMS : 1
PERMISSIONS
OWNER : um-
GROUP : ---
OTHER : ---
IMAGE TEMPLATE
DEV_PREFIX="vd"
DRIVER="qcow2"
SAVED_DISK_ID="0"
SAVED_IMAGE_ID="7"
SAVED_VM_ID="46"
SAVE_AS_HOT="YES"
где /var/lib/one//datastores/1/f811a893808a9d8f5bf1c029b3c7e905 — адрес образа жёсткого диска ВМ.
Примечание
$ onevm disk-saveas <vmid> <diskid> <img_name> [--type type --snapshot snapshot]
где --type <type> — тип нового образа (по умолчанию raw); --snapshot <snapshot_id> — снимок диска, который будет использован в качестве источника нового образа (по умолчанию текущее состояние диска).
$ onevm disk-saveas 125 0 test.qcow2
Image ID: 44
Информация об образе диска ВМ:
$ oneimage show 44
MAGE 44 INFORMATION
ID : 44
NAME : test.qcow2
USER : oneadmin
GROUP : oneadmin
LOCK : None
DATASTORE : default
TYPE : OS
REGISTER TIME : 07/12 21:34:42
PERSISTENT : No
SOURCE : /var/lib/one//datastores/1/9d6336a88d6ab62ea1dce65d81e55881
FSTYPE : save_as
SIZE : 12G
STATE : rdy
RUNNING_VMS : 0
PERMISSIONS
OWNER : um-
GROUP : ---
OTHER : ---
IMAGE TEMPLATE
DEV_PREFIX="vd"
DRIVER="qcow2"
SAVED_DISK_ID="0"
SAVED_IMAGE_ID="14"
SAVED_VM_ID="125"
SAVE_AS_HOT="YES"
VIRTUAL MACHINES
Информация о диске:
$ qemu-img info /var/lib/one//datastores/1/9d6336a88d6ab62ea1dce65d81e55881
image: /var/lib/one//datastores/1/9d6336a88d6ab62ea1dce65d81e55881
file format: qcow2
virtual size: 12 GiB (12884901888 bytes)
disk size: 3.52 GiB
cluster_size: 65536
Format specific information:
compat: 1.1
compression type: zlib
lazy refcounts: false
refcount bits: 16
corrupt: false
extended l2: false
# qm create 120 --bootdisk scsi0 --net0 virtio,bridge=vmbr0 --scsihw virtio-scsi-pci
# qm importdisk <vmid> <source> <storage> [OPTIONS]
Импорт диска f811a893808a9d8f5bf1c029b3c7e905 в хранилище local, для ВМ с ID 120 (подразумевается, что образ импортируемого диска находится в каталоге, из которого происходит выполнение команды):
# qm importdisk 120 f811a893808a9d8f5bf1c029b3c7e905 local --format qcow2
importing disk 'f811a893808a9d8f5bf1c029b3c7e905' to VM 120 ...
…
Successfully imported disk as 'unused0:local:120/vm-120-disk-0.qcow2'
# qm set 120 --scsi0 local:120/vm-120-disk-0.qcow2
update VM 120: -scsi0 local:120/vm-120-disk-0.qcow2
"C:\Program Files\VMware\VMware Server\vmware-vdiskmanager" -r win7.vmdk -t 0 win7-pve.vmdk
где win7.vmdk — файл с образом диска.
win7-pve.vmdk в каталог с образами ВМ /var/lib/vz/images/VMID, где VMID — VMID, созданной виртуальной машины (можно воспользоваться WinSCP);
win7-pve.vmdk в qemu формат:
# qemu-img convert -f vmdk win7-pve.vmdk -O qcow2 win7-pve.qcow2
/etc/pve/nodes/pve02/qemu-server/VMID.conf) строку:
unused0: local:100/win7-pve.qcow2где 100 — VMID, а local — хранилище в PVE.

# qemu-img info win7-pve.vmdk
image: win7-pve.vmdk
file format: vmdk
virtual size: 127G (136365211648 bytes)
disk size: 20.7 GiB
cluster_size: 65536
Format specific information:
cid: 3274246794
parent cid: 4294967295
create type: streamOptimized
extents:
[0]:
compressed: true
virtual size: 136365211648
filename: win7-pve.vmdk
cluster size: 65536
format:
В данном случае необходимо создать диск в режиме IDE размером не меньше 127GB.
win7-pve.vmdk в каталог с образами ВМ /var/lib/vz/images/VMID, где VMID — VMID, созданной виртуальной машины (можно воспользоваться WinSCP);
# lvscan
ACTIVE '/dev/sharedsv/vm-101-disk-1' [130,00 GiB] inherit
# qemu-img convert -f vmdk win7-pve.vmdk -O raw /dev/sharedsv/vm-101-disk-1
# qemu-img info win7-pve.vmdk
win7-pve.vmdk в каталог с образами ВМ /var/lib/vz/images/VMID, где VMID — VMID созданной ВМ;
# rbd map rbd01/vm-100-disk-1
/dev/rbd0
Примечание
# qemu-img convert -f vmdk win7-pve.vmdk -O raw /dev/rbd0
# qm importovf 999 WinDev2212Eval.ovf local-lvm
Примечание
Примечание

Полное клонирование и Связанная копия;


Примечание

Примечание

Связанная копия):




 , и удалить их, нажав кнопку
, и удалить их, нажав кнопку
 . Чтобы сохранить или отменить изменения, используются кнопки
. Чтобы сохранить или отменить изменения, используются кнопки
 и
и
 соответственно:
соответственно:

# qm set ID --tags 'myfirsttag;mysecondtag'
Например:
# qm set 103 --tags 'linux;openuds'


# pvesh set /cluster/options --tag-style [case-sensitive=<1|0>]\
[,color-map=<tag>:<hex-color> [:<hex-color-for-text>][;<tag>=...]]\
[,ordering=<config|alphabetical>][,shape=<circle|dense|full|none>]
Например, следущая команда установит для тега «FreeIPA» цвет фона черный (#000000), а цвет текста — белый (#FFFFFF) и форму для всех тегов :
# pvesh set /cluster/options --tag-style color-map=FreeIPA:000000:FFFFFF,shape=dense
Примечание
pvesh set /cluster/options --tag-style … удалит все ранее переопределённые стили тегов.

# pvesh set /cluster/options --user-tag-access\
[user-allow=<existing|free|list|none>][,user-allow-list=<tag>[;<tag>...]]
Например, запретить пользователям использовать теги:
# pvesh set /cluster/options --user-tag-access user-allow=none

# pvesh set /cluster/options --registered-tags <tag>[;<tag>...]
vzdump.
mode) в зависимости от типа гостевой системы.
Примечание
--tmpdir). Затем контейнер приостанавливается и rsync копирует измененные файлы. После этого контейнер возобновляет свою работу. Это приводит к минимальному времени простоя, но требует дополнительное пространство для хранения копии контейнера. Когда контейнер находится в локальной файловой системе и хранилищем резервной копии является сервер NFS, необходимо установить --tmpdir также и на локальную файловую систему, так как это приведет к повышению производительности. Использование локального tmpdir также необходимо, если требуется сделать резервную копию локального контейнера с использованием списков контроля доступа (ACL) в режиме ожидания, если хранилище резервных копий — сервер NFS;
Примечание
backup=0 в PVE используется для исключения определённых точек монтирования (mount points) из резервного копирования. Например, если в конфигурации контейнера указано:
mp0: local:210/vm-210-disk-1.raw,mp=/mnt/data,backup=0,size=8Gточка монтирования
/mnt/data не будет включена в резервную копию контейнера.
Примечание



prune-backups команды vzdump):
keep-all=<1|0>) — хранить все резервные копии (если отмечен этот пункт, другие параметры не могут быть установлены);
keep-last=<N>) — хранить <N> последних резервных копий;
keep-hourly=<N>) — хранить резервные копии за последние <N> часов (если за один час создается более одной резервной копии, сохраняется только последняя);
keep-daily=<N>) — хранить резервные копии за последние <N> дней (если за один день создается более одной резервной копии, сохраняется только самая последняя);
keep-weekly=<N>) — хранить резервные копии за последние <N> недель (если за одну неделю создается более одной резервной копии, сохраняется только самая последняя);
keep-monthly=<N>) — хранить резервные копии за последние <N> месяцев (если за один месяц создается более одной резервной копии, сохраняется только самая последняя);
keep-yearly=<N>) — хранить резервные копии за последние <N> лет (если за один год создается более одной резервной копии, сохраняется только самая последняя);
max-protected-backups) — количество защищённых резервных копий на гостевую систему, которое разрешено в хранилище. Для указания неограниченного количества используется значение -1. Значение по умолчанию: неограниченно для пользователей с привилегией Datastore.Allocate и 5 для других пользователей.
# vzdump 777 --prune-backups keep-last=3,keep-daily=13,keep-yearly=9
lzop). Особенностью этого алгоритма является скоростная распаковка. Следовательно, любая резервная копия, созданная с помощью этого алгоритма, может при необходимости быть развернута за минимальное время.
Zip, использующей мощный алгоритм Deflate. Упор делается на максимальное сжатие данных, что позволяет сократить место на диске, занимаемое резервными копиями. Главным отличием от LZO является то, что процедуры компрессии/декомпрессии занимают достаточно большое количество времени.
dump. Имя файла резервной копии будет иметь вид:
vzdump.






Предупреждение
/etc/pve/jobs.cfg, которые анализируются и выполняются демоном pvescheduler.
man 7 systemd.time).
[WEEKDAY] [[YEARS-]MONTHS-DAYS] [HOURS:MINUTES[:SECONDS]]
Таблица 49.1. Специальные значения
|
Расписание
|
Значение
|
Синтаксис
|
|---|---|---|
|
minutely
|
Каждую минуту
|
*-*-* *:*:00
|
|
hourly
|
Каждый час
|
*-*-* *:00:00
|
|
daily
|
Раз в день
|
*-*-* 00:00:00
|
|
weekly
|
Раз в неделю
|
mon *-*-* 00:00:00
|
|
monthly
|
Раз в месяц
|
*-*-01 00:00:00
|
|
yearly или annually
|
Раз в год
|
*-01-01 00:00:00
|
|
quarterly
|
Раз в квартал
|
*-01,04,07,10-01 00:00:00
|
|
semiannually или semi-annually
|
Раз в полгода
|
*-01,07-01 00:00:00
|
Таблица 49.2. Примеры
|
Расписание
|
Эквивалент
|
Значение
|
|---|---|---|
|
mon,tue,wed,thu,fri
|
mon..fri
|
Каждый будний день в 00:00
|
|
sat,sun
|
sat..sun
|
В субботу и воскресенье в 00:00
|
|
mon,wed,fri
|
-
|
В понедельник, среду и пятницу в 00:00
|
|
12:05
|
12:05
|
Каждый день в 12:05
|
|
*/5
|
0/5
|
Каждые пять минут
|
|
mon..wed 30/10
|
mon,tue,wed 30/10
|
В понедельник, среду и пятницу в 30, 40 и 50 минут каждого часа
|
|
mon..fri 8..17,22:0/15
|
-
|
Каждые 15 минут с 8 часов до 18 и с 22 до 23 в будний день
|
|
fri 12..13:5/20
|
fri 12,13:5/20
|
В пятницу в 12:05, 12:25, 12:45, 13:05, 13:25 и 13:45
|
|
12,14,16,18,20,22:5
|
12/2:5
|
Каждые два часа каждый день с 12:05 до 22:05
|
|
*
|
*/1
|
Ежеминутно (минимальный интервал)
|
|
*-05
|
-
|
Пятого числа каждого месяца
|
|
Sat *-1..7 15:00
|
-
|
Первую субботу каждого месяца в 15:00
|
|
2023-10-22
|
-
|
22 октября 2023 года в 00:00
|




Примечание
# systemctl enable --now postfix


Примечание
pvescheduler, можно настроить поведение для наверстывания упущенного. Включив параметр Повторять пропущенные (доступно если установлена отметка в поле Дополнительно) или указав параметр repeat-missed в конфигурации задания, можно указать планировщику, что он должен запустить пропущенные задания как можно скорее.


/etc/pve/jobs.cfg):

pct restore — утилита восстановления контейнера;
qmrestore — утилита восстановления ВМ.
per-restore limit — максимальный объем полосы пропускания для чтения из архива резервной копии;
per-storage write limit — максимальный объем полосы пропускания, используемый для записи в конкретное хранилище.
bwlimit. В качестве единицы ограничения используется Кб/с, это означает, что значение 10240 ограничит скорость чтения резервной копии до 10 Мб/с, гарантируя, что остальная часть возможной пропускной способности хранилища будет доступна для уже работающих гостевых систем, и, таким образом, резервное копирование не повлияет на их работу.
Примечание
0 для параметра bwlimit. Это может быть полезно, если требуется как можно быстрее восстановить ВМ.
# pvesm set STORAGEID --bwlimit restore=KIBs
live-restore.

live-restore в команде qmrestore приводит к запуску ВМ сразу после начала восстановления. Данные копируются в фоновом режиме, отдавая приоритет фрагментам, к которым ВМ активно обращается.

/etc/vzdump.conf. Каждая строка файла имеет следующий формат (пустые строки в файле игнорируются, строки, начинающиеся с символа #, рассматриваются как комментарии и также игнорируются):
OPTION: value
Таблица 49.3. Параметры файла конфигурации
|
Опция
|
Описание
|
|---|---|
|
bwlimit: integer (0 — N) (default=0)
|
Ограничение пропускной способности ввода/вывода (Кб/с)
|
|
compress: (0|1|gzip|lzo|zstd) (default=0)
|
Сжатие файла резервной копии
|
|
dumpdir: string
|
Записать результирующие файлы в указанный каталог
|
|
exclude-path: string
|
Исключить определенные файлы/каталоги
|
|
ionice: integer (0 — 8) (default=7)
|
Установить CFQ приоритет ionice
|
|
lockwait: integer (0 — N) (default=180)
|
Максимальное время ожидания для глобальной блокировки (в минутах)
|
|
mailnotification: (always|failure) (default=always)
|
Указание, когда следует отправлять отчет по электронной почте
|
|
mailto: string
|
Разделенный запятыми список адресов электронной почты, на которые будут приходить уведомления
|
|
maxfiles: integer (1 — N) (default=1)
|
Устарело: следует использовать вместо этого prune-backups. Максимальное количество файлов резервных копий ВМ
|
|
mode: (snapshot|stop|suspend) (default=snapshot)
|
Режим резервного копирования
|
|
notes-template: string
|
Строка шаблона для создания заметок для резервных копий. Может содержать переменные, которые будут заменены их значениями. В настоящее время поддерживаются следующие переменные {{cluster}}, {{guestname}}, {{node}} и {{vmid}}. Шаблон должен быть записан в одну строку, новая строка и обратная косая черта должны быть экранированы как \n и \\ соответственно
|
|
performance: [max-workers=integer]
max-workers=integer (1 — 256)
|
Другие настройки, связанные с производительностью.
max-workers — разрешить до этого количества рабочих процессов ввода-вывода одновременно (применяется к ВМ)
|
|
pigz: integer (default=0)
|
Использует pigz вместо gzip при N>0. N=1 использует половину ядер (uses half of cores), при N>1 N — количество потоков
|
|
pool: string
|
Резервное копирование всех известных гостевых систем, включенных в указанный пул
|
|
protected: boolean
|
Если true, пометить резервную копию как защищенную
|
|
prune-backups: [keep-all=<1|0>] [,keep-daily=<N>] [,keep-hourly=<N>] [,keep-last=<N>] [,keep-monthly=<N>] [,keep-weekly=<N>] [,keep-yearly=<N>]
|
Использовать эти параметры хранения вместо параметров из конфигурации хранилища (см.выше)
|
|
remove: boolean (default=1)
|
Удалить старые резервные копии, если их больше, чем установлено опцией prune-backups
|
|
script: string
|
Использовать указанный скрипт
|
|
stdexcludes: boolean (default=1)
|
Исключить временные файлы и файлы журналов
|
|
stopwait: integer (0 — N) (default=10)
|
Максимальное время ожидания до остановки ВМ (минуты)
|
|
storage: string
|
Хранить полученный файл в этом хранилище
|
|
tmpdir: string
|
Хранить временные файлы в указанном каталоге
|
|
zstd: integer (default = 1)
|
Количество потоков zstd. N = 0 использовать половину доступных ядер, N > 0 использовать N как количество потоков
|
vzdump.conf:
tmpdir: /mnt/fast_local_disk storage: my_backup_storage mode: snapshot bwlimit: 10000
--script. Этот скрипт вызывается на различных этапах процесса резервного копирования с соответствующими параметрами (см. пример скрипта /usr/share/doc/pve-manager/examples/vzdump-hook-script.pl).
Примечание
vzdump по умолчанию пропускает следующие файлы (отключается с помощью опции --stdexcludes 0):
/tmp/?* /var/tmp/?* /var/run/?*pid
# vzdump 777 --exclude-path /tmp/ --exclude-path '/var/foo*'
# vzdump 777 --exclude-path bar
исключает любые файлы и каталоги с именами /bar, /var/bar, /var/foo/bar и т.д.
/etc/vzdump/) и будут корректно восстановлены.
/var/lib/vz/dump/):
# vzdump 103
rsync и режим приостановки для создания снимка (минимальное время простоя):
# vzdump 103 --mode suspend
# vzdump --all --mode suspend --mailto root --mailto admin
/mnt/backup:
# vzdump 103 --dumpdir /mnt/backup --mode snapshot
# vzdump 101 102 103 --mailto root
# vzdump --mode suspend --exclude 101,102
# pct restore 600 /mnt/backup/vzdump-lxc-104.tar
# qmrestore /mnt/backup/vzdump-qemu-105.vma 601
# vzdump 101 --stdout | pct restore --rootfs 4 300 -



boot: order=scsi0;sata2;net0 cores: 1 memory: 2048 meta: creation-qemu=7.1.0,ctime=1671708251 name: NewVM net0: virtio=3E:E9:24:FF:85:D9,bridge=vmbr0,firewall=1 numa: 0 ostype: l26 parent: first sata2: local-iso:iso/slinux-10.1-x86_64.iso,media=cdrom,size=4586146K scsi0: local:100/vm-100-disk-0.qcow2,size=42G scsihw: virtio-scsi-pci smbios1: uuid=ee9db068-5427-4934-bf7a-5895c377b5af sockets: 1 vmgenid: dfec8e3b-d391-40cb-8983-b4938461b79a [first] #clear system boot: order=scsi0;sata2;net0 cores: 1 memory: 2048 meta: creation-qemu=7.1.0,ctime=1671708251 name: NewVM net0: virtio=3E:E9:24:FF:85:D9,bridge=vmbr0,firewall=1 numa: 0 ostype: l26 runningcpu: kvm64,enforce,+kvm_pv_eoi,+kvm_pv_unhalt,+lahf_lm,+sep runningmachine: pc-i440fx-7.1+pve0 sata2: local-iso:iso/slinux-10.1-x86_64.iso,media=cdrom,size=4586146K scsi0: local:100/vm-100-disk-0.qcow2,size=42G scsihw: virtio-scsi-pci smbios1: uuid=ee9db068-5427-4934-bf7a-5895c377b5af snaptime: 1671724448 sockets: 1 vmgenid: dfec8e3b-d391-40cb-8983-b4938461b79a vmstate: local:100/vm-100-state-first.raw
parent используется для хранения родительских/дочерних отношений между снимками, snaptime — это отметка времени создания снимка (эпоха Unix).



# smartctl -a /dev/sdX
где /dev/sdX — это путь к одному из локальных дисков.
# smartctl -s on /dev/sdX

/dev каждые 30 минут на наличие ошибок и предупреждений, а также отправляет сообщение электронной почты пользователю root в случае обнаружения проблемы (для пользователя root в PVE должен быть введен действительный адрес электронной почты).
Примечание
/etc/modprobe.d/nohpwdt.conf со следующим содержимым:
# Do not load the 'hpwdt' module on boot. blacklist hpwdtДля применения изменений следует перезагрузить систему.

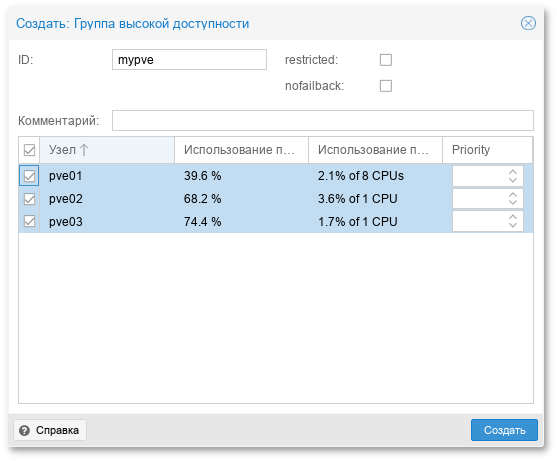



# ha-manager status
quorum OK
master pve01 (active, Wed Aug 23 13:26:31 2023)
lrm pve01 (active, Wed Aug 23 13:26:31 2023)
lrm pve02 (active, Wed Aug 23 13:26:33 2023)
lrm pve03 (active, Wed Aug 23 13:26:26 2023)
service ct:105 (pve01, started)
service vm:100 (pve01, stopped)


restart и relocate. Если все попытки окажутся неудачными, HA PVE поместит ресурсы в ошибочное состояние и не будет выполнять для них никаких задач.
/etc/pve/firewall/).
/etc/pve/firewall/cluster.fw используется для хранения конфигурации PVE Firewall на уровне всего кластера. Этот файл содержит глобальные правила и параметры, которые применяются ко всем узлам и ВМ в кластере. Файл автоматически синхронизируется между всеми узлами кластера через PVE Cluster File System (pmxcfs).
/etc/pve/firewall/cluster.fw состоит из нескольких секций, каждая из которых отвечает за определённые аспекты конфигурации firewall. В файле содержатся следующие секции:
Таблица 52.1. Опции секции [OPTIONS] файла cluster.fw
|
Опция
|
Описание
|
|---|---|
|
ebtables: <1|0> (по умолчанию = 1)
|
Включить правила ebtables для всего кластера
|
|
enable: <1|0>
|
Включить или отключить межсетевой экран для всего кластера
|
|
log_ratelimit: [enable=]<1|0> [,burst=<integer>] [,rate=<rate>]
|
Настройки ограничения частоты записи логов (rate limiting) в PVE Firewall.
|
|
policy_in: <ACCEPT | DROP | REJECT>
|
Политика по умолчанию для входящего трафика. Возможные значения:
|
|
policy_out: <ACCEPT | DROP | REJECT>
|
Политика по умолчанию для исходящего трафика (аналогично policy_in)
|

enable в файле /etc/pve/firewall/cluster.fw:
[OPTIONS] # enable firewall (настройка для всего кластера, по умолчанию отключено) enable: 1
Важно
Примечание
/etc/pve/nodes/<nodename>/host.fw. Здесь можно перезаписать правила из конфигурации cluster.fw или увеличить уровень детализации журнала и задать параметры, связанные с netfilter.
host.fw содержатся следующие секции:
Таблица 52.2. Опции секции [OPTIONS] конфигурации узла
|
Опция
|
Описание
|
|---|---|
|
enable: <1|0>
|
Включить или отключить межсетевой экран узла
|
|
log_level_in: <alert | crit | debug | emerg | err | info | nolog | notice | warning>
|
Уровень журнала для входящего трафика. Возможные значения:
|
|
log_level_out: <alert | crit | debug | emerg | err | info | nolog | notice | warning>
|
Уровень журнала для исходящего трафика (аналогично log_level_in)
|
|
log_nf_conntrack: <1|0> (по умолчанию = 0)
|
Включить регистрацию информации о conntrack
|
|
ndp: <1|0> (по умолчанию = 0)
|
Включить NDP (протокол обнаружения соседей)
|
|
nf_conntrack_allow_invalid: <1|0> (по умолчанию = 0)
|
Разрешить недействительные пакеты при отслеживании соединения
|
|
nf_conntrack_helpers: <string> (по умолчанию = ``)
|
Включить conntrack helpers для определенных протоколов. Поддерживаемые протоколы: amanda, ftp, irc, netbios-ns, pptp, sane, sip, snmp, tftp
|
|
nf_conntrack_max: <integer> (32768 — N) (по умолчанию = 262144)
|
Максимальное количество отслеживаемых соединений
|
|
nf_conntrack_tcp_timeout_installed: <integer> (7875 — N) (по умолчанию = 432000)
|
Тайм-аут, установленный для conntrack
|
|
nf_conntrack_tcp_timeout_syn_recv: <integer> (30 — 60) (по умолчанию = 60)
|
Тайм-аут syn recv conntrack
|
|
nosmurfs: <1|0>
|
Включить фильтр SMURFS
|
|
protection_synflood: <1|0> (по умолчанию = 0)
|
Включить защиту от synflood
|
|
protection_synflood_burst: <integer> (по умолчанию = 1000)
|
Уровень защиты от Synflood rate burst по IP-адресу источника
|
|
protection_synflood_rate: <integer> (по умолчанию = 200)
|
Скорость защиты Synflood syn/sec по IP-адресу источника
|
|
smurf_log_level: <alert | crit | debug | emerg | err | info | nolog | notification | warning>
|
Уровень журнала для фильтра SMURFS
|
|
tcp_flags_log_level: <alert | crit | debug | emerg | err | info | nolog | notification | warning>
|
Уровень журнала для фильтра нелегальных флагов TCP
|
|
tcpflags: <1|0> (по умолчанию = 0)
|
Фильтрация недопустимых комбинаций флагов TCP
|

/etc/pve/firewall/<VMID>.fw. Этот файл используется для установки параметров межсетевого экрана, связанных с ВМ/контейнером.
Таблица 52.3. Опции секции [OPTIONS] файла конфигурации ВМ/контейнера
|
Опция
|
Описание
|
|---|---|
|
dhcp: <1|0> (по умолчанию = 0)
|
Включить DHCP
|
|
enable: <1|0>
|
Включить или отключить межсетевой экран
|
|
ipfilter: <1|0>
|
Включить фильтры IP по умолчанию. Это эквивалентно добавлению пустого ipfilter-net<id> ipset для каждого интерфейса. Такие ipset неявно содержат разумные ограничения по умолчанию, такие как ограничение локальных адресов ссылок IPv6 до одного, полученного из MAC-адреса интерфейса. Для контейнеров будут неявно добавлены настроенные IP-адреса
|
|
log_level_in: <alert | crit | debug | emerg | err | info | nolog | notice | warning>
|
Уровень журнала для входящего трафика. Возможные значения:
|
|
log_level_out: <alert | crit | debug | emerg | err | info | nolog | notice | warning>
|
Уровень журнала для исходящего трафика (аналогично log_level_in)
|
|
macfilter: <1|0> (по умолчанию = 1)
|
Включить/выключить фильтр MAC-адресов
|
|
ndp: <1|0> (по умолчанию = 0)
|
Включить NDP (протокол обнаружения соседей)
|
|
policy_in: <ACCEPT | DROP | REJECT>
|
Политика по умолчанию для входящего трафика. Возможные значения:
|
|
policy_out: <ACCEPT | DROP | REJECT>
|
Политика по умолчанию для исходящего трафика (аналогично policy_in)
|
|
radv: <1|0>
|
Разрешить отправку объявлений маршрутизатора
|

[RULES] DIRECTION ACTION [OPTIONS] |DIRECTION ACTION [OPTIONS] # отключенное правило DIRECTION MACRO(ACTION) [OPTIONS] # использовать предопределенный макрос
Таблица 52.4. Параметры файла конфигурации
|
Опция
|
Описание
|
|---|---|
|
--dest <string>
|
Ограничить адрес назначения пакета. Может быть указан одиночный IP-адрес, набор IP-адресов (+ipsetname) или псевдоним IP (alias). Можно указать диапазон адресов (например, 200.34.101.207-201.3.9.99) или список IP-адресов и сетей (записи разделяются запятой). Не следует смешивать адреса IPv4 и IPv6 в таких списках
|
|
--dport <string>
|
Ограничить порт назначения TCP/UDP. Можно использовать имена служб или простые числа (0-65535), как определено в
/etc/services. Диапазоны портов можно указать с помощью \d+:\d+, например, 80:85. Для сопоставления нескольких портов или диапазонов можно использовать список, разделенный запятыми
|
|
--icmp-type <string>
|
Тип icmp. Действителен, только если proto равен icmp
|
|
--iface <string>
|
Сетевой интерфейс, к которому применяется правило. В правилах для ВМ и контейнеров необходимо указывать имена ключей конфигурации сети net\d+, например, net0. Правила, связанные с узлом, могут использовать произвольные строки
|
|
--log <alert | crit | debug | emerg | err | info | nolog | notice | warning>
|
Уровень журналирования для правила межсетевого экрана
|
|
--proto <string>
|
IP-протокол. Можно использовать названия протоколов (tcp/udp) или простые числа, как определено в
/etc/protocols
|
|
--source <string>
|
Ограничить исходный адрес пакета. Может быть указан одиночный IP-адрес, набор IP-адресов (+ipsetname) или псевдоним IP (alias). Можно указать диапазон адресов (например, 200.34.101.207-201.3.9.99) или список IP-адресов и сетей (записи разделяются запятой). Не следует смешивать адреса IPv4 и IPv6 в таких списках
|
|
--sport <string>
|
Ограничить исходный порт TCP/UDP. Можно использовать имена служб или простые числа (0-65535), как определено в
/etc/services. Диапазоны портов можно указать с помощью \d+:\d+, например, 80:85. Для сопоставления нескольких портов или диапазонов можно использовать список, разделенный запятыми
|
[RULES] IN SSH(ACCEPT) -i net0 IN SSH(ACCEPT) -i net0 # a comment IN SSH(ACCEPT) -i net0 -source 192.168.0.192 # разрешить SSH только из 192.168.0.192 IN SSH(ACCEPT) -i net0 -source 10.0.0.1-10.0.0.10 # разрешить SSH для диапазона IP IN SSH(ACCEPT) -i net0 -source 10.0.0.1,10.0.0.2,10.0.0.3 # разрешить SSH для списка IP-адресов IN SSH(ACCEPT) -i net0 -source +mynetgroup # разрешить SSH для ipset mynetgroup IN SSH(ACCEPT) -i net0 -source myserveralias # разрешить SSH для псевдонима myserveralias |IN SSH(ACCEPT) -i net0 # отключенное правило IN DROP # отбросить все входящие пакеты OUT ACCEPT # принять все исходящие пакеты

# /etc/pve/firewall/cluster.fw [group webserver] IN ACCEPT -p tcp -dport 80 IN ACCEPT -p tcp -dport 443
# /etc/pve/firewall/<VMID>.fw [RULES] GROUP webserver


source и dest правил межсетевого экрана.
# pve-firewall localnet
local hostname: pve01
local IP address: 192.168.0.186
network auto detect: 192.168.0.0/24
using detected local_network: 192.168.0.0/24
accepting corosync traffic from/to:
- pve02: 192.168.0.90 (link: 0)
- pve03: 192.168.0.70 (link: 0)
Межсетевой экран автоматически устанавливает правила, чтобы разрешить все необходимое для кластера (corosync, API, SSH) с помощью этого псевдонима.
/etc/pve/firewall/cluster.fw. Если используется один узел в публичной сети, лучше явно назначить локальный IP-адрес:
# /etc/pve/firewall/cluster.fw [ALIASES] local_network 192.168.0.186 # использовать одиночный IP-адрес
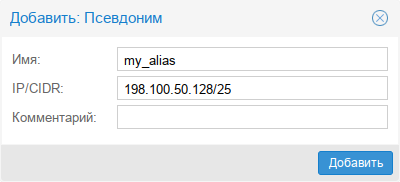
IN HTTP(ACCEPT) -source +management




# /etc/pve/firewall/cluster.fw [IPSET management] 192.168.0.90 192.168.0.90/24
# /etc/pve/firewall/cluster.fw [IPSET blacklist] 77.240.159.182 213.87.123.0/24
/etc/pve/firewall/<VMID>.fw [IPSET ipfilter-net0] # only allow specified IPs on net0 192.168.0.90
pve-firewall:
#Получение статуса службы:pve-firewall start#pve-firewall stop
# pve-firewall status
Данная команда считывает и компилирует все правила межсетевого экрана, поэтому если конфигурация межсетевого экрана содержит какие-либо ошибки, будут выведены ошибки.
# iptables-save
# iptables-save
Этот вывод также включен в системный отчет, выводимый при выполнении команды:
# pvereport
loglevel не влияет на объем регистрируемого фильтрованного трафика. Он изменяет LOGID, добавленный в качестве префикса к выводу журнала для упрощения фильтрации и постобработки.
Таблица 52.5. Флаги loglevel
|
loglevel
|
LOGID
|
|---|---|
|
nolog
|
—
|
|
emerg
|
0
|
|
alert
|
1
|
|
crit
|
2
|
|
err
|
3
|
|
warning
|
4
|
|
notice
|
5
|
|
info
|
6
|
|
debug
|
7
|
VMID LOGID CHAIN TIMESTAMP POLICY: PACKET_DETAILSВ случае межсетевого экрана узла VMID равен 0.
-log <loglevel> к выбранному правилу.
IN REJECT -p icmp -log nolog IN REJECT -p icmpА правило:
IN REJECT -p icmp -log debugсоздает вывод журнала, помеченный уровнем отладки.
Таблица 52.6. Используемые порты
|
Порт
|
Функция
|
|---|---|
|
8006 (TCP, HTTP/1.1 через TLS)
|
Веб-интерфейс PVE
|
|
5900-5999 (TCP, WebSocket)
|
Доступ к консоли VNC
|
|
3128 (TCP)
|
Доступ к консоли SPICE
|
|
22 (TCP)
|
SSH доступ
|
|
111 (UDP)
|
rpcbind
|
|
25 (TCP, исходящий)
|
sendmail
|
|
5405-5412 UDP
|
Трафик кластера corosync
|
|
60000-60050 (TCP)
|
Живая миграция (память виртуальной машины и данные локального диска)
|

/etc/pve/user.cfg:
# cat /etc/pve/user.cfg
user:root@pam:1:0::::::
user:test@pve:1:0::::::
user:testuser@pve:1:0::::Just a test::
user:user@pam:1:0::::::
group:admin:user@pam::
group:testgroup:test@pve::
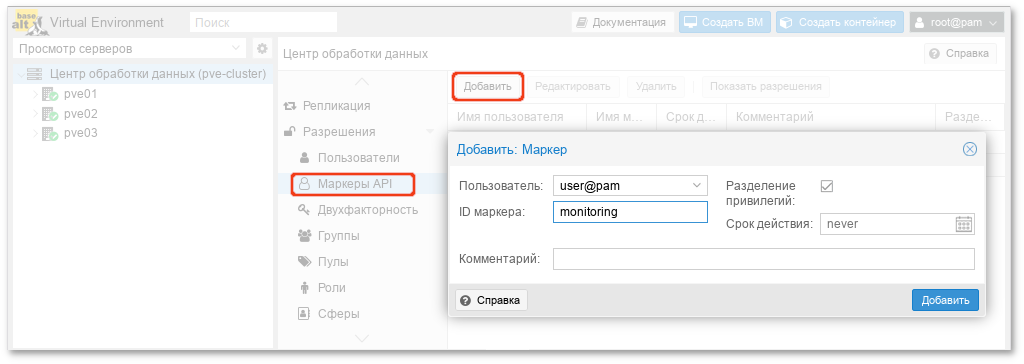
Примечание

Примечание


# pveum user token add <userid> <tokenid> [ОПЦИИ]
Возможные опции:
--comment <строка> — комментарий к токену;
--expire <целое число> — дата истечения срока действия API-токена в секундах с начала эпохи (по умолчанию срок действия API-токена совпадает со сроком действия пользователя). Значение 0 указывает, что срок действия токена не ограничен;
--privsep <логическое значение> — ограничить привилегии API-токена с помощью отдельных списков контроля доступа (по умолчанию) или предоставить полные привилегии соответствующего пользователя (значение 0).
# pveum user token add user@pam t2 --privsep 0
┌──────────────┬──────────────────────────────────────┐
│ key │ value │
╞══════════════╪══════════════════════════════════════╡
│ full-tokenid │ user@pam!t2 │
├──────────────┼──────────────────────────────────────┤
│ info │ {"privsep":"0"} │
├──────────────┼──────────────────────────────────────┤
│ value │ 3c749375-e189-493d-8037-a1179317c406 │
└──────────────┴──────────────────────────────────────┘
# pveum user token list user@pam
┌─────────────┬─────────┬────────┬─────────┐
│ tokenid │ comment │ expire │ privsep │
╞═════════════╪═════════╪════════╪═════════╡
│ monitoring │ │ 0 │ 1 │
├─────────────┼─────────┼────────┼─────────┤
│ t2 │ │ 0 │ 0 │
└─────────────┴─────────┴────────┴─────────┘
# pveum user token permissions user@pam t2
Можно использовать опцию --path, чтобы вывести разрешения для этого пути, а не всё дерево:
# pveum user token permissions user@pam t2 --path /storage
# pveum acl modify /vms --tokens 'user@pam!monitoring' --roles PVEAdmin,PVEAuditor
# pveum user token remove user@pam t2
Примечание
# pveum acl modify /vms --users test@pve --roles PVEVMAdmin
#pveum user token add test@pve monitoring --privsep 1#pveum acl modify /vms --tokens 'test@pve!monitoring' --roles PVEAuditor
#pveum user permissions test@pve#pveum user token permissions test@pve monitoring


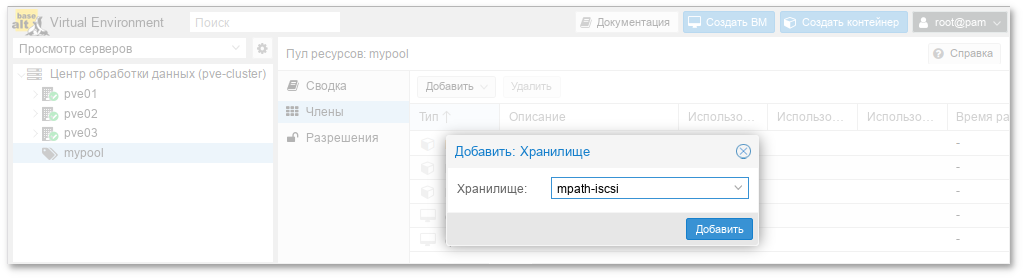
# pveum pool add IT --comment 'IT development pool'
# pveum pool list
┌────────┐
│ poolid │
╞════════╡
│ IT │
├────────┤
│ mypool │
└────────┘
# pveum pool modify IT --vms 201,108,202,104,208 --storage mpath2,nfs-storage
# pveum pool modify IT --delete 1 --vms 108,104
# pveum pool delete IT
Примечание
/etc/pve/domains.cfg.
adduser) на всех узлах, на которых пользователю разрешено войти в систему. Если пользователи PAM существуют в хост-системе PVE, соответствующие записи могут быть добавлены в PVE, чтобы эти пользователи могли входить в систему, используя свое системное имя и пароль.


/etc/pve/priv/shadow.cfg). Пароль шифруется с использованием метода хеширования SHA-256.


# pveum useradd testuser@pve -comment "Just a test"
# pveum passwd testuser@pve
# pveum usermod testuser@pve -enable 0
# pveum groupadd testgroup
# pveum roleadd PVE_Power-only -privs "VM.PowerMgmt VM.Console"





Примечание
# pveum realm sync example.test
Для автоматической синхронизации пользователей и групп можно добавить команду синхронизации в планировщик задач.


Примечание
# pveum realm sync test.alt
Для автоматической синхронизации пользователей и групп можно добавить команду синхронизации в планировщик задач.


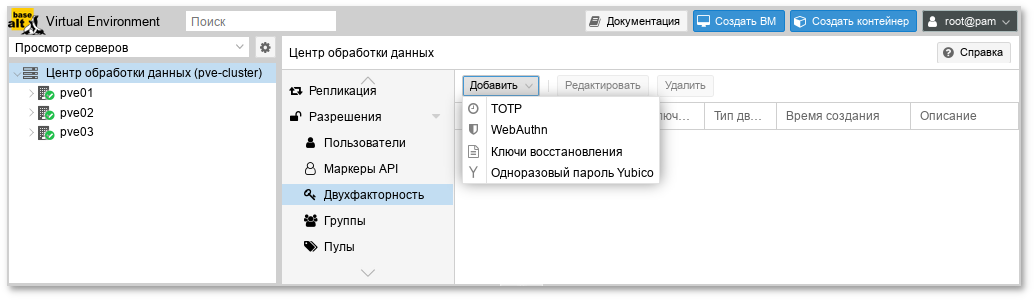

oathkeygen), который печатает случайный ключ в нотации Base32. Этот ключ можно использовать непосредственно с различными инструментами OTP, такими как инструмент командной строки oathtool, или приложении FreeOTP и в других подобных приложениях.
Примечание
Примечание






# pveum role add VM_Power-only --privs "VM.PowerMgmt VM.Console"
Таблица 53.1. Привилегии используемые в PVE
|
Привилегия
|
Описание
|
|---|---|
|
Привилегии узла/системы
|
|
|
Permissions.Modify
|
Изменение прав доступа
|
|
Sys.PowerMgmt
|
Управление питанием узла (запуск, остановка, сброс, выключение)
|
|
Sys.Console
|
Консольный доступ к узлу
|
|
Sys.Syslog
|
Просмотр Syslog
|
|
Sys.Audit
|
Просмотр состояния/конфигурации узла, конфигурации кластера Corosync и конфигурации HA
|
|
Sys.Modify
|
Создание/удаление/изменение параметров сети узла
|
|
Sys.Incoming
|
Разрешить входящие потоки данных из других кластеров (экспериментально)
|
|
Group.Allocate
|
Создание/удаление/изменение групп
|
|
Pool.Allocate
|
Создание/удаление/изменение пулов
|
|
Pool.Audit
|
Просмотр пула
|
|
Realm.Allocate
|
Создание/удаление/изменение областей аутентификации
|
|
Realm.AllocateUser
|
Назначение пользователю области аутентификации
|
|
SDN.Allocate
|
Управление конфигурацией SDN
|
|
SDN.Audit
|
Просмотр конфигурации SDN
|
|
User.Modify
|
Создание/удаление/изменение пользователя
|
|
Права, связанные с ВМ
|
|
|
VM.Allocate
|
Создание/удаление ВМ
|
|
VM.Migrate
|
Миграция ВМ на альтернативный сервер в кластере
|
|
VM.PowerMgmt
|
Управление питанием (запуск, остановка, сброс, выключение)
|
|
VM.Console
|
Консольный доступ к ВМ
|
|
VM.Monitor
|
Доступ к монитору виртуальной машины (kvm)
|
|
VM.Backup
|
Резервное копирование/восстановление ВМ
|
|
VM.Audit
|
Просмотр конфигурации ВМ
|
|
VM.Clone
|
Клонирование/копирование ВМ
|
|
VM.Config.Disk
|
Добавление/изменение/удаление дисков ВМ
|
|
VM.Config.CDROM
|
Извлечение/изменение CDROM
|
|
VM.Config.CPU
|
Изменение настроек процессора
|
|
VM.Config.Memory
|
Изменение настроек памяти
|
|
VM.Config.Network
|
Добавление/изменение/удаление сетевых устройств
|
|
VM.Config.HWType
|
Изменение типа эмуляции
|
|
VM.Config.Options
|
Изменение любой другой конфигурации ВМ
|
|
VM.Config.Cloudinit
|
Изменение параметров Cloud-init
|
|
VM.Snapshot
|
Создание/удаление снимков ВМ
|
|
VM.Snapshot.Rollback
|
Откат ВМ к одному из её снимков
|
|
Права, связанные с хранилищем
|
|
|
Datastore.Allocate
|
Создание/удаление/изменение хранилища данных
|
|
Datastore.AllocateSpace
|
Выделить место в хранилище
|
|
Datastore.AllocateTemplate
|
Размещение/загрузка шаблонов контейнеров и ISO-образов
|
|
Datastore.Audit
|
Просмотр хранилища данных
|
/nodes/{node} — доступ к узлам PVE;
/vms — распространяется на все ВМ;
/vms/{vmid} — доступ к определенным ВМ;
/storage/{storeid} — доступ к определенным хранилищам;
/pool/{poolid} — доступ к ресурсам из определенного пула ресурсов;
/access/groups — администрирование групп;
/access/realms/{realmid} — административный доступ к области аутентификации.


# pveum acl modify / --groups admin --roles Administrator
# pveum acl modify /vms --users test@pve --roles PVEAuditor
# pveum acl modify /access --users test@pve --roles PVEUserAdmin
#pveum acl modify /access/realm/test.alt --users orlov@test.alt --roles PVEUserAdmin#pveum acl modify /access/groups/office-test.alt --users orlov@test.alt --roles PVEUserAdmin
# pveum acl modify /pool/IT/ --groups developers --roles PVEAdmin
# pveum acl delete /vms --users test@pve --roles PVEAuditor
Примечание
pvenode task приведены в таблице Команды pvenode task.
Таблица 54.1. Команды pvenode task
|
Команда
|
Описание
|
|---|---|
pvenode task list [Параметры]
|
Вывести список выполненных задач для данного узла.
|
pvenode task log <vmid> [Параметры]
|
Вывести журнал задачи.
|
pvenode task status <upid>
|
Вывести статус задачи.
|
Примечание
UPID:$node:$pid:$pstart:$starttime:$dtype:$id:$userpid, pstart и starttime имеют шестнадцатеричную кодировку.
pvenode task:
# pvenode task list --errors --vmid 105
Список задач будет представлен в виде таблицы:
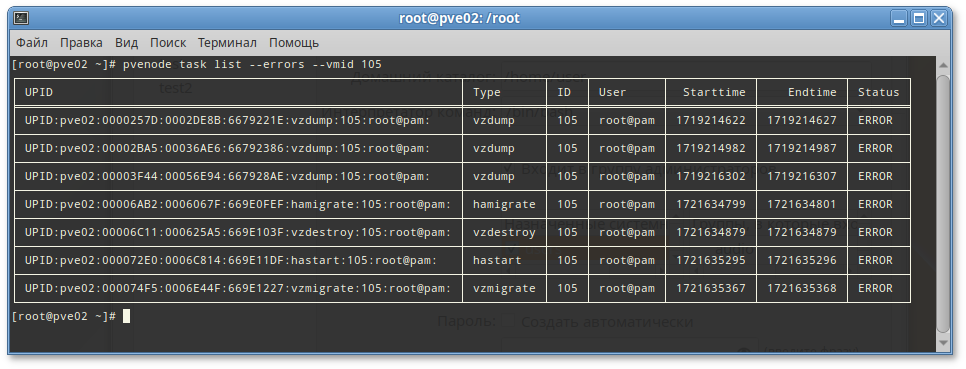
# pvenode task list --userfilter user
# pvenode task log UPID:pve02:0000257D:0002DE8B:6679221E:vzdump:105:root@pam:
INFO: starting new backup job: vzdump 105 --node pve02 --compress zstd --mailnotification always --notes-template '{{guestname}}' --storage nfs-backup --quiet 1 --mailto test@basealt.ru --mode snapshot
INFO: Starting Backup of VM 105 (lxc)
INFO: Backup started at 2024-06-24 09:37:03
INFO: status = stopped
INFO: backup mode: stop
INFO: ionice priority: 7
INFO: CT Name: NewLXC
INFO: including mount point rootfs ('/') in backup
INFO: creating vzdump archive '/mnt/pve/nfs-backup/dump/vzdump-lxc-105-2024_06_24-09_37_03.tar.zst'
ERROR: Backup of VM 105 failed - volume 'local:105/vm-105-disk-0.raw' does not exist
INFO: Failed at 2024-06-24 09:37:04
INFO: Backup job finished with errors
postdrop: warning: unable to look up public/pickup: No such file or directory
TASK ERROR: job errors
# pvenode task status UPID:pve02:0000257D:0002DE8B:6679221E:vzdump:105:root@pam:
┌────────────┬────────────────────────────────────────────────────────────┐
│ key │ value │
╞════════════╪════════════════════════════════════════════════════════════╡
│ exitstatus │ job errors │
├────────────┼────────────────────────────────────────────────────────────┤
│ id │ 105 │
├────────────┼────────────────────────────────────────────────────────────┤
│ node │ pve02 │
├────────────┼────────────────────────────────────────────────────────────┤
│ pid │ 9597 │
├────────────┼────────────────────────────────────────────────────────────┤
│ starttime │ 1719214622 │
├────────────┼────────────────────────────────────────────────────────────┤
│ status │ stopped │
├────────────┼────────────────────────────────────────────────────────────┤
│ type │ vzdump │
├────────────┼────────────────────────────────────────────────────────────┤
│ upid │ UPID:pve02:0000257D:0002DE8B:6679221E:vzdump:105:root@pam: │
├────────────┼────────────────────────────────────────────────────────────┤
│ user │ root@pam │
└────────────┴────────────────────────────────────────────────────────────┘

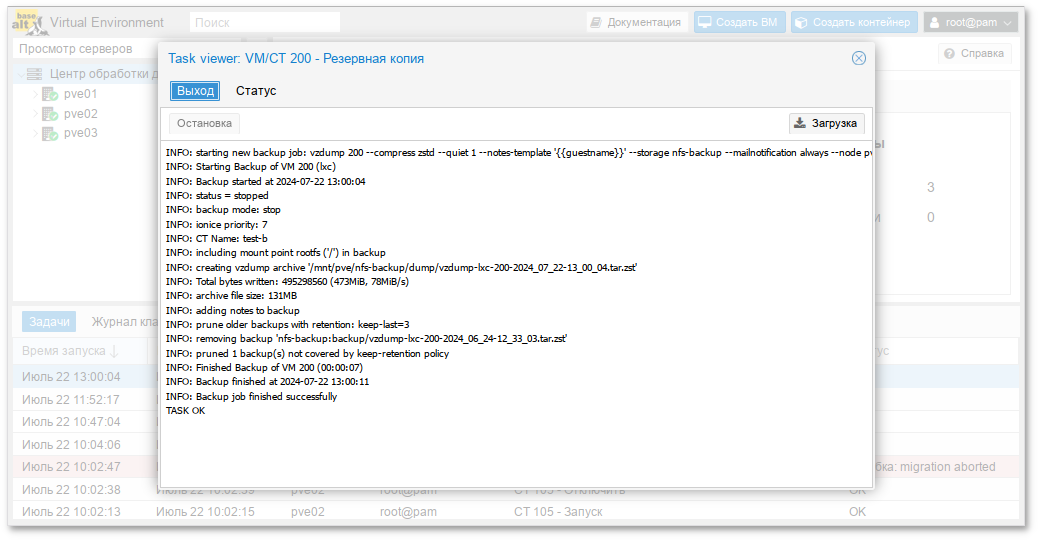
Примечание
Примечание




pvesh (см.ниже), доступна в веб-API, поскольку они используют одну и ту же конечную точку.
-H или --header для отправки заголовков HTTP) и т. д.;
-d или --data при запросах POST, PUT, PATCH или DELETE.
Примечание
--data-urlencode.
curl.
Примечание
/var/lib/rrdcached/, например, выполнив команду:
# find /var/lib/rrdcached -type f -mtime +5 -delete
Или, добавив соответствующее задание в crontab.
$ curl -k -d 'username=root@pam' --data-urlencode 'password=xxxxxxxxx' \
https://192.168.0.186:8006/api2/json/access/ticket
Примечание
$ curl -k -d 'username=root@pam' --data-urlencode "password@$HOME/.pve-pass-file" \
https://192.168.0.186:8006/api2/json/access/ticket
Примечание
jq (должен быть установлен пакет jq):
$ curl -k -d 'username=root@pam' --data-urlencode "password@$HOME/.pve-pass-file" \
https://192.168.0.186:8006/api2/json/access/ticket | jq
{
"data": {
"ticket":"PVE:root@pam:66AA52D6::d85E+IIFAuG731…",
"CSRFPreventionToken":"66AA52D6:Y2zvIXjRVpxx4ZG74F14Ab0EHn8NRoso/WmVqZEnAuM",
"username":"root@pam"
}
}
Примечание
$ curl -k -b "PVEAuthCookie=PVE:root@pam:66AA52D6::d85E+IIFAuG731…" \
https://192.168.0.186:8006/api2/json/
Ответ:
{
"data": [
{ "subdir": "version" },
{ "subdir": "cluster" },
{ "subdir": "nodes" },
{ "subdir": "storage" },
{ "subdir": "access" },
{ "subdir": "pools" }
]
}
Примечание
--cookie (-b).
$ curl -k -XDELETE \
'https://pve01:8006/api2/json/access/users/testuser@pve' \
-b "PVEAuthCookie=PVE:root@pam:66AA52D6::d85E+IIFAuG731…" \
-H "CSRFPreventionToken: 66AA52D6:Y2zvIXjRVpxx4ZG74F14Ab0EHn8NRoso/WmVqZEnAuM"
$ curl -H 'Authorization: PVEAPIToken=root@pam!test=373007e1-4ecb-4e56-b843-d0fbed543375' \
https://192.168.0.186:8006/api2/json/access/users
$ curl -k -X 'POST' \
'https://pve01:8006/api2/json/access/users' \
--data-urlencode 'userid=testuser@pve' \
-H 'Authorization: PVEAPIToken=root@pam!test=373007e1-4ecb-4e56-b843-d0fbed543375'
$ curl -k -X 'DELETE' \
'https://pve01:8006/api2/json/access/users/testuser@pve' \
-H 'Authorization: PVEAPIToken=root@pam!test=373007e1-4ecb-4e56-b843-d0fbed543375'
Примечание
curl: (60) SSL certificate problem: unable to get local issuer certificateможно дополнить запрос опцией
--insecure (-k), для отключения проверки валидности сертификатов:
$ curl -k -H 'Authorization: PVEAPIToken=root@pam!test=373007e1-4ecb-4e56-b843-d0fbed543375' \
https://192.168.0.186:8006/api2/json/
Примечание
cookie — файл, в который будет помещен cookie;
csrftoken — файл, в который будет помещен CSRF-токен.
$export APINODE=pve01$export TARGETNODE=pve03
cookie:
$ curl --silent --insecure --data "username=root@pam&password=yourpassword" \
https://$APINODE:8006/api2/json/access/ticket \
| jq --raw-output '.data.ticket' | sed 's/^/PVEAuthCookie=/' > cookie
csrftoken:
$ curl --silent --insecure --data "username=root@pam&password=yourpassword" \
https://$APINODE:8006/api2/json/access/ticket \
| jq --raw-output '.data.CSRFPreventionToken' | sed 's/^/CSRFPreventionToken:/' > csrftoken
$ curl --insecure --cookie "$(<cookie)" https://$APINODE:8006/api2/json/nodes/$TARGETNODE/status | jq '.'
$ curl --silent --insecure --cookie "$(<cookie)" --header "$(<csrftoken)" -X POST\
--data-urlencode net0="name=myct0,bridge=vmbr0" \
--data-urlencode ostemplate="local:vztmpl/alt-p10-rootfs-systemd-x86_64.tar.xz" \
--data vmid=601 \
https://$APINODE:8006/api2/json/nodes/$TARGETNODE/lxc
{"data":"UPID:pve03:00005470:00083F6D:66A76C80:vzcreate:601:root@pam:"}
Команда должна вернуть структуру JSON, содержащую идентификатор задачи (UPID).
Примечание
# pvesh ls /
Dr--- access
Dr--- cluster
Dr--- nodes
Dr-c- pools
Dr-c- storage
-r--- version
Примечание
pvesh может использовать только пользователь root.
# pvesh get /version
# pvesh get /nodes
# pvesh usage cluster/options -v
# pvesh create /access/users --userid testuser@pve
# pvesh delete /access/users/testuser@pve
# pvesh set cluster/options -console html5
#pvesh createnodes/pve03/lxc -vmid 210 -hostname test --storage local \ --password "supersecret" \ --ostemplate nfs-storage:vztmpl/alt-p10-rootfs-systemd-x86_64.tar.xz \ --memory 512 --swap 512 UPID:pve03:0000286E:0003553C:66A75FE7:vzcreate:210:root@pam: #pvesh create/nodes/pve03/lxc/210/status/start UPID:pve03:0000294B:00036B33:66A7601F:vzstart:210:root@pam
# pvedaemon help
# pvedaemon restart
# pvedaemon start
# pvedaemon start --debug 1
# pvedaemon status
# pvedaemon stop
pvedaemon предоставляет весь API PVE на 127.0.0.1:85. Она работает от имени пользователя root и имеет разрешение на выполнение всех привилегированных операций.
Примечание
pveproxy предоставляет весь PVE API на TCP-порту 8006 с использованием HTTPS. Она работает от имени пользователя www-data и имеет минимальные разрешения. Операции, требующие дополнительных разрешений, перенаправляются локальному pvedaemon.
/etc/default/pveproxy. Например:
ALLOW_FROM="10.0.0.1-10.0.0.5,192.168.0.0/22" DENY_FROM="all" POLICY="allow"IP-адреса можно указывать с использованием любого синтаксиса, понятного Net::IP. Ключевое слово all является псевдонимом для 0/0 и ::/0 (все адреса IPv4 и IPv6).
Таблица 56.1. Правила обработки запросов
|
Соответствие
|
POLICY=deny
|
POLICY=allow
|
|---|---|---|
|
Соответствует только Allow
|
Запрос разрешён
|
Запрос разрешён
|
|
Соответствует только Deny
|
Запрос отклонён
|
Запрос отклонён
|
|
Нет соответствий
|
Запрос отклонён
|
Запрос разрешён
|
|
Соответствует и Allow и Deny
|
Запрос отклонён
|
Запрос разрешён
|
pveproxy и spiceproxy прослушивают подстановочный адрес и принимают соединения от клиентов как IPv4, так и IPv6.
LISTEN_IP в /etc/default/pveproxy, можно контролировать, к какому IP-адресу будут привязываться службы pveproxy и spiceproxy. IP-адрес должен быть настроен в системе.
sysctl net.ipv6.bindv6only в значение 1 приведет к тому, что службы будут принимать соединения только от клиентов IPv6, что может вызвать множество проблем. Если устанавливается эта конфигурация, рекомендуется либо удалить настройку sysctl, либо установить LISTEN_IP в значение 0.0.0.0 (что позволит использовать только клиентов IPv4).
LISTEN_IP можно использовать только для ограничения сокета внутренним интерфейсом, например:
LISTEN_IP="192.168.0.186"Аналогично можно задать IPv6-адрес:
LISTEN_IP="2001:db8:85a3::1"Если указывается локальный IPv6-адрес, необходимо указать имя интерфейса, например:
LISTEN_IP="fe80::c463:8cff:feb9:6a4e%vmbr0"
Примечание
LISTEN_IP в кластерных системах.
pveproxy и spiceproxy:
# systemctl restart pveproxy.service spiceproxy.service
Примечание
pveproxy, в отличие от перезагрузки конфигурации (reload), может прервать некоторые рабочие процессы, например, запущенную консоль или оболочку ВМ. Поэтому следует дождаться остановки системы на обслуживание, чтобы это изменение вступило в силу.
/etc/default/pveproxy с помощью ключей CIPHERS (TLS = 1.2) и CIPHERSUITES (TLS >= 1.3), например:
CIPHERS="ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA256" CIPHERSUITES="TLS_AES_256_GCM_SHA384:TLS_CHACHA20_POLY1305_SHA256:TLS_AES_128_GCM_SHA256"
/etc/default/pveproxy (по умолчанию используется первый шифр в списке, доступном как клиенту, так и pveproxy):
HONOR_CIPHER_ORDER=0
/etc/default/pveproxy:
DISABLE_TLS_1_2=1или, соответственно:
DISABLE_TLS_1_3=1
Примечание
/etc/default/pveproxy, указав в параметре DHPARAMS путь к файлу, содержащему параметры DH в формате PEM, например:
DHPARAMS="/path/to/dhparams.pem"
Примечание
pveproxy использует /etc/pve/local/pveproxy-ssl.pem и /etc/pve/local/pveproxy-ssl.key, если они есть, или /etc/pve/local/pve-ssl.pem и /etc/pve/local/pve-ssl.key в противном случае. Закрытый ключ не может использовать парольную фразу.
/etc/pve/local/pveproxy-ssl.key, установив TLS_KEY_FILE в /etc/default/pveproxy, например:
TLS_KEY_FILE="/secrets/pveproxy.key"
pveproxy использует сжатие gzip HTTP-уровня для сжимаемого контента, если клиент его поддерживает. Это поведение можно отключить в /etc/default/pveproxy:
COMPRESSION=0
pveproxy запрашивает статус ВМ, хранилищ и контейнеров через регулярные интервалы. Результат отправляется на все узлы кластера.
spiceproxy прослушивает TCP-порт 3128 и реализует HTTP-прокси для пересылки запроса CONNECT от SPICE-клиента к ВМ PVE. Она работает от имени пользователя www-data и имеет минимальные разрешения.
/etc/default/pveproxy. Подробнее см. pveproxy — служба PVE API Proxy
pvescheduler отвечает за запуск заданий по расписанию, например, заданий репликации и vzdump.
/etc/pve/jobs.cfg.
virt-install, virt-clone, virsh и других. Для управления из графической оболочки можно воспользоваться virt-manager.
Содержание
Примечание
Примечание
#apt-get update#apt-get install libvirt-kvm
# systemctl enable --now libvirtd
# gpasswd -a user vmusers
/etc/libvirt/ — каталог с файлами конфигурации libvirt;
/var/lib/libvirt/ — рабочий каталог сервера виртуализации libvirt;
/var/log/libvirt — файлы журналов libvirt.
qemu-img — управление образами дисков ВМ. Позволяет выполнять операции по созданию образов различных форматов, конвертировать файлы-образы между этими форматами, получать информацию об образах и объединять снимки ВМ для тех форматов, которые это поддерживают;
virsh — консольный интерфейс управления ВМ, виртуальными дисками и виртуальными сетями;
virt-clone — клонирование ВМ;
virt-install — создание ВМ с помощью опций командной строки;
virt-xml — редактирование XML-файлов описаний ВМ.
virsh — утилита для командной строки, предназначенная для управления ВМ и гипервизорами KVM.
virsh использует libvirt API и служит альтернативой графическому менеджеру виртуальных машин (virt-manager).
virsh можно сохранять состояние ВМ, переносить ВМ между гипервизорами и управлять виртуальными сетями.
virsh, можно используя команду:
$ virsh help
Таблица 58.1. Утилита командной строки virsh. Команды управления виртуальными машинами
|
Команда
|
Описание
|
|---|---|
|
help
|
Краткая справка
|
|
list
|
Просмотр всех ВМ
|
|
dumpxml
|
Вывести файл конфигурации XML для заданной ВМ
|
|
create
|
Создать ВМ из файла конфигурации XML и ее запуск
|
|
start
|
Запустить неактивную ВМ
|
|
destroy
|
Принудительно остановить работу ВМ
|
|
define
|
Определяет файл конфигурации XML для заданной ВМ
|
|
domid
|
Просмотр идентификатора ВМ
|
|
domuuid
|
Просмотр UUID ВМ
|
|
dominfo
|
Просмотр сведений о ВМ
|
|
domname
|
Просмотр имени ВМ
|
|
domstate
|
Просмотр состояния ВМ
|
|
quit
|
Закрыть интерактивный терминал
|
|
reboot
|
Перезагрузить ВМ
|
|
restore
|
Восстановить сохраненную в файле ВМ
|
|
resume
|
Возобновить работу приостановленной ВМ
|
|
save
|
Сохранить состояние ВМ в файл
|
|
shutdown
|
Корректно завершить работу ВМ
|
|
suspend
|
Приостановить работу ВМ
|
|
undefine
|
Удалить все файлы ВМ
|
|
migrate
|
Перенести ВМ на другой узел
|
Таблица 58.2. Утилита командной строки virsh. Параметры управления ресурсами ВМ и гипервизора
|
Команда
|
Описание
|
|---|---|
|
setmem
|
Определяет размер выделенной ВМ памяти
|
|
setmaxmem
|
Ограничивает максимально доступный гипервизору объем памяти
|
|
setvcpus
|
Изменяет число предоставленных ВМ виртуальных процессоров
|
|
vcpuinfo
|
Просмотр информации о виртуальных процессорах
|
|
vcpupin
|
Настройка соответствий виртуальных процессоров
|
|
domblkstat
|
Просмотр статистики блочных устройств для работающей ВМ
|
|
domifstat
|
Просмотр статистики сетевых интерфейсов для работающей ВМ
|
|
attach-device
|
Подключить определенное в XML-файле устройство к ВМ
|
|
attach-disk
|
Подключить новое дисковое устройство к ВМ
|
|
attach-interface
|
Подключить новый сетевой интерфейс к ВМ
|
|
detach-device
|
Отключить устройство от ВМ (принимает те же определения XML, что и attach-device)
|
|
detach-disk
|
Отключить дисковое устройство от ВМ
|
|
detach-interface
|
Отключить сетевой интерфейс от ВМ
|
virt-install — это инструмент для создания ВМ, основанный на командной строке.
Примечание
# apt-get install virt-install
virt-install можно получить, выполнив команду:
$ man virt-install
Таблица 58.3. Параметры команды virt-install
|
Команда
|
Описание
|
|---|---|
|
-n NAME, --name=NAME
|
Имя новой ВМ. Это имя должно быть уникально внутри одного гипервизора
|
|
--memory MEMORY
|
Определяет размер выделенной ВМ памяти, например:
|
|
--vcpus VCPUS
|
Определяет количество виртуальных ЦПУ, например:
|
|
--cpu CPU
|
Модель ЦП и его характеристики, например:
|
|
--metadata METADATA
|
Метаданные ВМ
|
|
Метод установки
|
|
|
--cdrom CDROM
|
Установочный CD-ROM. Может указывать на файл ISO-образа или на устройство чтения CD/DVD-дисков
|
|
-l LOCATION, --location LOCATION
|
Источник установки, например,
https://host/path
|
|
--pxe
|
Выполнить загрузку из сети используя протокол PXE
|
|
--import
|
Пропустить установку ОС, и создать ВМ на основе существующего образа диска
|
|
--boot BOOT
|
Параметры загрузки ВМ, например:
|
|
--os-variant=DISTRO_VARIANT
|
ОС, которая устанавливается в гостевой системе. Используется для выбора оптимальных значений по умолчанию, в том числе VirtIO. Примеры значений: alt.p10, alt10.1, win10
|
|
--disk DISK
|
Настройка пространства хранения данных, например:
|
|
-w NETWORK, --network NETWORK
|
Конфигурация сетевого интерфейса ВМ, например:
|
|
--graphics GRAPHICS
|
Настройки экрана ВМ, например:
|
|
--input INPUT
|
Конфигурация устройства ввода, например:
|
|
--hostdev HOSTDEV
|
Конфигурация физических USB/PCI и других устройств хоста для совместного использования ВМ
|
|
-filesystem FILESYSTEM
|
Передача каталога хоста гостевой системе, например:
|
|
Параметры платформы виртуализации
|
|
|
-v, --hvm
|
Эта ВМ должна быть полностью виртуализированной
|
|
-p, --paravirt
|
Эта ВМ должна быть паравиртуализированной
|
|
--container
|
Тип ВМ — контейнер
|
|
--virt-type VIRT_TYPE
|
Тип гипервизора (kvm, qemu и т.п.)
|
|
--arch ARCH
|
Имитируемая архитектура процессора
|
|
--machine MACHINE
|
Имитируемый тип компьютера
|
|
Прочие параметры
|
|
|
--autostart
|
Запускать домен автоматически при запуске хоста
|
|
--transient
|
Создать временный домен
|
|
--noautoconsole
|
Не подключаться к гостевой консоли автоматически
|
|
-q, --quiet
|
Подавлять вывод (за исключением ошибок)
|
|
-d, --debug
|
Вывести отладочные данные
|
virt-install.
virt-install поддерживает как графическую установку операционных систем при помощи VNC и Spice, так и текстовую установку через последовательный порт. Гостевая система может быть настроена на использование нескольких дисков, сетевых интерфейсов, аудиоустройств и физических USB и PCI-устройств.
virt-install получает минимальный набор файлов для запуска установки и позволяет установщику получить отдельные файлы. Поддерживается также загрузка по сети (PXE) и создание виртуальной машины/контейнера без этапа установки ОС или загрузка по сети предустановленной системы.
virt-install поддерживает большое число опции, позволяющих создать полностью независимую ВМ, готовую к работе, что хорошо подходит для автоматизации установки ВМ.
qemu-img — инструмент для манипулирования с образами дисков машин QEMU.
qemu-img [standard options] command [command options]
create — создание нового образа диска;
check — проверка образа диска на ошибки;
convert — конвертация существующего образа диска в другой формат;
info — получение информации о существующем образе диска;
snapshot — управляет снимками состояний (snapshot) существующих образов дисков;
commit — записывает произведенные изменения на существующий образ диска;
rebase — создает новый базовый образ на основании существующего.
qemu-img работает со следующими форматами:
qemu-img info или ls -ls;
# qemu-img info /var/lib/libvirt/images/alt-server.qcow2
mage: /var/lib/libvirt/images/alt-server.qcow2
file format: qcow2
virtual size: 20 GiB (21474836480 bytes)
disk size: 3.32 MiB
cluster_size: 65536
Format specific information:
compat: 1.1
compression type: zlib
lazy refcounts: true
refcount bits: 16
corrupt: false
extended l2: false
# qemu-img create -f qcow2 /var/lib/libvirt/images/hdd.qcow2 20G
# qemu-img convert -f raw -O qcow2 disk_hd.img disk_hd.qcow2
virt-manager предоставляет графический интерфейс для доступа к гипервизорам и ВМ в локальной и удаленных системах. С помощью virt-manager можно создавать ВМ. Кроме того, virt-manager выполняет управляющие функции:
Примечание


$где 192.168.0.175 — IP-адрес сервера с libvirt.ssh-keygen -t ed25519$ssh-copy-id user@192.168.0.175
virsh -c URI
URI не задан, то libvirt попытается определить наиболее подходящий гипервизор.
URI может принимать следующие значения:
$ virsh -c qemu:///system list --all
ID Имя Состояние
------------------------------
- alt-server выключен
Примечание
-c qemu:///system можно добавить:
export LIBVIRT_DEFAULT_URI=qemu:///system
$ virsh -c qemu+ssh://user@192.168.0.175/system
Добро пожаловать в virsh — интерактивный терминал виртуализации.
Введите «help» для получения справки по командам
«quit», чтобы завершить работу и выйти.
virsh #
где:
virt-manager, выполнив следующую команду:
$ virt-manager -c qemu+ssh://user@192.168.0.175/system
где:

virsh и virt-install или из пользовательского интерфейса программы virt-manager.
$ virsh create guest.xml
Domain 'altK' created from guest.xml
dumpxml:
virsh dumpxml <domain>
guest.xml:
$ virsh -c qemu:///system dumpxml alt-server > guest.xml
Примечание
--name, --memory, хранилище (--disk, --filesystem или --nodisks) и опции установки.
virt-install, необходимо сначала загрузить ISO-образ той ОС, которая будет устанавливаться.
# virt-install --connect qemu:///system \
--name alt-server-test \
--os-variant=alt10.0 \
--cdrom /var/lib/libvirt/images/alt-server-10.2-x86_64.iso \
--graphics spice,listen=0.0.0.0 \
--video qxl \
--disk pool=default,size=20,bus=virtio,format=qcow2 \
--memory 2048 \
--vcpus=2 \
--network network=default \
--hvm \
--virt-type=kvm
где:
--name alt-server — название ВМ;
--os-variant=alt10.0 — версия ОС;
--cdrom /var/lib/libvirt/images/alt-server-10.2-x86_64.iso — путь к ISO-образу установочного диска ОС;
--graphics spice,listen=0.0.0.0 — графическая консоль;
--disk pool=default,size=20,bus=virtio,format=qcow2 — хранилище. ВМ будет создана в пространстве хранения объемом 20 ГБ, которое автоматически выделяется из пула хранилищ default. Образ диска для этой виртуальной машины будет создан в формате qcow2;
--memory 2048 — объем оперативной памяти;
--vcpus=2 — количество процессоров;
--network network=default — виртуальная сеть default;
--hvm — полностью виртуализированная система;
--virt-type=kvm — использовать модуль ядра KVM, который задействует аппаратные возможности виртуализации процессора.
virt-install оптимизируют ВМ для использования в качестве полностью виртуализированной системы (--hvm) и указывают, что KVM является базовым гипервизором (--virt-type) для поддержки новой ВМ. Обе этих опции обеспечивают определенную оптимизацию в процессе создания и установки операционной системы; если эти опции не заданы в явном виде, то вышеуказанные значения применяются по умолчанию.
Примечание
# virt-install --connect qemu:///system \
--name alt-server-test \
--os-variant=alt10.0 \
--cdrom /var/lib/libvirt/images/alt-server-10.2-x86_64.iso \
--graphics spice,listen=0.0.0.0 \
--video qxl \
--disk pool=default,size=20,bus=virtio,format=qcow2 \
--memory 2048 \
--vcpus=2 \
--network network=default \
--hvm \
--virt-type=kvm \
--boot loader=/usr/share/OVMF/OVMF_CODE.fd
где /usr/share/OVMF/OVMF_CODE.fd — путь к UEFI загрузчику.
$ osinfo-query os
# virt-install \
--hvm \
--name demo \
--memory 500 \
--nodisks \
--livecd \
--graphics vnc \
--cdrom /var/lib/libvirt/images/altlive.iso
/bin/bash в контейнере (LXC), с ограничением памяти в 512 МБ и одним ядром хост-системы:
# virt-install \
--connect lxc:/// \
--name bash_guest \
--memory 512 \
--vcpus 1 \
--init /bin/bash
# virt-install \
--name demo \
--memory 512 \
--disk /home/user/VMs/mydisk.img \
--import





Примечание


start — запуск ВМ;
shutdown — завершение работы. Поведение выключаемой ВМ можно контролировать с помощью параметра on_shutdown (в файле конфигурации);
destroy — принудительная остановка. Использование virsh destroy может повредить гостевые файловые системы. Рекомендуется использовать опцию shutdown;
reboot — перезагрузка ВМ. Поведение перезагружаемой ВМ можно контролировать с помощью параметра on_reboot (в файле конфигурации);
suspend — приостановить ВМ. Когда ВМ находится в приостановленном состоянии, она потребляет системную оперативную память, но не ресурсы процессора;
resume — возобновить работу приостановленной ВМ;
save — сохранение текущего состояния ВМ. Эта команда останавливает ВМ, сохраняет данные в файл, что может занять некоторое время (зависит от объема ОЗУ ВМ);
restore — восстановление ВМ, ранее сохраненной с помощью команды virsh save. Сохраненная машина будет восстановлена из файла и перезапущена (это может занять некоторое время). Имя и идентификатор UUID ВМ останутся неизменными, но будет предоставлен новый идентификатор домена;
undefine — удалить ВМ (конфигурационный файл тоже удаляется);
autostart — добавить ВМ в автозагрузку;
autostart --disable — удалить из автозагрузки;
#virsh destroy alt-server#virsh undefine alt-server



# virsh edit alt-server
Добавить графический элемент SPICE, например:
<graphics type='spice' port='5900' autoport='yes' listen='127.0.0.1'>
<listen type='address' address='127.0.0.1'/>
</graphics>
Добавить видеоустройство QXL:
<video>
<model type='qxl'/>
</video>
# virsh domdisplay alt-server
spice://127.0.0.1:5900
<graphics type='spice' port='5900' autoport='yes' listen='0.0.0.0' passwd='mypasswd'>
<listen type='address' address='0.0.0.0'/>
</graphics>

$virt-viewer -c qemu+ssh://user@192.168.0.175/system -d alt-server$remote-viewer "spice://192.168.0.175:5900"
Примечание
<graphics type='vnc' port='5900' autoport='no' listen='0.0.0.0' passwd='mypasswd'>
<listen type='address' address='0.0.0.0'/>
</graphics>

# virsh domdisplay alt-server
vnc://localhost:0
$virt-viewer -c qemu+ssh://user@192.168.0.175/system -d alt-server$vncviewer 192.168.0.175:5900
virsh edit. Например, команда редактирования ВМ с именем alt-server:
# virsh edit alt-server
virsh dominfo <domain>
где [--domain] <строка> — имя, ID или UUID домена.
virsh dominfo:
# virsh dominfo alt-server
ID: 3
Имя: alt-server
UUID: ccb6bf9e-1f8d-448e-b5f7-fa274703500b
Тип ОС: hvm
Состояние: работает
CPU: 2
Время CPU: 90,9s
Макс.память: 2097152 KiB
Занято памяти: 2097152 KiB
Постоянство: yes
Автозапуск: выкл.
Управляемое сохранение: no
Модель безопасности: none
DOI безопасности: 0
# virsh nodeinfo
Модель процессора: x86_64
CPU: 8
Частота процессора: 2827 MHz
Сокеты: 1
Ядер на сокет: 4
Потоков на ядро: 2
Ячейки NUMA: 1
Объём памяти: 8007952 KiB
virsh list
virsh list:
--inactive — показать список неактивных доменов;
--all — показать все ВМ независимо от их состояния.
virsh list:
# virsh list --all
ID Имя Состояние
--------------------------
3 alt-server работает
virsh suspend. В приостановленном состоянии ВМ продолжает потреблять ресурсы, но не может занимать больше процессорных ресурсов;
virsh vcpuinfo <domain>
# virsh vcpuinfo alt-server
Виртуальный процессор:: 0
CPU: 6
Состояние: работает
Время CPU: 67,6s
Соответствие ЦП: yyyyyyyy
Виртуальный процессор:: 1
CPU: 7
Состояние: работает
Время CPU: 7,1s
Соответствие ЦП: yyyyyyyy
virsh vcpupin <domain> [--vcpu <число>] [--cpulist <строка>] [--config] [--live] [--current]
Здесь:
[--domain] <строка> — имя, ID или UUID домена;
--vcpu <число> — номер виртуального процессора;
--cpulist <строка> — номера физических процессоров. Если номера не указаны, команда вернет текущий список процессоров;
--config — с сохранением после перезагрузки;
--live — применить к работающему домену;
--current — применить к текущему домену.
# virsh vcpupin alt-server
Виртуальный процессор: Соответствие ЦП
-------------------------------------------
0 0-7
1 0-7
virsh setvcpus <domain> <count> [--maximum] [--config] [--live] [--current] [--guest] [--hotpluggable]
где:
[--domain] <строка> — имя, ID или UUID домена;
[--count] <число> — число виртуальных процессоров;
--maximum — установить максимальное ограничение на количество виртуальных процессоров, которые могут быть подключены после следующей перезагрузки домена;
--guest — состояние процессоров ограничивается гостевым доменом.
virsh setmem <domain> <size> [--config] [--live] [--current]
где:
[--domain] <строка> — имя, ID или UUID домена;
[--size] <число> — целое значение нового размера памяти (по умолчанию в КБ).
virsh setmaxmem <domain> <size> [--config] [--live] [--current]
где:
[--domain] <строка> — имя, ID или UUID домена;
[--size] <число> — целое значение максимально допустимого размера памяти (по умолчанию в КБ).
#virsh setmaxmem --size 624000 alt-server#virsh setmem --size 52240 alt-server#virsh setvcpus --config alt-server 3 --maximum
virsh domblkstat <domain> [--device <строка>] [--human]
где:
[--domain] <строка> — имя, ID или UUID домена;
--device <строка> — блочное устройство;
--human — форматировать вывод.
virsh domifstat <domain> <interface>
где:
[--domain] <строка> — имя, ID или UUID домена;
[--interface] <строка> — устройство интерфейса, указанное по имени или MAC-адресу.







$ ip addr show virbr0
9: virbr0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 52:54:00:6e:93:97 brd ff:ff:ff:ff:ff:ff
inet 192.168.122.1/24 brd 192.168.122.255 scope global virbr0
valid_lft forever preferred_lft forever
scp для копирования файлов туда и обратно.
Примечание
dev=<interface> или в virt-manager при создании новой виртуальной сети.
virsh net-autostart имя_сети — автоматический запуск заданной сети;
virsh net-autostart имя_сети --disable — отключить автозапуск заданной сети;
virsh net-create файл_XML — создание и запуск новой сети на основе существующего XML-файла;
virsh net-define файл_XML — создание нового сетевого устройства на основе существующего XML-файла (устройство не будет запущено);
virsh net-destroy имя_сети — удаление заданной сети;
virsh net-dumpxml имя_сети —просмотр информации о заданной виртуальной сети (в формате xml);
virsh net-info имя_сети — просмотр основной информации о заданной виртуальной сети;
virsh net-list — просмотр списка виртуальных сетей;
virsh net-name UUID_сети — преобразование заданного идентификатора в имя сети;
virsh net-start имя_неактивной_сети — запуск неактивной сети;
virsh net-uuid имя_сети — преобразование заданного имени в идентификатор UUID;
virsh net-update имя_сети — обновить существующую конфигурацию сети;
virsh net-undefine имя_неактивной_сети — удаление определения неактивной сети.
#virsh net-list --allИмя Состояние Автозапуск Постоянный ------------------------------------------------- default не активен no yes #virsh net-start defaultСеть default запущена #virsh net-autostart defaultДобавлена метка автоматического запуска сети default #virsh net-listИмя Состояние Автозапуск Постоянный ------------------------------------------------ default активен yes yes #virsh net-dumpxml default<network connections='1'> <name>default</name> <uuid>8880a2ae-a71d-4be4-8006-30cf095f77a4</uuid> <forward mode='nat'> <nat> <port start='1024' end='65535'/> </nat> </forward> <bridge name='virbr0' stp='on' delay='0'/> <mac address='52:54:00:3e:12:c7'/> <ip address='192.168.122.1' netmask='255.255.255.0'> <dhcp> <range start='192.168.122.2' end='192.168.122.254'/> </dhcp> </ip> </network> #virsh net-info defaultИмя: default UUID: 8880a2ae-a71d-4be4-8006-30cf095f77a4 Активен: yes Постоянство: yes Автозапуск: yes Мост: virbr0
# virsh dumpxml alt-server | grep 'mac address'
<mac address='52:54:00:ba:f2:76'/>
# virsh net-edit default
<range start='192.168.122.2' end='192.168.122.254'/>Вставить строки с MAC-адресами виртуальных адаптеров:
<host mac='52:54:00:ba:f2:76' name='alt-server' ip='192.168.122.50'/>
#virsh net-destroy default#virsh net-start default
virsh net-edit, не вступят в силу в силу до тех пор, пока сеть не будет перезапущена, что приведет к потере всеми ВМ сетевого подключения к хосту до тех пор, пока их сетевые интерфейсы повторно не подключаться.
virsh net-update, которая требует немедленного применения изменений. Например, чтобы добавить запись статического хоста, можно использовать команду:
# virsh net-update default add ip-dhcp-host \
"<host mac='52:54:00:ba:f2:76' name='alt-server' ip='192.168.122.50' />" \
--live --config


 , расположенную в нижнем левом углу диалогового окна Сведения о подключении.
, расположенную в нижнем левом углу диалогового окна Сведения о подключении.

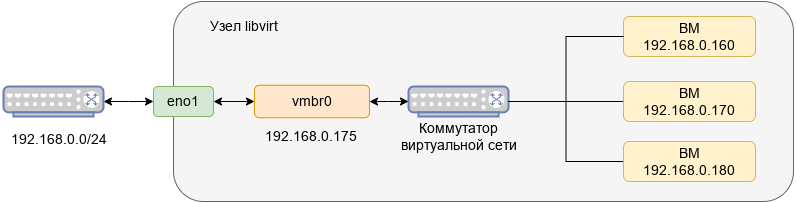
Примечание
# virt-install --network bridge=vmbr0 ...
# virsh edit alt-server
<interface type='network'>
<mac address='52:54:00:85:11:34'/>
<source network='default'/>
<model type='virtio'/>
<address type='pci' domain='0x0000' bus='0x01' slot='0x00' function='0x0'/>
</interface>
<interface type='bridge'>
<mac address='52:54:00:85:11:34'/>
<source bridge="vmbr0"/>
<model type='virtio'/>
<address type='pci' domain='0x0000' bus='0x01' slot='0x00' function='0x0'/>
</interface>
<interface type='bridge'>
<source bridge="vmbr0"/>
</interface>


# ip -4 route add 192.168.30.0/24 via 192.168.0.175
/tmp/routed_network.xml со следующим содержимым:
<network> <name>routed_network</name> <forward mode="route"/> <ip address="192.168.30.0" netmask="255.255.255.0"> <dhcp> <range start="192.168.30.128" end="192.168.30.254"/> </dhcp> </ip> </network>
/tmp/routed_network.xml:
#virsh net-define /tmp/routed_network.xmlСеть routed_network определена на основе /tmp/routed_network.xml #virsh net-autostart routed_networkДобавлена метка автоматического запуска сети routed_network #virsh net-start routed_networkСеть routed_network запущена
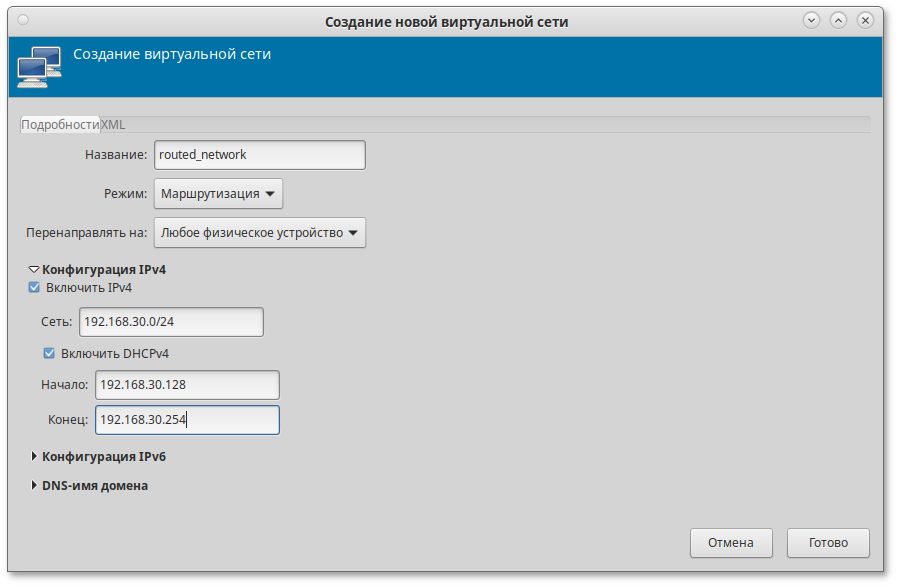
# virt-install --network network=routed_network ...
# virsh edit alt-server
<interface type='network'> <mac address='52:54:00:85:11:34'/> <source network='default'/> <model type='virtio'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x00' function='0x0'/> </interface>
<interface type='network'> <mac address='52:54:00:85:11:34'/> <source network='routed_network'/> <model type='virtio'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x00' function='0x0'/> </interface>
<interface type='network'> <source bridge="routed_network"/> </interface>

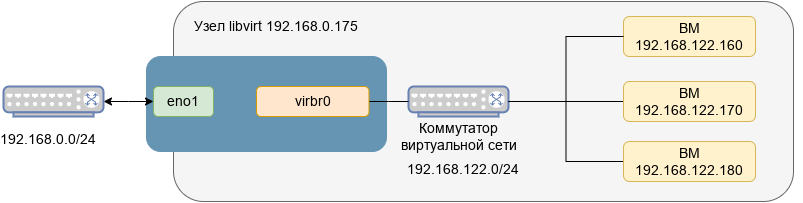
/tmp/nat_network.xml со следующим содержимым:
<network>
<name>nat_network</name>
<forward mode="nat"/>
<ip address="192.168.20.1" netmask="255.255.255.0">
<dhcp>
<range start="192.168.20.128" end="192.168.20.254"/>
</dhcp>
</ip>
</network>
/tmp/nat_network.xml:
#virsh net-define /tmp/nat_network.xml#virsh net-autostart nat_network#virsh net-start nat_network

# virt-install --network network=nat_network ...
# virsh edit alt-server
<interface type='network'>
<mac address='52:54:00:85:11:34'/>
<source network='default'/>
<model type='virtio'/>
<address type='pci' domain='0x0000' bus='0x01' slot='0x00' function='0x0'/>
</interface>
<interface type='network'>
<mac address='52:54:00:85:11:34'/>
<source network='nat_network'/>
<model type='virtio'/>
<address type='pci' domain='0x0000' bus='0x01' slot='0x00' function='0x0'/>
</interface>
<interface type='network'>
<source bridge="nat_network"/>
</interface>


/tmp/isolated_network.xml со следующим содержимым:
<network>
<name>isolated_network</name>
<ip address="192.168.100.1" netmask="255.255.255.0">
<dhcp>
<range start="192.168.100.128" end="192.168.100.254"/>
</dhcp>
</ip>
</network>
/tmp/isolated_network.xml:
#virsh net-define /tmp/isolated_network.xml#virsh net-autostart isolated_network#virsh net-start isolated_network

# virt-install --network network=isolated_network ...
# virsh edit alt-server
<interface type='network'>
<mac address='52:54:00:85:11:34'/>
<source network='default'/>
<model type='virtio'/>
<address type='pci' domain='0x0000' bus='0x01' slot='0x00' function='0x0'/>
</interface>
<interface type='network'>
<mac address='52:54:00:85:11:34'/>
<source network='isolated_network'/>
<model type='virtio'/>
<address type='pci' domain='0x0000' bus='0x01' slot='0x00' function='0x0'/>
</interface>
<interface type='network'>
<source bridge="isolated_network"/>
</interface>
/var/lib/libvirt/images на хосте виртуализации.
Таблица 64.1. Утилита командной строки virsh. Команды управления хранилищами
|
Команда
|
Описание
|
|---|---|
|
pool-define
|
Определить неактивный постоянный пул носителей на основе файла XML
|
|
pool-create
|
Создать пул из файла XML
|
|
pool-define-as
|
Определить пул на основе набора аргументов
|
|
pool-create-as
|
Создать пул на основе набора аргументов
|
|
pool-dumpxml
|
Вывести файл конфигурации XML для заданного пула
|
|
pool-list
|
Вывести список пулов
|
|
pool-build
|
Собрать пул
|
|
pool-start
|
Запустить ранее определённый неактивный пул
|
|
pool-autostart
|
Автозапуск пула
|
|
pool-destroy
|
Разрушить (остановить) пул
|
|
pool-delete
|
Удалить пул
|
|
pool-edit
|
Редактировать XML-конфигурацию пула носителей
|
|
pool-info
|
Просмотр информации о пуле носителей
|
|
pool-refresh
|
Обновить пул
|
|
pool-undefine
|
Удалить определение неактивного пула
|
virsh pool-define-as создаст файл конфигурации для постоянного пула хранения. Позже этот пул можно запустить командой virsh pool-start, настроить его на автоматический запуск при загрузке хоста, остановить командой virsh pool-destroy.
virsh pool-create-as создаст временный пул хранения (файл конфигурации не будет создан), который будет сразу запущен. Этот пул хранения будет удалён командой virsh pool-destory. Временный пул хранения нельзя запустить автоматически при загрузке. Преобразовать существующий временный пул в постоянный, можно создав файл XML-описания:
virsh pool-dumpxml имя_пула > имя_пула.xml && virsh pool-define имя_пула.xml
# virsh pool-create-as NFS-POOL netfs \
--source-host 192.168.0.105 \
--source-path /export/storage \
--target /var/lib/libvirt/images/NFS-POOL
Пул NFS-POOL создан
--source-host идентифицирует хост, который экспортирует каталог пула хранилищ посредством NFS. Аргумент опции --source-path определяет имя экспортируемого каталога на этом хосте. Аргумент опции --target идентифицирует локальную точку монтирования, которая будет использоваться для обращения к пулу хранилищ (этот каталог должен существовать).
Примечание
# systemctl enable --now nfs-client.target
virsh pool-list:
# virsh pool-list --all --details
Имя Состояние Автозапуск Постоянный Размер Распределение Доступно
-----------------------------------------------------------------------------------------
default работает yes yes 225,60 GiB 190,71 GiB 34,89 GiB
NFS-POOL работает yes yes 48,91 GiB 25,00 GiB 23,92 GiB
Автозапуск (Autostart) для пула хранилищ NFS-POOL имеет значение no (нет), т. е. после перезапуска системы этот пул не будет автоматически доступен для использования, и что опция Постоянный (Persistent) также имеет значение no, т. е. после перезапуска системы этот пул вообще не будет определен. Пул хранилищ является постоянным только в том случае, если он сопровождается XML-описанием пула хранилищ, которое находится в каталоге /etc/libvirt/storage. XML-файл описания пула имеет такое же имя, как у пула хранилищ, с которым он ассоциирован.
virsh pool-dumpxml, указав в качестве ее заключительного аргумента имя пула, для которого нужно получить XML-описание. Эта команда осуществляет запись в стандартный поток вывода, поэтому необходимо перенаправить выводимую ей информацию в соответствующий файл.
# virsh pool-dumpxml NFS-POOL > NFS-POOL.xml && virsh pool-define NFS-POOL.xml
Пул NFS-POOL определён на основе NFS-POOL.xml
Автозапуск (Autostart), можно воспользоваться командой virsh pool-autostart:
# virsh pool-autostart NFS-POOL
Добавлена метка автоматического запуска пула NFS-POOL
/etc/libvirt/storage/autostart будет содержать символьную ссылку на XML-описание этого пула хранилищ).
#virsh pool-define-as boot --type dir --target /var/lib/libvirt/bootПул boot определён #virsh pool-list --allИмя Состояние Автозапуск ------------------------------------- boot не активен no default активен yes NFS-POOL активен yes #virsh pool-build bootПул boot собран #virsh pool-start bootПул boot запущен #virsh pool-autostart bootДобавлена метка автоматического запуска пула boot #virsh pool-list --allИмя Состояние Автозапуск ------------------------------------- boot активен yes default активен yes NFS-POOL активен yes
# virsh pool-create-as --name iscsi_virtimages --type iscsi \
--source-host 192.168.0.146 \
--source-dev iqn.2023-05.alt.test:iscsi.target1 \
--target /dev/disk/by-path
Пул iscsi_virtimages создан
--source-host определяет имя хоста соответствующего сервера iSCSI, который экспортирует данный iSCSI LUN. Аргумент опции --source-dev определяет название iSCSI LUN. Аргумент опции --target идентифицирует локальную точку монтирования, которая будет использоваться для обращения к пулу хранилищ.
Примечание
# systemctl enable --now iscsid
 , расположенную в нижнем левом углу диалогового окна Сведения о подключении.
, расположенную в нижнем левом углу диалогового окна Сведения о подключении.


Примечание
--copy-storage-all). Но это приведет к большому трафику при копировании образа ВМ между серверами виртуализации и к заметному простою сервиса. Что бы миграция была по-настоящему «живой» с незаметным простоем необходимо использовать общее хранилище.
virsh. Для выполнения живой миграции нужно указать параметр --live. Команда переноса:
# virsh migrate --live VMName DestinationURL
где
virsh, необходимо выполнить следующие действия:
# virsh list
ID Имя Состояние
------------------------------
7 alt-server работает
# virsh migrate --live alt-server qemu+ssh://192.168.0.195/system
virsh будет сообщать только об ошибках. ВМ будет продолжать работу на исходном узле до завершения переноса;
# virsh list


virsh:
# virsh migrate --live --persistent --undefinesource \
alt-server qemu+ssh://192.168.0.195/system
Примечание
# virsh snapshot-create <domain> [--xmlfile <строка>] [--disk-only] [--live]...
# virsh snapshot-create-as <domain> [--name <строка>] [--disk-only] [--live]...
# virsh snapshot-create-as --domain alt-server --name alt-server-17mar2024
Снимок домена alt-server-17mar2024 создан
где
/var/lib/libvirt/qemu/snapshot/.
# virsh snapshot-create-as --domain alt-server --name 03apr2024 \
--diskspec vda,file=/var/lib/libvirt/images/alt-server.qcow2 --disk-only --atomic
Снимок домена 03apr2024 создан
# virsh snapshot-list --domain alt-server
Имя Время создания Состояние
-------------------------------------------------------------------
03apr2024 2024-04-03 18:14:39 +0200 disk-snapshot
alt-server-17mar2024 2024-03-17 18:06:29 +0200 running
# virsh snapshot-revert --domain alt-server --snapshotname 03apr2024 --running
# virsh snapshot-delete --domain alt-server --snapshotname 03apr2024
 , расположенную в нижнем левом углу окна управления снимками ВМ. В открывшемся окне следует указать название снимка и нажать кнопку :
, расположенную в нижнем левом углу окна управления снимками ВМ. В открывшемся окне следует указать название снимка и нажать кнопку :


/etc/libvirt/libvirtd.conf. Логи сохраняются в каталоге /var/log/libvirt.
x:name (log message only) x:+name (log message + stack trace)где
log_filtrers="3:remote 4:event"
log_outputs=”3:syslog:libvirtd 1:file:/tmp/libvirt.log”
/var/log/libvirt/qemu/. Например, для машины alt-server журнал будет находиться по адресу: /var/log/libvirt/qemu/alt-server.log.
/usr/share/polkit-1/actions/ имеются два файла с описанием возможных действий для работы с ВМ, предоставленные разработчиками libvirt:
org.libvirt.unix.policy описывает мониторинг ВМ и управление ими;
org.libvirt.api.policy перечислены конкретные действия (остановка, перезапуск и т. д.), которые возможны, если предыдущая проверка пройдена.
/usr/share/polkit-1/actions/org.libvirt.api.policy.
org.libvirt.api.$объект.$разрешение
search-storage-vols на объекте storage_pool отображено к действию polkit:
org.libvirt.api.storage-pool.search-storage-vols
/etc/libvirt/libvirtd.conf строку:
access_drivers = [ "polkit" ]
# systemctl restart libvirtd
/etc/polkit-1/rules.d/100-libvirt-acl.rules (имя произвольно) следующего вида:
polkit.addRule(function(action, subject) {
if (action.id == "org.libvirt.unix.manage" &&
subject.user == "test") {
return polkit.Result.YES;
}
});
polkit.addRule(function(action, subject) {
// разрешить пользователю test действия с доменом "alt-server"
if (action.id.indexOf("org.libvirt.api.domain.") == 0 &&
subject.user == "test")
{
if (action.lookup("domain_name") == 'alt-server')
{
return polkit.Result.YES;
}
else
{
return polkit.Result.NO;
}
}
else {
// разрешить пользователю test действия с
//подключениями, хранилищем и прочим
if (action.id.indexOf("org.libvirt.api.") == 0 &&
subject.user == "test")
{
polkit.log("org.libvirt.api.Yes");
return polkit.Result.YES;
}
else
{
return polkit.Result.NO;
}
}
})
$ virsh --connect qemu:///system list --all
ID Имя Состояние
------------------------------
4 alt-server работает
org.libvirt.api.domain.start:
polkit.addRule(function(action, subject)
{
// разрешить пользователю test только запускать ВМ в
// домене "alt-server"
if (action.id. == "org.libvirt.api.domain.start") &&
subject.user == "test")
{
if (action.lookup("domain_name") == 'alt-server')
{
return polkit.Result.YES;
}
else
{
return polkit.Result.NO;
}
}
});
if (action.id == "org.libvirt.api.domain.start")
{
if (subject.isInGroup("wheel"))
{
return polkit.Result.YES;
}
else
{
return polkit.Result.NO;
}
};
if (action.id == "org.libvirt.api.domain.stop")
{
if (subject.isInGroup("wheel"))
{
return polkit.Result.YES;
}
else
{
return polkit.Result.NO;
}
};
if (action.id.match("org.libvirt.api.domain.start"))
{
polkit.log("action=" + action);
polkit.log("subject=" + subject);
return polkit.Result.YES;
}
if (action.id.match("org.libvirt.api.domain.stop"))
{
polkit.log("action=" + action);
polkit.log("subject=" + subject);
return polkit.Result.YES;
}
kubectl — создание и настройка объектов в кластере;
kubelet — запуск контейнеров на узлах;
kubeadm — настройка компонентов, составляющих кластер.

Примечание
Примечание
Примечание
# swapoff -a
И удалить соответствующую строку в /etc/fstab.
# kubeadm init --pod-network-cidr=10.244.0.0/16
# kubeadm init --pod-network-cidr=192.168.0.0/16
…
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.0.103:6443 --token vr1hyp.anh6jecr9m1tskja \
--discovery-token-ca-cert-hash \
sha256:8914081137bae4e13c741066a6b4394b68f62ab915735c4c4c92fc14b02fa5a3
~/.kube (с правами пользователя):
$ mkdir ~/.kube
# cp /etc/kubernetes/admin.conf /home/<пользователь>/.kube/config
# chown <пользователь>: /home/<пользователь>/.kube/config
$ kubectl apply -f https://gitea.basealt.ru/alt/flannel-manifests/raw/branch/main/p10/latest/kube-flannel.yml
/etc/cni/net.d/:
# cd /etc/cni/net.d/
100-crio-bridge.conflist:
# cp 100-crio-bridge.conflist.sample 100-crio-bridge.conflist
$kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/refs/tags/v3.25.0/manifests/tigera-operator.yaml$kubectl apply -f https://raw.githubusercontent.com/projectcalico/calico/refs/tags/v3.25.0/manifests/custom-resources.yaml
$ kubectl get pods --namespace kube-system
NAME READY STATUS RESTARTS AGE
coredns-5dd5756b68-4t4tb 1/1 Running 0 10m
coredns-5dd5756b68-5cqjz 1/1 Running 0 10m
etcd-kube01 1/1 Running 0 10m
kube-apiserver-kube01 1/1 Running 0 10m
kube-controller-manager-kube01 1/1 Running 0 10m
kube-proxy-2ncd6 1/1 Running 0 10m
kube-scheduler-kube01 1/1 Running 0 10m
coredns должны находиться в состоянии Running. Количество kube-flannel и kube-proxy зависит от общего числа нод.
# kubeadm join <ip адрес>:<порт> --token <токен>
--discovery-token-ca-cert-hash sha256:<хеш> --ignore-preflight-errors=SystemVerification
Данная команда была выведена при выполнении команды kubeadm init на мастер-ноде.
# kubeadm join 192.168.0.103:6443 --token vr1hyp.anh6jecr9m1tskja \
--discovery-token-ca-cert-hash \
sha256:8914081137bae4e13c741066a6b4394b68f62ab915735c4c4c92fc14b02fa5a3
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
Примечание
$ kubeadm token list
TOKEN TTL EXPIRES USAGES
vr1hyp.anh6jecr9m1tskja 23h 2024-10-29T16:22:12Z authentication,signing
По умолчанию срок действия токена — 24 часа. Если требуется добавить новый узел в кластер по окончанию этого периода, можно создать новый токен:
$ kubeadm token create
--discovery-token-ca-cert-hash неизвестно, его можно получить, выполнив команду (на мастер-ноде):
$ openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | \
openssl rsa -pubin -outform der 2>/dev/null | \
openssl dgst -sha256 -hex | sed 's/^.* //'
8914081137bae4e13c741066a6b4394b68f62ab915735c4c4c92fc14b02fa5a3
<control-plane-host>:<control-plane-port>, адрес должен быть заключен в квадратные скобки:
[fd00::101]:2073
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
kube01 Ready control-plane,master 42m v1.28.14
kube02 Ready <none> 2m43s v1.28.14
kube03 Ready <none> 24s v1.28.14
или
$ kubectl get nodes -o wide
$ kubectl cluster-info
Kubernetes control plane is running at https://192.168.0.103:6443
CoreDNS is running at https://192.168.0.103:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
Посмотреть подробную информацию о ноде:
$ kubectl describe node kube03
$ kubectl apply -f https://k8s.io/examples/application/deployment.yaml
deployment.apps/nginx-deployment created
nginx-service.yaml, со следующим содержимым:
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
type: NodePort
ports:
- port: 80
targetPort: 80
selector:
app: nginx
Запустить новый сервис:
$ kubectl apply -f nginx-service.yaml
service/nginx created
$ kubectl get svc nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx NodePort 10.98.167.146 <none> 80:31868/TCP 17s
$ curl -I <ip адрес>:<порт>
где <ip адрес> — это IP-адрес любой из нод (не мастер-ноды), а <порт> — это порт сервиса, полученный с помощью предыдущей команды. В данном кластере возможна команда:
$ curl -I 192.168.0.102:31868
HTTP/1.1 200 OK
Server: nginx/1.14.2
kubeadm init и kubeadm join --control-plane.
Примечание
# kubeadm init --control-plane-endpoint 192.168.0.201:6443 --upload-certs --pod-network-cidr=10.244.0.0/16
где
--control-plane-endpoint — указывает адрес и порт балансировщика нагрузки;
--upload-certs — используется для загрузки в кластер сертификатов, которые должны быть общими для всех управляющих узлов;
--pod-network-cidr=10.244.0.0/16 — адрес внутренней (разворачиваемой Kubernetes) сети, рекомендуется оставить данное значение для правильной работы Flannel.
… Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of the control-plane node running the following command on each as root: kubeadm join 192.168.0.201:6443 --token cvvui8.lz82ufip6cz89ar9 \ --discovery-token-ca-cert-hash sha256:3ee0c550746a4a8e0abb6b59311f0fc301cdfeec00af8b26ed4598116c4d8184 \ --control-plane --certificate-key e0cbf1dc4e282bf517e23887dace30b411cd739b1aab037b056f0c23e5b0a222 Please note that the certificate-key gives access to cluster sensitive data, keep it secret! As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use "kubeadm init phase upload-certs --upload-certs" to reload certs afterward. Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.0.201:6443 --token cvvui8.lz82ufip6cz89ar9 \ --discovery-token-ca-cert-hash sha256:3ee0c550746a4a8e0abb6b59311f0fc301cdfeec00af8b26ed4598116c4d8184
~/.kube (с правами пользователя):
$ mkdir ~/.kube
# cp /etc/kubernetes/admin.conf /home/<пользователь>/.kube/config
# chown <пользователь>: /home/<пользователь>/.kube/config
$ kubectl apply -f https://gitea.basealt.ru/alt/flannel-manifests/raw/branch/main/p10/latest/kube-flannel.yml
$ kubectl get pod -n kube-system -w
NAME READY STATUS RESTARTS AGE
coredns-78fcd69978-c5swn 1/1 Running 0 11m
coredns-78fcd69978-zdbp8 1/1 Running 0 11m
etcd-master01 1/1 Running 0 11m
kube-apiserver-master01 1/1 Running 0 11m
kube-controller-manager-master01 1/1 Running 0 11m
kube-flannel-ds-qfzbw 1/1 Running 0 116s
kube-proxy-r6kj9 1/1 Running 0 11m
kube-scheduler-master01 1/1 Running 0 11m
kubeadm init на первом управляющем узле):
# kubeadm join 192.168.0.201:6443 --token cvvui8.lz82ufip6cz89ar9 \
--discovery-token-ca-cert-hash sha256:3ee0c550746a4a8e0abb6b59311f0fc301cdfeec00af8b26ed4598116c4d8184 \
--control-plane --certificate-key e0cbf1dc4e282bf517e23887dace30b411cd739b1aab037b056f0c23e5b0a222
kubeadm init на первом управляющем узле):
# kubeadm join 192.168.0.201:6443 --token cvvui8.lz82ufip6cz89ar9 \
--discovery-token-ca-cert-hash sha256:3ee0c550746a4a8e0abb6b59311f0fc301cdfeec00af8b26ed4598116c4d8184
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
kube01 Ready <none> 23m v1.28.14
kube02 Ready <none> 15m v1.28.14
kube03 Ready <none> 2m30s v1.28.14
master01 Ready control-plane,master 82m v1.28.14
master02 Ready control-plane,master 66m v1.28.14
master03 Ready control-plane,master 39m v1.28.14
Примечание
#cat<< EOF > /etc/systemd/system/kubelet.service.d/kubelet.conf # Replace "systemd" with the cgroup driver of your container runtime. The default value in the kubelet is "cgroupfs". # Replace the value of "containerRuntimeEndpoint" for a different container runtime if needed. # apiVersion: kubelet.config.k8s.io/v1beta1 kind: KubeletConfiguration authentication: anonymous: enabled: false webhook: enabled: false authorization: mode: AlwaysAllow cgroupDriver: systemd address: 127.0.0.1 containerRuntimeEndpoint: unix:///var/run/crio/crio.sock staticPodPath: /etc/kubernetes/manifests EOF #cat<< EOF > /etc/systemd/system/kubelet.service.d/20-etcd-service-manager.conf [Service] ExecStart= ExecStart=/usr/bin/kubelet --config=/etc/systemd/system/kubelet.service.d/kubelet.conf Restart=always EOF #systemctl daemon-reload#systemctl restart kubelet
# systemctl status kubelet
#!/bin/sh
# HOST0, HOST1, и HOST2 - IP-адреса узлов
export HOST0=192.168.0.205
export HOST1=192.168.0.206
export HOST2=192.168.0.207
# NAME0, NAME1 и NAME2 - имена узлов
export NAME0="etc01"
export NAME1="etc02"
export NAME2="etc03"
# Создать временные каталоги
mkdir -p /tmp/${HOST0}/ /tmp/${HOST1}/ /tmp/${HOST2}/
HOSTS=(${HOST0} ${HOST1} ${HOST2})
NAMES=(${NAME0} ${NAME1} ${NAME2})
for i in "${!HOSTS[@]}"; do
HOST=${HOSTS[$i]}
NAME=${NAMES[$i]}
cat << EOF > /tmp/${HOST}/kubeadmcfg.yaml
---
apiVersion: "kubeadm.k8s.io/v1beta3"
kind: InitConfiguration
nodeRegistration:
name: ${NAME}
localAPIEndpoint:
advertiseAddress: ${HOST}
---
apiVersion: "kubeadm.k8s.io/v1beta3"
kind: ClusterConfiguration
etcd:
local:
serverCertSANs:
- "${HOST}"
peerCertSANs:
- "${HOST}"
extraArgs:
initial-cluster: ${NAMES[0]}=https://${HOSTS[0]}:2380,${NAMES[1]}=https://${HOSTS[1]}:2380,${NAMES[2]}=https://${HOSTS[2]}:2380
initial-cluster-state: new
name: ${NAME}
listen-peer-urls: https://${HOST}:2380
listen-client-urls: https://${HOST}:2379
advertise-client-urls: https://${HOST}:2379
initial-advertise-peer-urls: https://${HOST}:2380
EOF
done
Примечание
/etc/kubernetes/pki/etcd/ca.crt и /etc/kubernetes/pki/etcd/ca.key. После этого можно перейти к следующему шагу.
# kubeadm init phase certs etcd-ca
[certs] Generating "etcd/ca" certificate and key
Эта команда создаст два файла: /etc/kubernetes/pki/etcd/ca.crt и /etc/kubernetes/pki/etcd/ca.key.
#!/bin/sh
# HOST0, HOST1, и HOST2 - IP-адреса узлов
export HOST0=192.168.0.205
export HOST1=192.168.0.206
export HOST2=192.168.0.207
kubeadm init phase certs etcd-server --config=/tmp/${HOST2}/kubeadmcfg.yaml
kubeadm init phase certs etcd-peer --config=/tmp/${HOST2}/kubeadmcfg.yaml
kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST2}/kubeadmcfg.yaml
kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST2}/kubeadmcfg.yaml
cp -R /etc/kubernetes/pki /tmp/${HOST2}/
# cleanup non-reusable certificates
find /etc/kubernetes/pki -not -name ca.crt -not -name ca.key -type f -delete
kubeadm init phase certs etcd-server --config=/tmp/${HOST1}/kubeadmcfg.yaml
kubeadm init phase certs etcd-peer --config=/tmp/${HOST1}/kubeadmcfg.yaml
kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST1}/kubeadmcfg.yaml
kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST1}/kubeadmcfg.yaml
cp -R /etc/kubernetes/pki /tmp/${HOST1}/
find /etc/kubernetes/pki -not -name ca.crt -not -name ca.key -type f -delete
kubeadm init phase certs etcd-server --config=/tmp/${HOST0}/kubeadmcfg.yaml
kubeadm init phase certs etcd-peer --config=/tmp/${HOST0}/kubeadmcfg.yaml
kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST0}/kubeadmcfg.yaml
kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST0}/kubeadmcfg.yaml
# No need to move the certs because they are for HOST0
# clean up certs that should not be copied off this host
find /tmp/${HOST2} -name ca.key -type f -delete
find /tmp/${HOST1} -name ca.key -type f -delete
HOST1=192.168.0.206 HOST2=192.168.0.207 USER=user #scp -r /tmp/${HOST1}/* ${USER}@${HOST1}:#ssh ${USER}@${HOST1}$su -#chown -R root:root /home/user/pki#mv /home/user/pki /etc/kubernetes/#exit$exit#scp -r /tmp/${HOST2}/* ${USER}@${HOST2}:#ssh ${USER}@${HOST2}$su -#chown -R root:root /home/user/pki#mv /home/user/pki /etc/kubernetes/#exit$exit
/tmp/${HOST0}
└── kubeadmcfg.yaml
---
/etc/kubernetes/pki
├── apiserver-etcd-client.crt
├── apiserver-etcd-client.key
└── etcd
├── ca.crt
├── ca.key
├── healthcheck-client.crt
├── healthcheck-client.key
├── peer.crt
├── peer.key
├── server.crt
└── server.key
$HOME
└── kubeadmcfg.yaml
---
/etc/kubernetes/pki
├── apiserver-etcd-client.crt
├── apiserver-etcd-client.key
└── etcd
├── ca.crt
├── healthcheck-client.crt
├── healthcheck-client.key
├── peer.crt
├── peer.key
├── server.crt
└── server.key
$HOME
└── kubeadmcfg.yaml
---
/etc/kubernetes/pki
├── apiserver-etcd-client.crt
├── apiserver-etcd-client.key
└── etcd
├── ca.crt
├── healthcheck-client.crt
├── healthcheck-client.key
├── peer.crt
├── peer.key
├── server.crt
└── server.key
# kubeadm init phase etcd local --config=/tmp/192.168.0.205/kubeadmcfg.yaml
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests
# kubeadm init phase etcd local --config=/home/user/kubeadmcfg.yaml
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
export CONTROL_PLANE="user@192.168.0.201" #scp /etc/kubernetes/pki/etcd/ca.crt "${CONTROL_PLANE}":#scp /etc/kubernetes/pki/apiserver-etcd-client.crt "${CONTROL_PLANE}":#scp /etc/kubernetes/pki/apiserver-etcd-client.key "${CONTROL_PLANE}":
kubeadm-config.yaml:
---
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
kubernetesVersion: stable
networking:
podSubnet: "10.244.0.0/16"
controlPlaneEndpoint: "192.168.0.201:6443" # IP-адрес, порт балансировщика нагрузки
etcd:
external:
endpoints:
- https://192.168.0.205:2379 # IP-адрес ETCD01
- https://192.168.0.206:2379 # IP-адрес ETCD02
- https://192.168.0.207:2379 # IP-адрес ETCD03
caFile: /etc/kubernetes/pki/etcd/ca.crt
certFile: /etc/kubernetes/pki/apiserver-etcd-client.crt
keyFile: /etc/kubernetes/pki/apiserver-etcd-client.key
#mkdir -p /etc/kubernetes/pki/etcd/#cp /home/user/ca.crt /etc/kubernetes/pki/etcd/#cp /home/user/apiserver-etcd-client.* /etc/kubernetes/pki/
# kubeadm init --config kubeadm-config.yaml --upload-certs
…
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of the control-plane node running the following command on each as root:
kubeadm join 192.168.0.201:6443 --token 7onha1.afzqd41s8dzr1wj1 \
--discovery-token-ca-cert-hash sha256:ec2be69db54b2ae13c175765ddd058801fd70054508c0e118020896a1d4c9ec3 \
--control-plane --certificate-key eb1fabf70e994c061f749f13c0f26baef64764e813d5f0eaa7b09d5279a492c4
Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use
"kubeadm init phase upload-certs --upload-certs" to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.0.201:6443 --token 7onha1.afzqd41s8dzr1wj1 \
--discovery-token-ca-cert-hash sha256:ec2be69db54b2ae13c175765ddd058801fd70054508c0e118020896a1d4c9ec3
Следует сохранить этот вывод, т.к. этот токен будет использоваться для присоединения к кластеру остальных управляющих и вычислительных узлов.
~/.kube (с правами пользователя):
$ mkdir ~/.kube
# cp /etc/kubernetes/admin.conf /home/<пользователь>/.kube/config
# chown <пользователь>: /home/<пользователь>/.kube/config
$ kubectl apply -f https://gitea.basealt.ru/alt/flannel-manifests/raw/branch/main/p10/latest/kube-flannel.yml
$ kubectl get pod -n kube-system -w
kubeadm init на первом управляющем узле):
# kubeadm join 192.168.0.201:6443 --token 7onha1.afzqd41s8dzr1wj1 \
--discovery-token-ca-cert-hash sha256:ec2be69db54b2ae13c175765ddd058801fd70054508c0e118020896a1d4c9ec3 \
--control-plane --certificate-key eb1fabf70e994c061f749f13c0f26baef64764e813d5f0eaa7b09d5279a492c4
kubeadm init на первом управляющем узле):
# kubeadm join 192.168.0.201:6443 --token 7onha1.afzqd41s8dzr1wj1 \
--discovery-token-ca-cert-hash sha256:ec2be69db54b2ae13c175765ddd058801fd70054508c0e118020896a1d4c9ec3
$ kubectl get nodes
Содержание
#systemctl enable --now ahttpd#systemctl enable --now alteratord
https://ip-адрес:8080/.
192.168.0.122, то интерфейс управления будет доступен по адресу: https://192.168.0.122:8080/.
Примечание
$ipaddr
inet:
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP qlen 1000
link/ether 60:eb:69:6c:ef:47 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.122/24 brd 192.168.0.255 scope global enp0s3
192.168.0.122.


Предупреждение
Примечание
Важно



/etc/net/ifaces/<интерфейс>. Настройки сети могут изменяться либо в ЦУС в данном модуле, либо напрямую через редактирование файлов /etc/net/ifaces/<интерфейс>.
/etc/net/ifaces/<интерфейс>.
/etc/NetworkManager/system-connections. Этот режим особенно актуален для задач настройки сети на клиенте, когда IP-адрес необходимо получать динамически с помощью DHCP, а DNS-сервер указать явно. Через ЦУС так настроить невозможно, так как при включении DHCP отключаются настройки, которые можно задавать вручную.
/etc/systemd/network/<имя_файла>.network, /etc/systemd/network/<имя_файла>.netdev, /etc/systemd/network/<имя_файла>.link. Данный режим доступен, если установлен пакет systemd-networkd.



/proc/net/bonding/bond0.
Предупреждение

Примечание

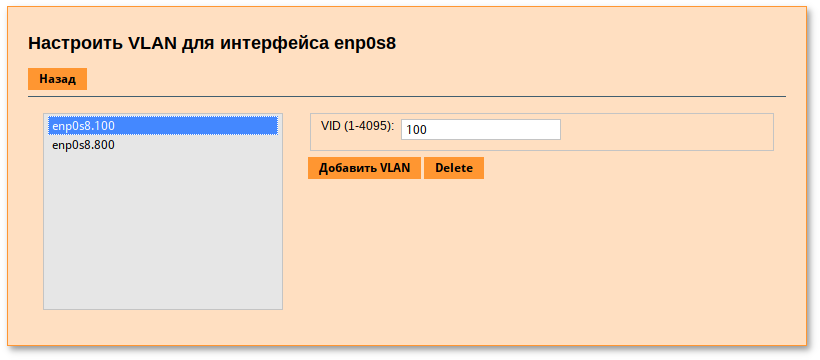

Примечание
Примечание





/root).




Примечание

usrquota, grpquota. Для этого следует выбрать нужный раздел в списке Файловая система и установить отметку в поле Включено:


Примечание
# apt-get install state-change-notify-postfix

Fri Mar 29 16:55:31 EET 2024: The host-15.test.alt is about to start.При выключении:
Fri Mar 29 16:55:02 EET 2024: The host-15.test.alt is about to shutdown.
rpm -qa | grep alterator*
Прочие пакеты для ЦУС можно найти, выполнив команду:
apt-cache search alterator*
#apt-get install alterator-net-openvpn#apt-get remove alterator-net-openvpn


Содержание
Примечание
apt-get. Она автоматически определяет зависимости между пакетами и строго следит за её соблюдением при выполнении любой из следующих операций: установка, удаление или обновление пакетов.
Важно
/etc/apt/sources.list, либо в любой файл .list (например, mysources.list) в каталоге /etc/apt/sources.list.d/. Описания репозиториев заносятся в эти файлы в следующем виде:
rpm [подпись] метод:путь база название rpm-src [подпись] метод:путь база названиеЗдесь:
/etc/apt/vendor.list;
/etc/apt/sources.list.d/*.list обычно указывается интернет-репозиторий, совместимый с установленным дистрибутивом.
sources.list, необходимо обновить локальную базу данных APT о доступных пакетах. Это делается командой apt-get update.
sources.list присутствует репозиторий, содержимое которого может изменяться (например, постоянно разрабатываемый репозиторий или репозиторий обновлений по безопасности), то прежде чем работать с APT, необходимо синхронизировать локальную базу данных с удалённым сервером командой apt-get update. Локальная база данных создаётся заново при каждом изменении в репозитории: добавлении, удалении или переименовании пакета.
/etc/apt/sources.list, относящиеся к ресурсам в сети Интернет.
apt-repo:
apt-repo
apt-repo add репозиторий
apt-repo rm репозиторий
apt-repo update
apt-repo:
man apt-repo
или
apt-repo --help
Примечание
#Или то же самое одной командой:apt-repo#rm allapt-repoadd p10
# apt-repo set p10
sources.list репозитория на сменном диске в APT предусмотрена специальная утилита — apt-cdrom.
Acquire::CDROM::mount в файле конфигурации APT (/etc/apt/apt.conf), по умолчанию это /media/ALTLinux:
# mkdir /media/ALTLinux
# mount /dev/носитель /media/ALTLinux
где /dev/носитель — соответствующее блочное устройство (например, /dev/dvd — для CD/DVD-диска).
# apt-cdrom -m add
sources.list появится запись о подключённом носителе:
rpm cdrom:[ALT Server-V 10.4 x86_64 build 2024-10-28]/ ALTLinux main
/etc/apt/sources.list.d/.
Примечание
alt.list может содержаться такая информация:
# ftp.altlinux.org (ALT Linux, Moscow) # ALT Platform 10 #rpm [p10] ftp://ftp.altlinux.org/pub/distributions/ALTLinux p10/branch/x86_64 classic #rpm [p10] ftp://ftp.altlinux.org/pub/distributions/ALTLinux p10/branch/x86_64-i586 classic #rpm [p10] ftp://ftp.altlinux.org/pub/distributions/ALTLinux p10/branch/noarch classic rpm [p10] http://ftp.altlinux.org/pub/distributions/ALTLinux p10/branch/x86_64 classic rpm [p10] http://ftp.altlinux.org/pub/distributions/ALTLinux p10/branch/x86_64-i586 classic rpm [p10] http://ftp.altlinux.org/pub/distributions/ALTLinux p10/branch/noarch classic
apt-get update или apt-repo update).
apt-cache. Данная утилита позволяет искать пакет не только по имени, но и по его описанию.
apt-cache search подстрока позволяет найти все пакеты, в именах или описании которых присутствует указанная подстрока. Например:
$ apt-cache search telegraf
ceph-mgr-telegraf - Telegraf module for Ceph Manager Daemon
telegraf - The plugin-driven server agent for collecting and reporting metrics
apt-cache show:
$ apt-cache show telegraf
Package: telegraf
Section: Development/Other
Installed Size: 154119764
Maintainer: Alexey Shabalin (ALT Team) <shaba@altlinux.org>
Version: 1.24.2-alt1:p10+326352.200.3.1@1691242931
Pre-Depends: /bin/sh, /usr/sbin/groupadd, /usr/sbin/useradd, /usr/sbin/usermod, /usr/sbin/post_service, /usr/sbin/preun_service, rpmlib(PayloadIsXz)
Depends: /bin/kill, /bin/sh, /etc/logrotate.d, /etc/rc.d/init.d, /etc/rc.d/init.d(SourceIfNotEmpty), /etc/rc.d/init.d(msg_reloading), /etc/rc.d/init.d(msg_usage), /etc/rc.d/init.d(start_daemon), /etc/rc.d/init.d(status), /etc/rc.d/init.d(stop_daemon), /etc/rc.d/init.d/functions
Provides: telegraf (= 1.24.2-alt1:p10+326352.200.3.1)
Architecture: x86_64
Size: 29082799
MD5Sum: d9daf730a225fb47b2901735aa01ed17
Filename: telegraf-1.24.2-alt1.x86_64.rpm
Description: The plugin-driven server agent for collecting and reporting metrics
Telegraf is an agent written in Go for collecting, processing, aggregating, and writing metrics.
Design goals are to have a minimal memory footprint with a plugin system so that developers
in the community can easily add support for collecting metrics from well known services
(like Hadoop, Postgres, or Redis) and third party APIs (like Mailchimp, AWS CloudWatch,
or Google Analytics).
apt-cache можно использовать русскую подстроку. В этом случае будут найдены пакеты, имеющие описание на русском языке. К сожалению, описание на русском языке в настоящее время есть не у всех пакетов, но наиболее актуальные описания переведены.
Важно
apt-get install имя_пакета.
Важно
# apt-get update
apt-get позволяет устанавливать в систему пакеты, требующие для работы наличие других, пока ещё не установленных пакетов. В этом случае он определяет, какие пакеты необходимо установить. apt-get устанавливает их, пользуясь всеми доступными репозиториями.
apt-get install telegraf приведёт к следующему диалогу с APT:
# apt-get install telegraf
Чтение списков пакетов... Завершено
Построение дерева зависимостей... Завершено
Следующие НОВЫЕ пакеты будут установлены:
telegraf
0 будет обновлено, 1 новых установлено, 0 пакетов будет удалено и 0 не будет обновлено.
Необходимо получить 29,1MB архивов.
После распаковки потребуется дополнительно 154MB дискового пространства.
Получено: 1 http://ftp.altlinux.org p10/branch/x86_64/classic telegraf 1.24.2-alt1:p10+326352.200.3.1@1691242931 [29,1MB]
Получено 29,1MB за 2s (11,0MB/s).
Совершаем изменения...
Подготовка... ################################# [100%]
Обновление / установка...
1: telegraf-1.24.2-alt1 ################################# [100%]
Завершено.
apt-get install имя_пакета используется также и для обновления уже установленного пакета или группы пакетов. В этом случае apt-get дополнительно проверяет, есть ли обновлённая, в сравнении с установленной в системе, версия пакета в репозитории.
# apt-get install /путь/к/файлу.rpm
При этом APT проведёт стандартную процедуру проверки зависимостей и конфликтов с уже установленными пакетами.
apt-get отказывается выполнять операции установки, удаления или обновления. В этом случае необходимо повторить операцию, задав опцию -f, заставляющую apt-get исправить нарушенные зависимости, удалить или заменить конфликтующие пакеты. В этом случае необходимо внимательно следить за сообщениями, выводимыми apt-get. Любые действия в этом режиме обязательно требуют подтверждения со стороны пользователя.
apt-get remove имя_пакета. Для того чтобы не нарушать целостность системы, будут удалены и все пакеты, зависящие от удаляемого. В случае удаления пакета, который относится к базовым компонентам системы, apt-get потребует дополнительное подтверждение с целью предотвращения возможной случайной ошибки.
Важно
apt-get удалить базовый компонент системы, вы увидите следующий запрос на подтверждение операции:
# apt-get remove filesystem
Чтение списков пакетов... Завершено
Построение дерева зависимостей... Завершено
Следующие пакеты будут УДАЛЕНЫ:
...
ВНИМАНИЕ: Будут удалены важные для работы системы пакеты
Обычно этого делать не следует. Вы должны точно понимать возможные последствия!
...
0 будет обновлено, 0 новых установлено, 2648 пакетов будет удалено и 0 не будет обновлено.
Необходимо получить 0B архивов.
После распаковки будет освобождено 8994MB дискового пространства.
Вы делаете нечто потенциально опасное!
Введите фразу 'Yes, do as I say!' чтобы продолжить.
Предупреждение
#apt-get&&updateapt-getdist-upgrade
apt-get update) обновит индексы пакетов. Вторая команда (apt-get dist-upgrade) позволяет обновить только те установленные пакеты, для которых в репозиториях, перечисленных в /etc/apt/sources.list, имеются новые версии.
Примечание
apt-get upgrade существует, использовать её следует осторожно, либо не использовать вовсе.
/etc/apt/sources.list, имеются новые версии.
apt-get upgrade, в результате чего происходит нарушение целостности системы: появляются неудовлетворённые зависимости. Для разрешения этой проблемы существует режим обновления в масштабе дистрибутива — apt-get dist-upgrade.
apt-get, которым APT предварит само обновление.
Примечание
apt-get dist-upgrade обновит систему, но ядро ОС не будет обновлено.
# update-kernel
Примечание
update-kernel необходимо выполнить команду apt-get update.
update-kernel обновляет и модули ядра, если в репозитории обновилось что-то из модулей без обновления ядра.
# remove-old-kernels
Содержание
/.
/media/cdrom (путь в дистрибутиве обозначается с использованием /, а не \, как в DOS/Windows).
/:
/bin — командные оболочки (shell), основные утилиты;
/boot — содержит ядро системы;
/dev — псевдофайлы устройств, позволяющие работать с устройствами напрямую. Файлы в /dev создаются сервисом udev
/etc — общесистемные конфигурационные файлы для большинства программ в системе;
/etc/rc?.d, /etc/init.d, /etc/rc.boot, /etc/rc.d — каталоги, где расположены командные файлы, выполняемые при запуске системы или при смене её режима работы;
/etc/passwd — база данных пользователей, в которой содержится информация об имени пользователя, его настоящем имени, личном каталоге, его зашифрованный пароль и другие данные;
/etc/shadow — теневая база данных пользователей. При этом информация из файла /etc/passwd перемещается в /etc/shadow, который недоступен для чтения всем, кроме пользователя root. В случае использования альтернативной схемы управления теневыми паролями (TCB), все теневые пароли для каждого пользователя располагаются в каталоге /etc/tcb/имя пользователя/shadow;
/home — домашние каталоги пользователей;
/lib — содержит файлы динамических библиотек, необходимых для работы большей части приложений, и подгружаемые модули ядра;
/lost+found — восстановленные файлы;
/media — подключаемые носители (каталоги для монтирования файловых систем сменных устройств);
/mnt — точки временного монтирования;
/opt — вспомогательные пакеты;
/proc — виртуальная файловая система, хранящаяся в памяти компьютера при загруженной ОС. В данном каталоге расположены самые свежие сведения обо всех процессах, запущенных на компьютере.
/root — домашний каталог администратора системы;
/run — файлы состояния приложений;
/sbin — набор программ для административной работы с системой (системные утилиты);
/selinux — виртуальная файловая система SELinux;
/srv — виртуальные данные сервисных служб;
/sys — файловая система, содержащая информацию о текущем состоянии системы;
/tmp — временные файлы.
/usr — пользовательские двоичные файлы и данные, используемые только для чтения (программы и библиотеки);
/var — файлы для хранения изменяющихся данных (рабочие файлы программ, очереди, журналы).
/usr:
/usr/bin — дополнительные программы для всех учетных записей;
/usr/sbin — команды, используемые при администрировании системы и не предназначенные для размещения в файловой системе root;
/usr/local — место, где рекомендуется размещать файлы, установленные без использования пакетных менеджеров, внутренняя организация каталогов практически такая же, как и корневого каталога;
/usr/man — каталог, где хранятся файлы справочного руководства man;
/usr/share — каталог для размещения общедоступных файлов большей части приложений.
/var:
/var/log — место, где хранятся файлы аудита работы системы и приложений;
/var/spool — каталог для хранения файлов, находящихся в очереди на обработку для того или иного процесса (очереди печати, непрочитанные или не отправленные письма, задачи cron т.д.).
/dev файловой системы дистрибутива (об этом — ниже). Диски (в том числе IDE/SATA/SCSI/SAS жёсткие диски, USB-диски) имеют имена:
/dev/sda — первый диск;
/dev/sdb — второй диск;
/dev/sdX, где X — a, b, c, d, e, … в зависимости от порядкового номера диска на шине.
/dev/sdb4 — четвертый раздел второго диска.
/) и раздел подкачки (swap). Размер последнего, как правило, составляет от однократной до двукратной величины оперативной памяти компьютера. Если на диске много свободного места, то можно создать отдельные разделы для каталогов /usr, /home, /var.
command.com в DOS, но несравненно мощнее. При помощи командных интерпретаторов можно писать небольшие программы — сценарии (скрипты). В Linux доступны следующие командные оболочки:
bash — самая распространенная оболочка под linux. Она ведет историю команд и предоставляет возможность их редактирования;
pdksh — клон korn shell, хорошо известной оболочки в UNIX™ системах.
$ echo $SHELL
history. Команды, присутствующие в истории, отображаются в списке пронумерованными. Чтобы запустить конкретную команду необходимо набрать:
!номер команды
!!запустится последняя из набранных команд.
gunzip, можно набрать следующую команду:
gu
$guguilegunzipgupnp-binding-tool
gunzip — это единственное имя, третьей буквой которого является «n»), а затем нажать клавишу Tab, то оболочка самостоятельно дополнит имя. Чтобы запустить команду нужно нажать Enter.
$PATH. По умолчанию в этот перечень каталогов не входит текущий каталог, обозначаемый ./ (точка слеш) (если только не выбран один из двух самых слабых уровней защиты). Поэтому, для запуска программы из текущего каталога, необходимо использовать команду (в примере запускается команда prog):
./progcal, выводящая календарь на текущий месяц.
$calСентябрь 2023 Пн Вт Ср Чт Пт Сб Вс 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
Команда$cal1 2024Январь 2024 Пн Вт Ср Чт Пт Сб Вс 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
cal 1 2024 состоит из двух частей — собственно команды cal и «остального». То, что следует за командой называется параметрами (или аргументами) и они вводятся для изменения поведения команды. В большинстве случаев, первое слово считается именем команды, а остальные — её параметрами.
date, только для работы по Гринвичу ей нужен дополнительный параметр -u (он же --universal).
$dateСр 27 сен 2023 18:58:50 EET$date-uСр 27 сен 2023 16:59:09 UTC
--help. К примеру, получить подсказку о том, что делает команда rm, можно, набрав в терминале rm --help.
man. Пример:
$manls
Примечание
ls -l -F можно ввести команду ls -lF
Учетные записи пользователей
susu позволяет изменить «владельца» текущего сеанса (сессии) без необходимости завершать сеанс и открывать новый.
su [ОПЦИИ...] [ПОЛЬЗОВАТЕЛЬ]su - будет запрошен пароль суперпользователя (root), и, в случае ввода корректного пароля, пользователь получит права администратора. Чтобы вернуться к правам пользователя, необходимо ввести команду:
exitidid выводит информацию о пользователе и группах, в которых он состоит, для заданного пользователя или о текущем пользователе (если ничего не указано).
id [ОПЦИИ...] [ПОЛЬЗОВАТЕЛЬ]passwdpasswd меняет (или устанавливает) пароль, связанный с входным_именем пользователя.
Основные операции с файлами и каталогами
lsls (list) печатает в стандартный вывод содержимое каталогов.
ls [ОПЦИИ...] [ФАЙЛ...]-a — просмотр всех файлов, включая скрытые;
-l — отображение более подробной информации;
-R — выводить рекурсивно информацию о подкаталогах.
cdcd предназначена для смены каталога. Команда работает как с абсолютными, так и с относительными путями. Если каталог не указан, используется значение переменной окружения $HOME (домашний каталог пользователя). Если каталог задан полным маршрутным именем, он становится текущим. По отношению к новому каталогу нужно иметь право на выполнение, которое в данном случае трактуется как разрешение на поиск.
cd [-L|-P] [КАТАЛОГ]$OLDPWD. Если переход был осуществлен по переменной окружения $CDPATH или в качестве аргумента был задан «-» и смена каталога была успешной, то абсолютный путь нового рабочего каталога будет выведен на стандартный вывод.
docs/ (относительный путь):
cd docs//usr/bin (абсолютный путь):
cd /usr/bin/cd ..cd -cdpwdpwd выводит абсолютный путь текущего (рабочего) каталога.
pwd [-L|-P]-P — не выводить символические ссылки;
-L — выводить символические ссылки.
rmrm служит для удаления записей о файлах. Если заданное имя было последней ссылкой на файл, то файл уничтожается.
Предупреждение
rm[ОПЦИИ...]<ФАЙЛ>
-f — никогда не запрашивать подтверждения;
-i — всегда запрашивать подтверждение;
-r, -R — рекурсивно удалять содержимое указанных каталогов.
html в каталоге ~/html:
rm-i~/html/*.html
mkdirmkdir — команда для создания новых каталогов.
mkdir [-p] [-m права] <КАТАЛОГ...>rmdirrmdir удаляет каталоги из файловой системы. Каталог должен быть пуст перед удалением.
rmdir [ОПЦИИ...] <КАТАЛОГ...>-p — удалить каталог и его потомки.
rmdir часто заменяется командой rm -rf, которая позволяет удалять каталоги, даже если они не пусты.
cpcp предназначена для копирования файлов из одного в другие каталоги.
cp [-fip] [ИСХ_ФАЙЛ...] [ЦЕЛ_ФАЙЛ...]cp [-fip] [ИСХ_ФАЙЛ...] [КАТАЛОГ]cp [-R] [[-H] | [-L] | [-P]] [-fip] [ИСХ_ФАЙЛ...] [КАТАЛОГ]-p — сохранять по возможности времена изменения и доступа к файлу, владельца и группу, права доступа;
-i — запрашивать подтверждение перед копированием в существующие файлы;
-r, -R — рекурсивно копировать содержимое каталогов.
mvmv предназначена для перемещения файлов.
mv [-fi] [ИСХ_ФАЙЛ...] [ЦЕЛ_ФАЙЛ...]mv [-fi] [ИСХ_ФАЙЛ...] [КАТАЛОГ]mv перемещает исх_файл в цел_файл (происходит переименование файла).
mv перемещает исходные файлы в указанный каталог под именами, совпадающими с краткими именами исходных файлов.
-f — не запрашивать подтверждения перезаписи существующих файлов;
-i — запрашивать подтверждение перезаписи существующих файлов.
catcat последовательно выводит содержимое файлов.
cat [ОПЦИИ...] [ФАЙЛ...]-n, --number — нумеровать все строки при выводе;
-E, --show-ends — показывать $ в конце каждой строки.
headhead выводит первые 10 строк каждого файла на стандартный вывод.
head [ОПЦИИ] [ФАЙЛ...]-n, --lines=[-]K — вывести первые К строк каждого файла, а не первые 10;
-q, --quiet — не печатать заголовки с именами файлов.
lessless позволяет постранично просматривать текст (для выхода необходимо нажать q).
less <ФАЙЛ>grepgrep имеет много опций и предоставляет возможности поиска символьной строки в файле.
grep [шаблон_поиска] <ФАЙЛ>Поиск файлов
findfind предназначена для поиска всех файлов, начиная с корневого каталога. Поиск может осуществляться по имени, типу или владельцу файла.
find [-H] [-L] [-P] [-Oуровень] [-D help|tree|search|stat|rates|opt|exec] [ПУТЬ…] [ВЫРАЖЕНИЕ]-name — поиск по имени файла;
-type — поиск по типу f=файл, d=каталог, l=ссылка(lnk);
-user — поиск по владельцу (имя или UID).
find, можно выполнять различные действия над найденными файлами. Основные действия:
-exec команда \; — выполнить команду. Запись команды должна заканчиваться экранированной точкой с запятой. Строка «{}» заменяется текущим маршрутным именем файла;
execdir команда \; — то же самое что и -exec, но команда вызывается из подкаталога, содержащего текущий файл;
-ok команда — эквивалентно -exec за исключением того, что перед выполнением команды запрашивается подтверждение (в виде сгенерированной командной строки со знаком вопроса в конце) и она выполняется только при ответе: «y»;
-print — вывод имени файла на экран.
-print.
find . -type f -name "~*" -printfile.bak:
find . -newer file.bak -type f -printa.out или *.o, доступ к которым не производился в течение недели:
find / \( -name a.out -o -name '*.o' \) \ -atime +7 -exec rm {} \;find . -size 0c -ok rm {} \;whereiswhereis сообщает путь к исполняемому файлу программы, ее исходным файлам (если есть) и соответствующим страницам справочного руководства.
whereis [ОПЦИИ...] <ФАЙЛ>-b — вывод информации только об исполняемых файлах;
-m — вывод информации только о страницах справочного руководства;
-s — вывод информации только об исходных файлах.
Мониторинг и управление процессами
psps отображает список текущих процессов.
ps [ОПЦИИ...]-a — вывести информацию о процессах, ассоциированных с терминалами;
-f — вывести «полный» список;
-l — вывести «длинный» список;
-p список — вывести информацию о процессах с перечисленными в списке PID;
-u список — вывести информацию о процессах с перечисленными идентификаторами или именами пользователей.
killkill позволяет прекратить исполнение процесса или передать ему сигнал.
kill [-s] [сигнал] [идентификатор] [...]kill [-l] [статус_завершения]kill [-номер_сигнала] [идентификатор] [...]-l — вывести список поддерживаемых сигналов;
-s сигнал, -сигнал — послать сигнал с указанным именем.
kill не дает желательного эффекта, необходимо использовать команду kill с параметром -9 (kill -9 PID_номер).
dfdf показывает количество доступного дискового пространства в файловой системе, в которой содержится файл, переданный как аргумент. Если ни один файл не указан, показывается доступное место на всех смонтированных файловых системах. Размеры по умолчанию указаны в блоках по 1КБ.
df [ОПЦИИ] [ФАЙЛ...]--total — подсчитать общий объем в конце;
-h, --human-readable — печатать размеры в удобочитаемом формате (например, 1K, 234M, 2G).
dudu подсчитывает использование диска каждым файлом, для каталогов подсчет происходит рекурсивно.
du [ОПЦИИ] [ФАЙЛ...]-a, --all — выводить общую сумму для каждого заданного файла, а не только для каталогов;
-c, --total — подсчитать общий объем в конце. Может быть использовано для выяснения суммарного использования дискового пространства для всего списка заданных файлов;
-d, --max-depth=N — выводить объем для каталога (или файлов, если указано --all) только если она на N или менее уровней ниже аргументов командной строки;
-S, --separate-dirs — выдавать отдельно размер каждого каталога, не включая размеры подкаталогов;
-s, --summarize — отобразить только сумму для каждого аргумента.
whichwhich отображает полный путь к указанным командам или сценариям.
which [ОПЦИИ] <ФАЙЛ...>-a, --all — выводит все совпавшие исполняемые файлы по содержимому в переменной окружения $PATH, а не только первый из них;
-c, --total — подсчитать общий объем в конце. Может быть использовано для выяснения суммарного использования дискового пространства для всего списка заданных файлов;
-d, --max-depth=N — выводить объем для каталога (или файлов, если указано --all) только если она на N или менее уровней ниже аргументов командной строки;
-S, --separate-dirs — выдавать отдельно размер каждого каталога, не включая размеры подкаталогов;
--skip-dot — пропускает все каталоги из переменной окружения $PATH, которые начинаются с точки.
Использование многозадачности
bgbg позволяет перевести задание на задний план.
bg [ИДЕНТИФИКАТОР ...]fgfg позволяет перевести задание на передний план.
fg [ИДЕНТИФИКАТОР ...]Сжатие и упаковка файлов
tartar, которая преобразует файл или группу файлов в архив без сжатия (tarfile).
tar -cf [имя создаваемого файла архива] [упаковываемые файлы и/или каталоги]tar -cf moi_dokumenti.tar Docs project.textar -xf [имя файла архива]gzip, bzip2 и 7z.
cat. По умолчанию команда cat читает данные из всех файлов, которые указаны в командной строке, и посылает эту информацию непосредственно в стандартный вывод (stdout). Следовательно, команда:
cat history-final masters-thesishistory-final, а затем — файла masters-thesis.
cat читает входные данные из stdin и возвращает их в stdout. Пример:
cat
Hello there.
Hello there.
Bye.
Bye.
Ctrl-D
cat немедленно возвращает на экран. При вводе информации со стандартного ввода конец текста сигнализируется вводом специальной комбинации клавиш, как правило, Ctrl+D. Сокращённое название сигнала конца текста — EOT (end of text).
sort является простым фильтром — она сортирует входные данные и посылает результат на стандартный вывод. Совсем простым фильтром является команда cat — она ничего не делает с входными данными, а просто пересылает их на выход.
ls на stdin команды sort:
ls|sort-r notes masters-thesis history-final english-list
ls/usr/bin |more
где командаls|sort-r |head-1 notes
head -1 выводит на экран первую строку получаемого ей входного потока строк (в примере поток состоит из данных от команды ls), отсортированных в обратном алфавитном порядке.
ls > file-list
уничтожит содержимое файла file-list, если этот файл ранее существовал, и создаст на его месте новый файл. Если вместо этого перенаправление будет сделано с помощью символов >>, то вывод будет приписан в конец указанного файла, при этом исходное содержимое файла не будет уничтожено.
Примечание
chmod предназначена для изменения прав доступа файлов и каталогов.
chmod [ОПЦИИ] РЕЖИМ[,РЕЖИМ]... <ФАЙЛ>chmod [ОПЦИИ] --reference=ИФАЙЛ <ФАЙЛ>-R — рекурсивно изменять режим доступа к файлам, расположенным в указанных каталогах;
--reference=ИФАЙЛ — использовать режим файла ИФАЙЛ.
chmod изменяет права доступа каждого указанного файла в соответствии с правами доступа, указанными в параметре режим, который может быть представлен как в символьном виде, так и в виде восьмеричного, представляющего битовую маску новых прав доступа.
[ugoa...][[+-=][разрешения...]...]Здесь разрешения — это ноль или более букв из набора «rwxXst» или одна из букв из набора «ugo».
f1, а членам группы и прочим пользователям только читать. Команду можно записать двумя способами:
$chmod644 f1 $chmodu=rw,go=r f1
f2:
$ chmod +x f2
f3:
$ chmod +t f3
f4:
$chmod=rwx,g+s f4 $chmod2777 f4
chown изменяет владельца и/или группу для каждого заданного файла.
chown [КЛЮЧ]…[ВЛАДЕЛЕЦ][:[ГРУППА]] <ФАЙЛ>chown [ОПЦИИ] --reference=ИФАЙЛ <ФАЙЛ>-R — рекурсивно изменять файлы и каталоги;
--reference=ИФАЙЛ — использовать владельца и группу файла ИФАЙЛ.
/u на пользователя test:
chown test /u/u:
chown test:staff /u/u и вложенных файлов на test:
chown -hR test /uchgrp изменяет группу для каждого заданного файла.
chgrp [ОПЦИИ] ГРУППА <ФАЙЛ>chgrp [ОПЦИИ] --reference=ИФАЙЛ <ФАЙЛ>-R — рекурсивно изменять файлы и каталоги;
--reference=ИФАЙЛ — использовать группу файла ИФАЙЛ.
umask задает маску режима создания файла в текущей среде командного интерпретатора равной значению, задаваемому операндом режим. Эта маска влияет на начальное значение битов прав доступа всех создаваемых далее файлов.
umask [-p] [-S] [режим]
$ umask
0022
или то же самое в символьном режиме:
$ umask -S
u=rwx,g=rx,o=rx
umask распознается и выполняется командным интерпретатором bash.
chattr изменяет атрибуты файлов на файловых системах ext3, ext4.
chattr [ -RVf ] [+-=aAcCdDeFijmPsStTux] [ -v версия ] <ФАЙЛЫ> …-R — рекурсивно изменять атрибуты каталогов и их содержимого. Символические ссылки игнорируются;
-V — выводит расширенную информацию и версию программы;
-f — подавлять сообщения об ошибках;
-v версия — установить номер версии/генерации файла.
+-=aAcCdDeFijmPsStTux
a — только добавление к файлу;
A — не обновлять время последнего доступа (atime) к файлу;
c — сжатый файл;
C — отключение режима «Copy-on-write» для указанного файла;
d — не архивировать (отключает создание архивной копии файла командой dump);
D — синхронное обновление каталогов;
e — включает использование extent при выделении места на устройстве (атрибут не может быть отключён с помощью chattr);
F — регистронезависимый поиск в каталогах;
i — неизменяемый файл (файл защищен от изменений: не может быть удалён или переименован, к этому файлу не могут быть созданы ссылки, и никакие данные не могут быть записаны в этот файл);
j — ведение журнала данных (данные файла перед записью будут записаны в журнал ext3/ext4);
m — не сжимать;
P — каталог с вложенными файлами является иерархической структурой проекта;
s — безопасное удаление (перед удалением все содержимое файла полностью затирается «00»);
S — синхронное обновление (аналогичен опции монтирования «sync» файловой системы);
t — отключает метод tail-merging для файлов;
T — вершина иерархии каталогов;
u — неудаляемый (при удалении файла его содержимое сохраняется, это позволяет пользователю восстановить файл);
x — прямой доступ к файлам (атрибут не может быть установлен с помощью chattr).
lsattr выводит атрибуты файла расширенной файловой системы.
lsattr [ -RVadlpv ] <ФАЙЛЫ> …-R — рекурсивно изменять атрибуты каталогов и их содержимого. Символические ссылки игнорируются;
-V — выводит расширенную информацию и версию программы;
-a — просматривает все файлы в каталоге, включая скрытые файлы (имена которых начинаются с «.»);
-d — отображает каталоги также, как и файлы вместо того, чтобы просматривать их содержимое;
-l — отображает параметры, используя длинные имена вместо одного символа;
-p — выводит номер проекта файла;
-v — выводит номер версии/генерации файла.
getfacl выводит атрибуты файла расширенной файловой системы.
getfacl [ --aceEsRLPtpndvh ] <ФАЙЛ> …-a — вывести только ACL файла;
-d — вывести только ACL по умолчанию;
-c — не показывать заголовок (имя файла);
-e — показывать все эффективные права;
-E — не показывать эффективные права;
-s — пропускать файлы, имеющие только основные записи;
-R — для подкаталогов рекурсивно;
-L — следовать по символическим ссылкам, даже если они не указаны в командной строке;
-P — не следовать по символическим ссылкам, даже если они указаны в командной строке;
-t — использовать табулированный формат вывода;
-p — не удалять ведущие «/» из пути файла;
-n — показывать числовые значения пользователя/группы.
1: # file: somedir/ 2: # owner: lisa 3: # group: staff 4: # flags: -s- 5: user::rwx 6: user:joe:rwx #effective:r-x 7: group::rwx #effective:r-x 8: group:cool:r-x 9: mask:r-x 10: other:r-x 11: default:user::rwx 12: default:user:joe:rwx #effective:r-x 13: default:group::r-x 14: default:mask:r-x 15: default:oter:---
setfacl изменяет ACL к файлам или каталогам. В командной строке за последовательностью команд идет последовательность файлов (за которой, в свою очередь, также может идти последовательность команд и так далее).
setfacl [-bkndRLPvh] [{-m|-x} acl_spec] [{-M|-X} acl_file] <ФАЙЛ> …setfacl --restore=file-b — удалить все разрешенные записи ACL;
-k — удалить ACL по умолчанию;
-n — не пересчитывать маску эффективных прав, обычно setfacl пересчитывает маску (кроме случая явного задания маски) для того, чтобы включить ее в максимальный набор прав доступа элементов, на которые воздействует маска (для всех групп и отдельных пользователей);
-d — применить ACL по умолчанию;
-R — для подкаталогов рекурсивно;
-L — переходить по символическим ссылкам на каталоги (имеет смысл только в сочетании с -R);
-P — не переходить по символическим ссылкам на каталоги (имеет смысл только в сочетании с -R);
-L — следовать по символическим ссылкам, даже если они не указаны в командной строке;
-P — не следовать по символическим ссылкам, даже если они указаны в командной строке;
--mask — пересчитать маску эффективных прав;
-m — изменить текущий ACL для файла;
-M — прочитать записи ACL для модификации из файла;
-x — удалить записи из ACL файла;
-X — прочитать записи ACL для удаления из файла;
--restore=file — восстановить резервную копию прав доступа, созданную командой getfacl –R или ей подобной. Все права доступа дерева каталогов восстанавливаются, используя этот механизм. В случае если вводимые данные содержат элементы для владельца или группы-владельца, и команда setfacl выполняется пользователем с именем root, то владелец и группа-владелец всех файлов также восстанавливаются. Эта опция не может использоваться совместно с другими опциями за исключением опции --test;
--set=acl — установить ACL для файла, заменив текущий ACL;
--set-file=file — прочитать записи ACL для установления из файла;
--test — режим тестирования (ACL не изменяются).
--set, -m и -x должны быть перечислены записи ACL в командной строке. Элементы ACL разделяются одинарными кавычками.
-set-file, -M и -X команда setfacl принимает множество элементов в формате вывода команды getfacl. В строке обычно содержится не больше одного элемента ACL.
setfacl использует следующие форматы элементов ACL:
[d[efault]:] [u[ser]:]uid [:perms]
[d[efault]:] g[roup]:gid [:perms]
[d[efault]:] m[ask][:] [:perms]
[d[efault]:] o[ther][:] [:perms]
setfacl создает права доступа, используя уже существующие, согласно следующим условиям:
test.txt, принадлежащего пользователю liza и группе docs, так, чтобы:
$Установить разрешения (от пользователя liza):ls -l test.txt-rw-r-r-- 1 liza docs 8 янв 22 15:54 test.txt $getfacl test.txt# file: test.txt # owner: liza # group: docs user::rw- group::r-- other::r--
$Просмотреть разрешения (от пользователя liza):setfacl -m u:ivan:rw- test.txt$setfacl -m u:misha:--- test.txt
$ getfacl test.txt
# file: test.txt
# owner: liza
# group: docs
user::rw-
user:ivan:rw-
user:misha:---
group::r--
mask::rw-
other::r--
Примечание
ls -l указывает на использование ACL:
$ ls -l test.txt
-rw-rw-r--+ 1 liza docs 8 янв 22 15:54 test.txt
su (shell of user), которая позволяет выполнить одну или несколько команд от лица другого пользователя. По умолчанию эта утилита выполняет команду sh от пользователя root, то есть запускает командный интерпретатор. Отличие от предыдущего способа в том, что всегда известно, кто именно запускал su, а значит, ясно, кто выполнил определённое административное действие.
su, а утилиту sudo, которая позволяет выполнять только заранее заданные команды.
Важно
su и sudo, необходимо быть членом группы wheel. Пользователь, созданный при установке системы, по умолчанию уже включён в эту группу.
control доступна только для суперпользователя (root). Для того чтобы посмотреть, что означает та или иная политика control (разрешения выполнения конкретной команды, управляемой control), надо запустить команду с ключом help:
# control su help
Запустив control без параметров, можно увидеть полный список команд, управляемых командой (facilities) вместе с их текущим состоянием и набором допустимых состояний.
su -su без ключа, то происходит вызов командного интерпретатора с правами root. При этом значение переменных окружения, в частности $PATH, остаётся таким же, как у пользователя: в переменной $PATH не окажется каталогов /sbin, /usr/sbin, без указания полного имени будут недоступны команды route, shutdown, mkswap и другие. Более того, переменная $HOME будет указывать на каталог пользователя, все программы, запущенные в режиме суперпользователя, сохранят свои настройки с правами root в каталоге пользователя, что в дальнейшем может вызвать проблемы.
su -. В этом режиме su запустит командный интерпретатор в качестве login shell, и он будет вести себя в точности так, как если бы в системе зарегистрировался root.
id, вывод её может быть примерно следующим:
uid=500(test) gid=500(test) группы=500(test),16(rpm)
Примечание
useradd[ОПЦИИ...]<ИМЯ ПОЛЬЗОВАТЕЛЯ>useradd -D[ОПЦИИ...]
-b каталог — базовый каталог для домашнего каталога новой учётной записи;
-c комментарий — текстовая строка (обычно используется для указания фамилии и мени);
-d каталог — домашний каталог новой учётной записи;
-D — показать или изменить настройки по умолчанию для useradd;
-e дата — дата устаревания новой учётной записи;
-g группа — имя или ID первичной группы новой учётной записи;
-G группы — список дополнительных групп (через запятую) новой учётной записи;
-m — создать домашний каталог пользователя;
-M — не создавать домашний каталог пользователя;
-p пароль — зашифрованный пароль новой учётной записи (не рекомендуется);
-s оболочка — регистрационная оболочка новой учётной записи (по умолчанию /bin/bash);
-u UID — пользовательский ID новой учётной записи.
useradd имеет множество параметров, которые позволяют менять её поведение по умолчанию. Например, можно принудительно указать, какой будет UID или какой группе будет принадлежать пользователь:
# useradd -u 1500 -G usershares new_user
passwd и утилит shadow.
passwd [ОПЦИИ...] [ИМЯ ПОЛЬЗОВАТЕЛЯ]
-d, --delete — удалить пароль для указанной записи;
-f, --force — форсировать операцию;
-k, --keep-tokens — сохранить не устаревшие пароли;
-l, --lock — блокировать указанную запись;
--stdin — прочитать новые пароли из стандартного ввода;
-S, --status — дать отчет о статусе пароля в указанной записи;
-u, --unlock — разблокировать указанную запись;
-?, --help — показать справку и выйти;
--usage — дать короткую справку по использованию;
-V, --version — показать версию программы и выйти.
passwd заканчивает работу с кодом выхода 0. Код выхода 1 означает, что произошла ошибка. Текстовое описание ошибки выводится на стандартный поток ошибок.
useradd и passwd:
#useraddtest1 #passwdtest1 passwd: updating all authentication tokens for user test1. You can now choose the new password or passphrase. A valid password should be a mix of upper and lower case letters, digits, and other characters. You can use a password containing at least 7 characters from all of these classes, or a password containing at least 8 characters from just 3 of these 4 classes. An upper case letter that begins the password and a digit that ends it do not count towards the number of character classes used. A passphrase should be of at least 3 words, 11 to 72 characters long, and contain enough different characters. Alternatively, if no one else can see your terminal now, you can pick this as your password: "Burst*texas$Flow". Enter new password: Weak password: too short. Re-type new password: passwd: all authentication tokens updated successfully.
passwd — но если он попытается поставить слабый пароль, система откажет ему (в отличие от root) в изменении.
/etc/passwdqc.conf.
passwdqc.conf состоит из 0 или более строк следующего формата:
опция=значениеПустые строки и строки, начинающиеся со знака решетка («#»), игнорируются. Символы пробела между опцией и значением не допускаются.
min=N0,N1,N2,N3,N4 (min=disabled,24,11,8,7) — минимально допустимая длина пароля.
Примечание
max=N (max=40) — максимально допустимая длина пароля. Эта опция может быть использована для того, чтобы запретить пользователям устанавливать пароли, которые могут быть слишком длинными для некоторых системных служб. Значение 8 обрабатывается особым образом: пароли длиннее 8 символов, не отклоняются, а обрезаются до 8 символов для проверки надежности (пользователь при этом предупреждается).
passphrase=N (passphrase=3) — число слов, необходимых для ключевой фразы (значение 0 отключает поддержку парольных фраз).
match=N (match=4) — длина общей подстроки, необходимой для вывода, что пароль хотя бы частично основан на информации, найденной в символьной строке (значение 0 отключает поиск подстроки). Если найдена слабая подстрока пароль не будет отклонен; вместо этого он будет подвергаться обычным требованиям к прочности при удалении слабой подстроки. Поиск подстроки нечувствителен к регистру и может обнаружить и удалить общую подстроку, написанную в обратном направлении.
similar=permit|deny (similar=deny) — параметр similar=permit разрешает задать новый пароль, если он похож на старый (параметр similar=deny — запрещает). Пароли считаются похожими, если есть достаточно длинная общая подстрока, и при этом новый пароль с частично удаленной подстрокой будет слабым.
random=N[,only] (random=42) — размер случайно сгенерированных парольных фраз в битах (от 26 до 81) или 0, чтобы отключить эту функцию. Любая парольная фраза, которая содержит предложенную случайно сгенерированную строку, будет разрешена вне зависимости от других возможных ограничений. Значение only используется для запрета выбранных пользователем паролей.
enforce=none|users|everyone (enforce=users) — параметр enforce=users задает ограничение задания паролей в passwd на пользователей без полномочий root. Параметр enforce=everyone задает ограничение задания паролей в passwd и на пользователей, и на суперпользователя root. При значении none модуль PAM будет только предупреждать о слабых паролях.
retry=N (retry=3) — количество запросов нового пароля, если пользователь с первого раза не сможет ввести достаточно надежный пароль и повторить его ввод.
/etc/passwdqc.conf:
min=8,7,4,4,4 enforce=everyoneВ указанном примере пользователям, включая суперпользователя root, будет невозможно задать пароли:
chage.
Примечание
# apt-get install shadow-change
chage изменяет количество дней между сменой пароля и датой последнего изменения пароля.
chage [опции] логин
-d, --lastday LAST_DAY — установить последний день смены пароля в LAST_DAY на день (число дней с 1 января 1970). Дата также может быть указана в формате ГГГГ-ММ-ДД;
-E, -expiredate EXPIRE_DAYS — установить дату окончания действия учётной записи в EXPIRE_DAYS (число дней с 1 января 1970) Дата также может быть указана в формате ГГГГ-ММ-ДД. Значение -1 удаляет дату окончания действия учётной записи;
-I, --inactive INACTIVE — используется для задания количества дней «неактивности», то есть дней, когда пользователь вообще не входил в систему, после которых его учетная запись будет заблокирована. Пользователь, чья учетная запись заблокирована, должен обратиться к системному администратору, прежде чем снова сможет использовать систему. Значение -1 отключает этот режим;
-l, --list — просмотр информации о «возрасте» учётной записи пользователя;
-m, --mindays MIN_DAYS — установить минимальное число дней перед сменой пароля. Значение 0 в этом поле обозначает, что пользователь может изменять свой пароль, когда угодно;
-M, --maxdays MAX_DAYS — установить максимальное число дней перед сменой пароля. Когда сумма MAX_DAYS и LAST_DAY меньше, чем текущий день, у пользователя будет запрошен новый пароль до начала работы в системе. Эта операция может предваряться предупреждением (параметр -W). При установке значения -1, проверка действительности пароля не будет выполняться;
-W, --warndays WARN_DAYS — установить число дней до истечения срока действия пароля, начиная с которых пользователю будет выдаваться предупреждение о необходимости смены пароля.
# chage -M 5 test
# chage -l test
Последний раз пароль был изменён : дек 27, 2023
Срок действия пароля истекает : янв 01, 2024
Пароль будет деактивирован через : янв 11, 2024
Срок действия учётной записи истекает : никогда
Минимальное количество дней между сменой пароля : -1
Максимальное количество дней между сменой пароля : 5
Количество дней с предупреждением перед деактивацией пароля : -1
Примечание
PASS_MAX_DAYS в файле /etc/login.defs.
Предупреждение
Предупреждение
/etc/security/opasswd, в который пользователи должны иметь доступ на чтение и запись. При этом они могут читать хэши паролей остальных пользователей. Не рекомендуется использовать на многопользовательских системах.
/etc/security/opasswd и дайте права на запись пользователям:
#install -Dm0660 -gpw_users /dev/null /etc/security/opasswd#chgrp pw_users /etc/security#chmod g+w /etc/security
/etc/pam.d/system-auth-local-only таким образом, чтобы он включал модуль pam_pwhistory после первого появления строки с паролем:
password required pam_passwdqc.so config=/etc/passwdqc.conf password required pam_pwhistory.so debug use_authtok remember=10 retry=3
/etc/security/opasswd будут храниться последние 10 паролей пользователя (содержит хэши паролей всех учетных записей пользователей) и при попытке использования пароля из этого списка будет выведена ошибка:
Password has been already used. Choose another.
enforce_for_root:
password required pam_pwhistory.so use_authtok enforce_for_root remember=10 retry=3
usermod:
# usermod -G audio,rpm,test1 test1
# usermod -l test2 test1
usermod -L test2 и usermod -U test2 соответственно временно блокируют возможность входа в систему пользователю test2 и возвращают всё на свои места.
chpasswd. На стандартный вход ей следует подавать список, каждая строка которого будет выглядеть как имя:пароль.
userdel.
userdel test2 удалит пользователя test2 из системы. Если будет дополнительно задан параметр -r, то будет уничтожен и домашний каталог пользователя. Нельзя удалить пользователя, если в данный момент он еще работает в системе.
pstree.
/etc/inittab, откуда вызываются другие программы и скрипты на определенном этапе запуска.
service и chkconfig продолжат работать в мире systemd практически без изменений. Тем не менее, в этой таблице показано как выполнить те же действия с помощью встроенных утилит systemctl.
Таблица 86.1. Команды управления службами
|
Команды Sysvinit
|
Команды Systemd
|
Примечания
|
|---|---|---|
|
service frobozz start
|
systemctl start frobozz.service
|
Используется для запуска службы (не перезагружает постоянные)
|
|
service frobozz stop
|
systemctl stop frobozz.service
|
Используется для остановки службы (не перезагружает постоянные)
|
|
service frobozz restart
|
systemctl restart frobozz.service
|
Используется для остановки и последующего запуска службы
|
|
service frobozz reload
|
systemctl reload frobozz.service
|
Если поддерживается, перезагружает файлы конфигурации без прерывания незаконченных операций
|
|
service frobozz condrestart
|
systemctl condrestart frobozz.service
|
Перезапускает службу, если она уже работает
|
|
service frobozz status
|
systemctl status frobozz.service
|
Сообщает, запущена ли уже служба
|
|
ls /etc/rc.d/init.d/
|
systemctl list-unit-files --type=service (preferred)
ls /lib/systemd/system/*.service /etc/systemd/system/*.service
|
Используется для отображения списка служб, которые можно запустить или остановить.
Используется для отображения списка всех служб.
|
|
chkconfig frobozz on
|
systemctl enable frobozz.service
|
Включает службу во время следующей перезагрузки, или любой другой триггер
|
|
chkconfig frobozz off
|
systemctl disable frobozz.service
|
Выключает службу во время следующей перезагрузки, или любой другой триггер
|
|
chkconfig frobozz
|
systemctl is-enabled frobozz.service
|
Используется для проверки, сконфигурирована ли служба для запуска в текущем окружении
|
|
chkconfig --list
|
systemctl list-unit-files --type=service(preferred)
ls /etc/systemd/system/*.wants/
|
Выводит таблицу служб. В ней видно, на каких уровнях загрузки они (не)запускаются
|
|
chkconfig frobozz --list
|
ls /etc/systemd/system/*.wants/frobozz.service
|
Используется, для отображения на каких уровнях служба (не)запускается
|
|
chkconfig frobozz --add
|
systemctl daemon-reload
|
Используется, когда вы создаете новую службу или модифицируете любую конфигурацию
|
journalctl. По умолчанию, больше не требуется запуск службы syslog.
journalctl с разными ключами:
journalctl -b — покажет сообщения только с текущей загрузки;
journalctl -f — покажет только последние сообщения.
journalctl _PID=1 — покажет сообщения первого процесса (init).
journalctl. Для этого используйте команду man journalctl.
man (сокращение от manual). Каждая страница руководства посвящена одному объекту системы. Для того чтобы прочесть страницу руководства по программе, необходимо набрать man название_программы. К примеру, если вы хотите узнать, какие опции есть у команды date, вы можете ввести команду:
$mandate
man осуществляется командой apropos. Если вы точно не знаете, как называется необходимая вам программа, то поиск осуществляется по ключевому слову, к примеру, apropos date или при помощи ввода слова, обозначающего нужное действие, после команды man -k (например, man -k copy). Слово, характеризующее желаемое для вас действие, можно вводить и на русском языке. При наличии русского перевода страниц руководства man результаты поиска будут выведены на запрашиваемом языке.
man запускает программу постраничного просмотра текстов. Страницы перелистывают пробелом, для выхода из режима чтения описания команд man необходимо нажать на клавиатуре q. Команда man man выдаёт справку по пользованию самой командой man.
man по умолчанию будет отображать их на русском языке.
info info. Команда info, введённая без параметров, предлагает пользователю список всех документов info, установленных в системе.
/usr/share/doc — место хранения разнообразной документации.
/usr/share/doc/имя_пакета. Например, документация к пакету file-5.44 находится в /usr/share/doc/file-5.44. Для получения полного списка файлов документации, относящихся к пакету, воспользуйтесь командой rpm -qd имя_установленного_пакета.
README, FAQ, TODO, СhangeLog и другие. В файле README содержится основная информация о программе — имя и контактные данные авторов, назначение, полезные советы и пр. FAQ содержит ответы на часто задаваемые вопросы; этот файл стоит прочитать в первую очередь, если у вас возникли проблемы или вопросы по использованию программы, поскольку большинство проблем и сложностей типичны, вполне вероятно, что в FAQ вы тут же найдёте готовое решение. В файле TODO записаны планы разработчиков на реализацию той или иной функциональности. В файле СhangeLog записана история изменений в программе от версии к версии.
rpm -qi имя_установленного_пакета. В информационном заголовке соответствующего пакета, среди прочей информации, будет выведена искомая ссылка.